There are many new machine-learning-based services that are being developed with the increased interest in machine learning and a need for technologies that better fit our contact-free daily lives post COVID-19. There are many stages other than training in delivering a machine learned model into the hands of the end user. In the data processing stage we collect, modify, and record data. In the serving stage, we take the trained model and optimize, deploy, and operate it for service.
CLOps is a platform that handles the third step: serving. In this series of posts, I'd like to share our thought process and challenges we had to overcome to develop a platform that can provide an automated and stable service platform.
Problems with existing systems

When working with existing systems, we've divided the model development to service process into a modeling stage and service launch stage, with a modeler and machine learning engineer being responsible for each respectively. Compartmentalizing like this makes the boundaries clearer and make the entire process much simpler. However, as more fields began to incorporate machine learning and technologies became more advanced, the life cycle of model development to actual service became shorter and brought about many problems with it.
Problem 1: Slower development due to differing perspectives of each role
Modelers and machine learning engineers have different perspectives. It's because both have their own individual goals. A modeler's job is to improve the performance of a model, and a machine learning engineer's job is to improve the model's inference speed. Unfortunately, a model's performance and its inference speed are inversely proportional to each other. This raises communication costs between the two development roles, which lead to a longer and slower service transition process. As you can imagine, a longer and slower process from conception to service is an obstacle you want to avoid.
Problem 2: Increasing maintenance costs as time goes by
Even after you launch your service, you need to keep training your model with real-time data and evaluate its performance. This is because an endlessly increasing and fluctuating stream of data can potentially diminish the performance of your model. However, as I've mentioned in "Problem 1", increased communication costs made the cycle of continuous training and deployment difficult. Modelers also had to employ the help of machine learning engineers whenever they were done analyzing data that they wanted to train the model with.
Problem 3: Fragmentation of models caused by individual serving
As the teams in charge of service planning and teams in charge of service launching began to work independently, the methods of model management and infrastructure composition became varied, and computing resources became fragmented as well. This meant several things. First, it made transferring and maintaining models difficult when there was a change in the person in charge. Second, it made the infrastructure more varied, requiring operation tasks to be performed more than once. Lastly, the computing resource changes that follow model traffic was more difficult to predict, and those resources were becoming fragmented more often.
Problem 4: Difficulty maintaining model and model parameter configurations
In order to serve a model, you need a model (source code) and model parameters (training data). In machine learning, a repository for metadata and model parameters earned from model research and experimentation is required not only for training, but in order to stably deploy the model as well. These repositories are generally called model registries. The problem with these model registries is that some are managed by individuals, and those that aren't are often not standardized for general use. This made it difficult to find and manage deployed configurations.
Our goal then, was to compensate for these shortcomings by automating and minimizing the overlapping tasks performed by machine learning engineers who were in charge of serving models. Furthermore, we focused on making a system that can be efficiently managed by preventing the fragmentation of computing resources and providing modelers with an environment where they can quickly and continuously test and improved models from the model research stage all the way to the serving stage. CLOps began with these goals in mind.
