Introduction: Internalizing distributed training
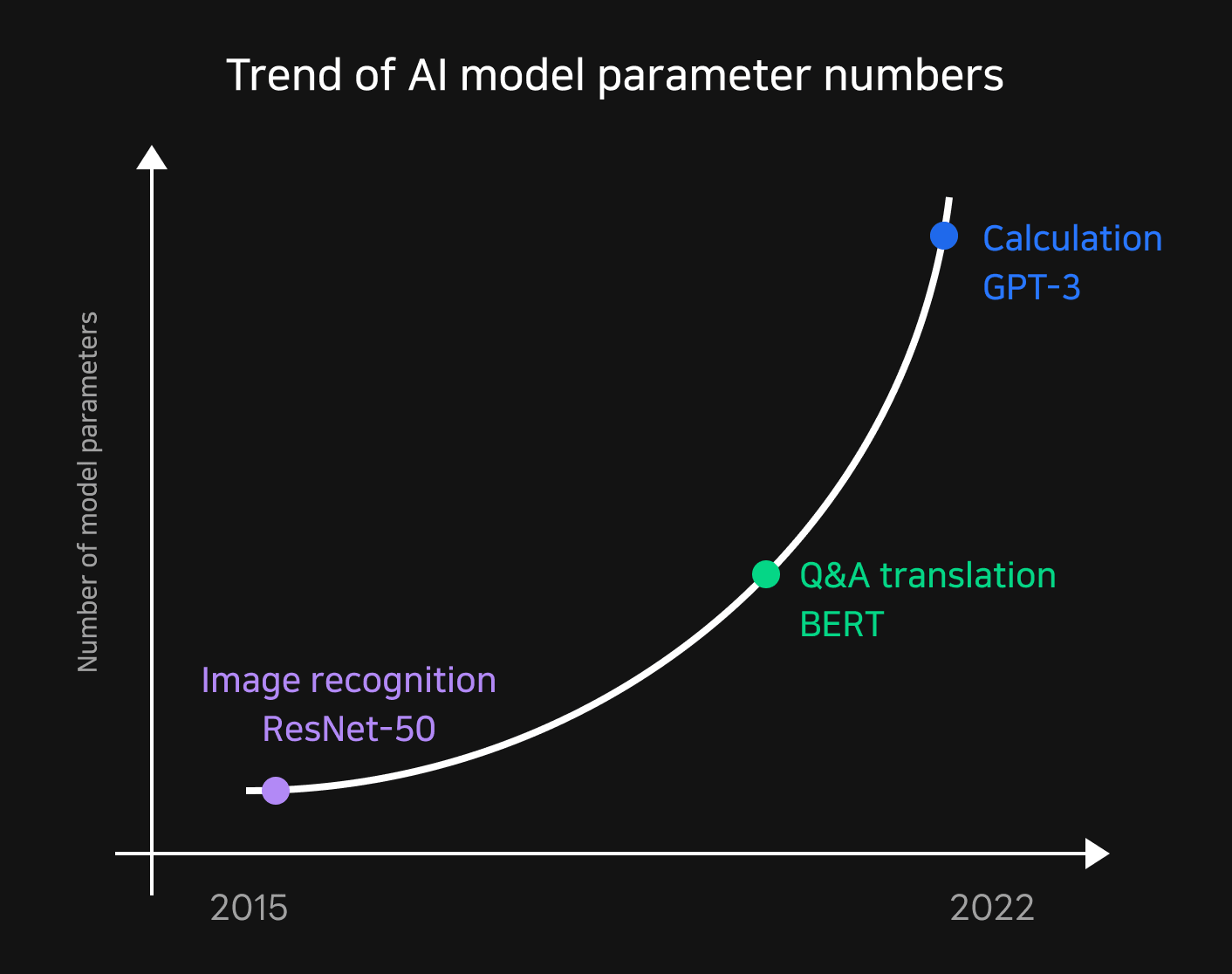
Deep learning training is evolving by using larger and more complex datasets and models to find answers to more various problems. GPT-3 made its mark in 2020 by increasing the number of parameters to 185B, which was 18 times of the then two-year-old BERT. The latest research trends in academia show a noticeably sharp increase in model complexity.
In order to answer to these trends and apply better performing models to your service, you need to be able to train more complex and larger models. The problem is that models and datasets have grown to a size where an eight-GPU server is no longer sufficient to handle their training. To overcome this obstacle, a training method known as "multi-node distributed training" was developed.
Distributed training enables large-scale training and improves its speed by putting models and data in parallel. There are two main types of distributed training: data parallelism and model parallelism. More specifically there is pipeline parallelism, which divides data into micro-batches to reduce idle time; 3D parallelization, which combines several techniques; and ZeRO (Zero Redundancy Optimizer), which partitions and trains the internal states of the model.