Main elements of model serving
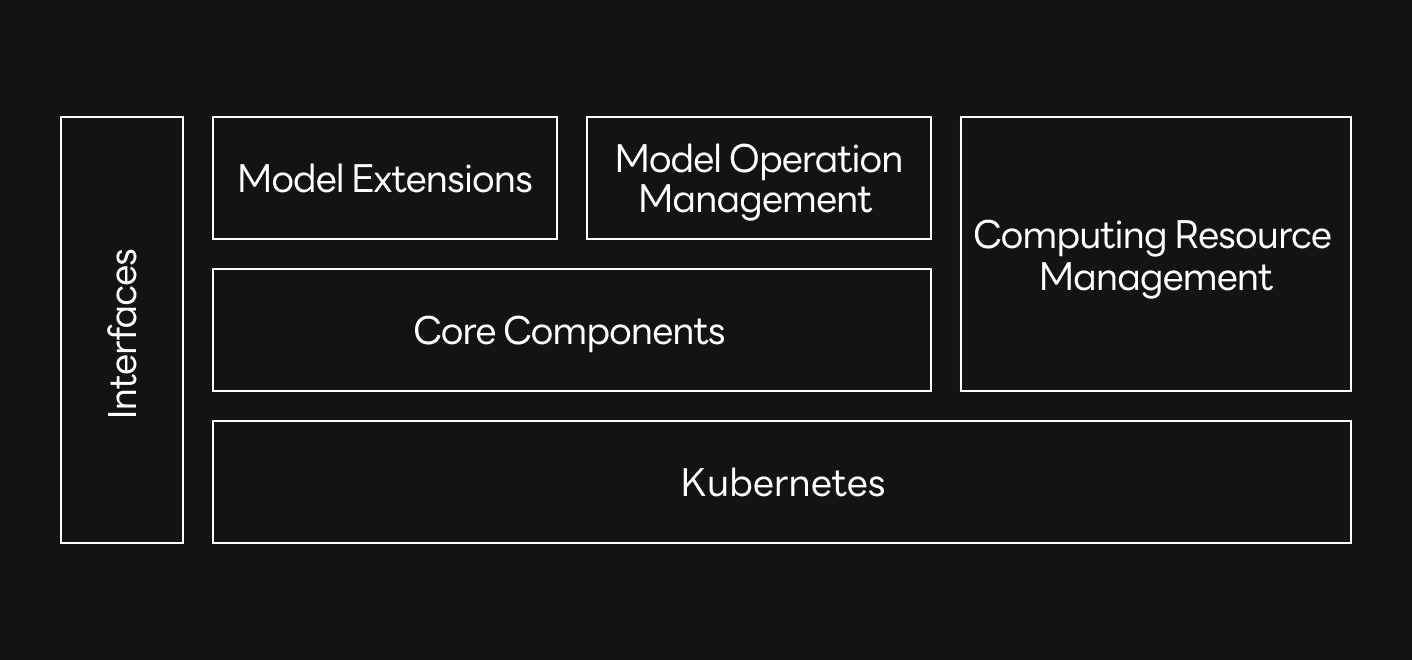
Before we began development, we focused on what elements there were in model serving, how to prioritize each element, and how to automate the system so that we could solve the problems of previous systems. Based on our experiences gained from serving many models, we've divided the elements required for model serving into the following five categories.
- Core components for automated extension and deployment control of various functionalities without changing code
- A more efficient allocation and retrieval method of computing resource management
- Model extensions such as model registries, various methods of serving, and model A/B tests
- Model operation management for more sustainable and stable operation
- Interfaces that provide conveniences for using the platform more easily
I will go into the details of each category listed above in the next post. In this post, let's focus on the environment, technology stack, and architecture behind CLOps.
The beginning of CLOps
CLOps is a portmanteau of CLOVA and MLOps, which we chose because our aim was to develop a MLOps serving platform that can standardize and automate model serving methods. In truth, there are already several open-source projects with similar goals to that of CLOps such as Seldon or Kubeflow. We chose instead to develop our own project because we wanted something that could be customized to our own needs, and especially the needs of our modelers. We wanted a project that we could quickly gather feedback and update accordingly. To achieve this, we first analyzed the problems of existing systems and then defined the main elements required for automating model serving. Based on our findings, we chose the platform environment, technology stack, and designed our architecture.
Choosing a platform distribution environment and technology stack
Below are some considerations we had when choosing a platform distribution environment.
- Ease of using feature expansions for automation and solving problems of existing systems
- Easy for modelers to understand and use
- Support for abstraction of computing resource scheduling
- Stability and recoverability
To summarize, we needed an environment with scalability, easy deployment and scheduling, and stable operation. Infrastructures like Kubernetes and Hadoop already satisfy these criteria. The reason we went with Kubernetes was because we saw more value in Kubernetes Operator. Kubernetes Operator lets us customize and extend functionality with ease. Kubernetes was the only infrastructure that provided the necessary environment, while also allowing us to easily extend functionality.
Choosing Kubernetes meant that our programming language of choice had to be Go as it made Kubernetes extension development easier. Go is a compiled programming language with easy-to-read code, and it's also responsible for the high performance of Kubernetes. Another advantage was the fact that an active community and extensive documentation on using Go for Kubernetes extensions already exist, leading to a unanimous vote to use Go.
Architecture
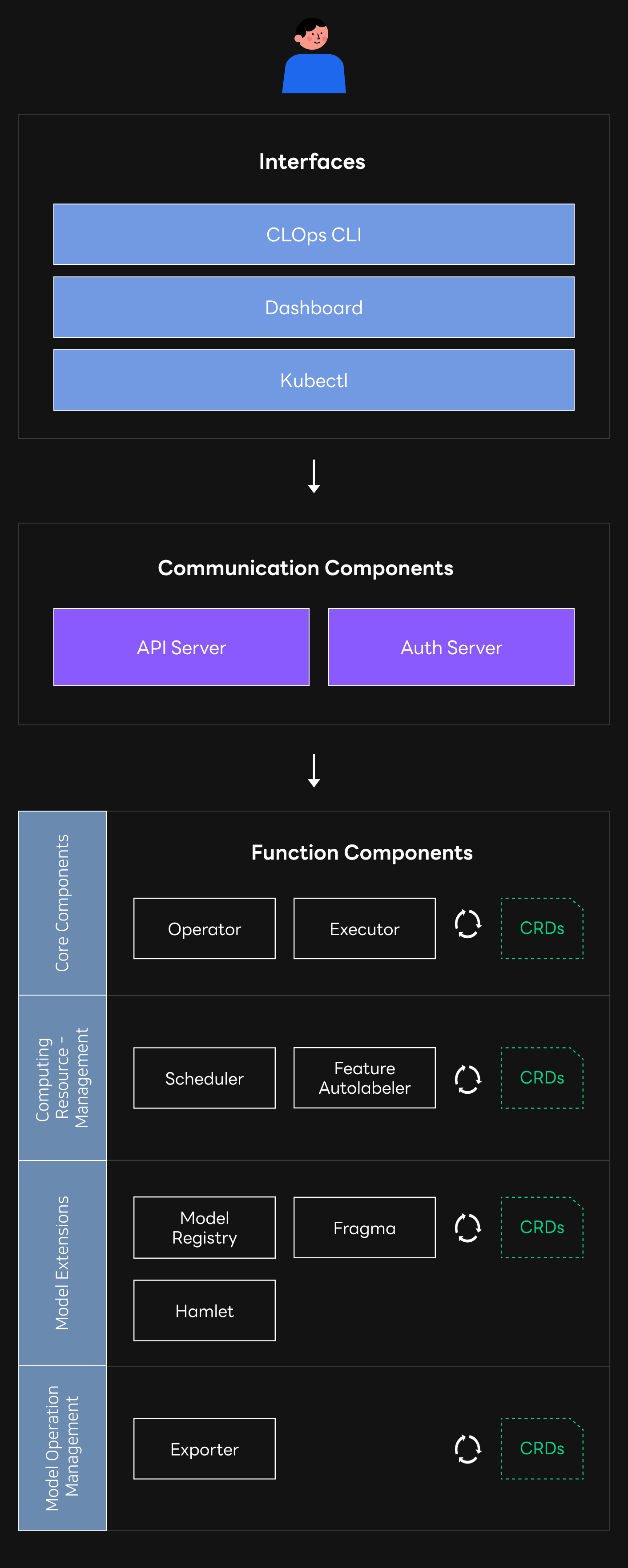
We thought that all modelers should be able to have the same experience while using an interface that suits each of their own needs. That's why we designed CLOps to work with a singular API server with per-user authentication and permissions. We also made sure to allow most functionality extensions to be automated with Kubernetes custom resources. With our architecture, we were able to provide an identical environment anywhere as long as you were using Kubernetes.
This is the beginning of our CLOps platform development journey.
In this post, we looked at the problems we had with existing systems, why we began development on CLOps, and what the main elements of model serving are. We also looked at how we decided the environment, technology stacks, and architecture behind our environment where we will be distributing our new platform. In the following posts in this series, I will let you in on what our concerns during development were, and what challenges we had to overcome. If you're interested, please stay tuned for future updates.