Considerations for a good distributed training platform
NSML (NAVER Smart Machine Learning) is a machine learning platform that allows users to customize their training environments and aggregate results so that researchers can "solely focus on developing models and derive insight". The plan behind NSML was to follow current trends by providing a service optimized for distributed training while also being a training platform that meets the needs of researchers. Our two main considerations were as follows.
First, prepare a secure infrastructure and scheduling system that can handle large-scale training and fairly allocate resources to the users.
Distributed training needs more than a lot of GPUs. In order for distributed training to play its role, collective communication that organically sums up and redistributes the results trained by GPUs is required as well. NSML was designed with a good infrastructure to address communication bottlenecks and an efficient scheduling method with appropriate resource allocation to reduce idle resources as much as possible.
Second, come up with a design that can plan and post large-scale training while easily debugging experiment results.
The design of NSML began from creating an ML platform that can help researchers perform modeling. Based on the researchers' general training flow, the user will initially establish a mental model with a small personal experiment, and then perform tuning to find good parameters with a large iterative experiment. The problem is that personal experiments require an environment that is easy to debug and has high degrees of freedom, while large-scale training requires a workflow that allows you to plan large-scale training for repetition and tuning rather than freedom. It's necessary to find a way to connect these two steps naturally, and to have a visualization configuration that could bring distributed training results together to form insights for future use.
NSML's components
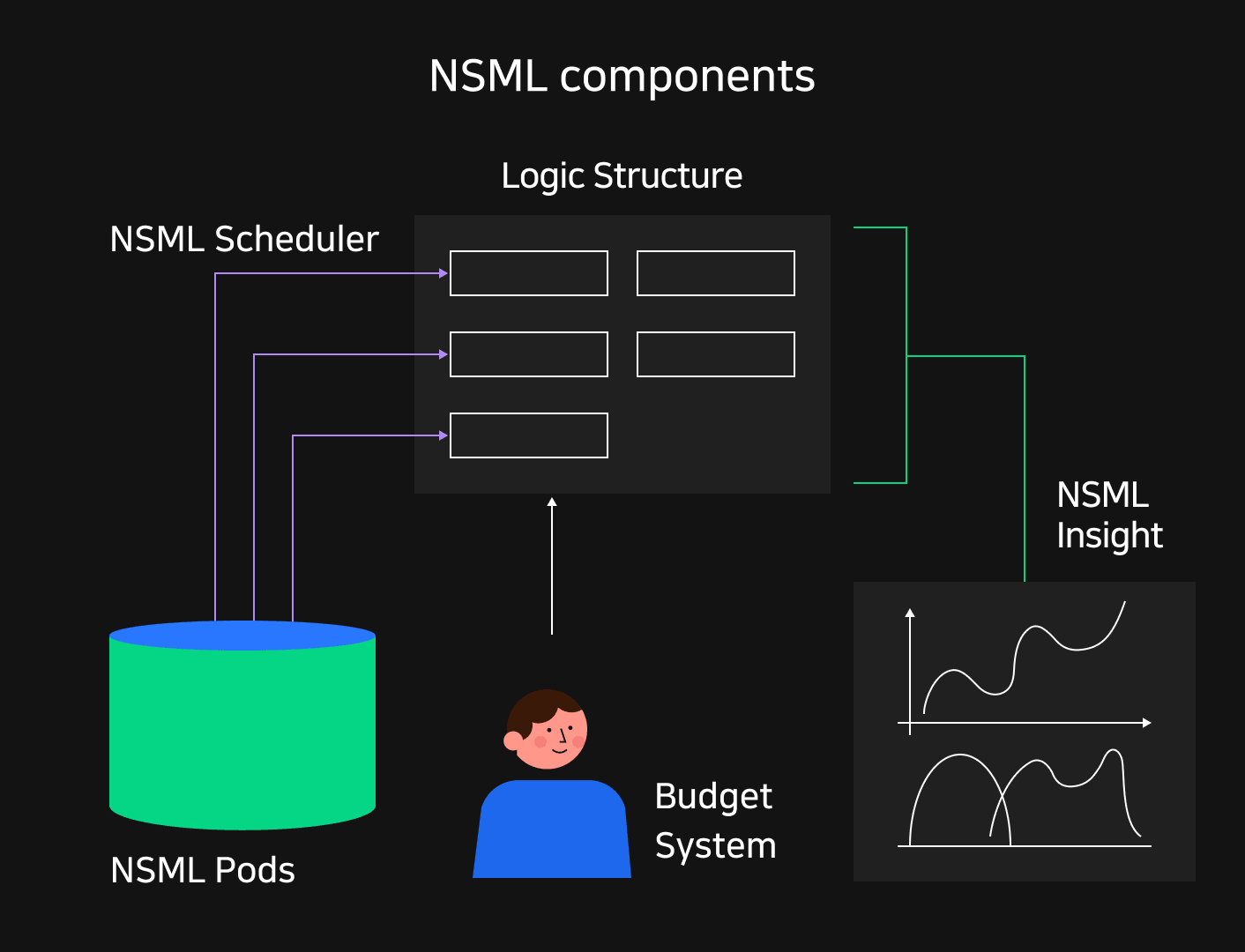
Designed with these concerns, NSML has the following key components. Keeping the following topics in mind will give you a deeper understanding for the further posts in this series about NSML.
NSML Pods: Building an infrastructure for distributed training
NSML Pods were optimized to cover model training up to 128 GPUs. GPUs within NSML Pods are bundled with InfiniBand, a high-speed network specialized for multi-node communication, enabling fast interaction. Each pod is equipped with high-performance DDN storage, so they can communicate directly with GPUs.
NSML's logical components: A design that can cover various training types
The NSML team identified two types of training patterns amongst researchers. The first was small personal training that requires debugging and freedom, and the second was large-scale training that allows you to post tuning and repetitive tasks. To be all-inclusive, NSML manages training results by a three-layer hierarchy of Project-Run-Node based on a common training project. Nodes can have SSH connections in the smallest units, so they can be debugged locally. Users can freely modify models by creating small experiments with a single node. After the mental model is established, you can schedule training by planning experiments for repetitive tuning tasks.
NSML Scheduler: Scheduling for efficient resource use
Training is always done with limited resources, so resources must be distributed according to user requests. To this end, the NSML scheduler increased resource utilization by minimizing the amount of unintended idle resources. It also prevents fragmentation of resources so that experiments of different sizes can be deployed without issues. With distributed training in mind, we designed efficient scheduling where nodes in the same experiment can be deployed simultaneously.
NSML Insight: Visualizing training results for insight
When users record experiment results as metrics, NSML recognizes them and automatically visualizes them in the form of tables or graphs. The results from distributed training nodes are collected and reconstructed to form insights. At the same time, the usage of resources including the GPU is recorded, so you can identify GPU utilization and power consumption to diagnose whether training was performed efficiently.
NSML budget system: Budgeting for fair resource allocation
NSML guarantees that everyone is at least free to run their own small personal experiments. At the same time, the budget system was set up so that project managers can properly distribute large experimental resources to their members. In particular, we introduced experimental time-outs and automatic re-runs to ensure that large-scale resources are distributed as fairly as possible.
The role of NSML Pods
Support for various scales of distributed training
In order to smoothly carry out research on deep learning training, infrastructure of sufficient performance is required.
To train its hyperscale language model HyperCLOVA, CLOVA uses a modular NVIDIA DGX SuperPOD that is composed of 20 DGX A100 system groups. SuperPOD is a hardware configuration that specializes in hyperscale training, and its performance is actually quite excessive for the purposes of handling the smaller experiments of CLOVA. NSML eventually had to be configured with proprietary deep learning clusters that are tuned to more general research needs.
NSML Pods is a grouping of research clusters that use dozens of A100 hosts. Each Pod can be used for large-scale or small to medium scale distributed training experiments using up to 128 GPUs for training.
Solving network bottlenecks
A single GPU is sufficient for training smaller models and data. In this case, you won't have to worry about communication costs since all computations are handled within a single GPU. However, for multi-GPU training that requires more than one GPU, you need to share the training results between GPUs.
Since distributed training computation is performed in parallel, it's essential to aggregate the different training results of each server. In fact, distributed training often reduces the total training time by loading data into the GPU and summing the results from each GPU rather than the amount of time the GPU is utilized for computation. When this is scaled up to hundreds of GPUs, it becomes necessary to eliminate network bottlenecks between GPUs and between GPU servers as much as possible.
When computers and peripherals send and receive data, they typically use a representative interface called PCIe (PCI Express). In general, all data from PCIe-based multi-GPU training is synchronized through the CPU from each I/O that occurs between GPUs. Because of this, there is a risk of bottlenecks occurring at each stage when a lot of data goes from a GPU to the CPU's RAM, cache, page, and so on.
In addition, if CPU performance is not sufficient, it's difficult to input and output data to and from the GPU. For example, GPUs usually support x16 lanes, allowing two-way communication with the CPU, but if the CPU does not support enough PCI lanes, some connected GPUs will operate as x8. Because of this inefficiency in data communication, direct communication between GPUs that doesn't involve the CPU or system memory is necessary.
What is RDMA communication?
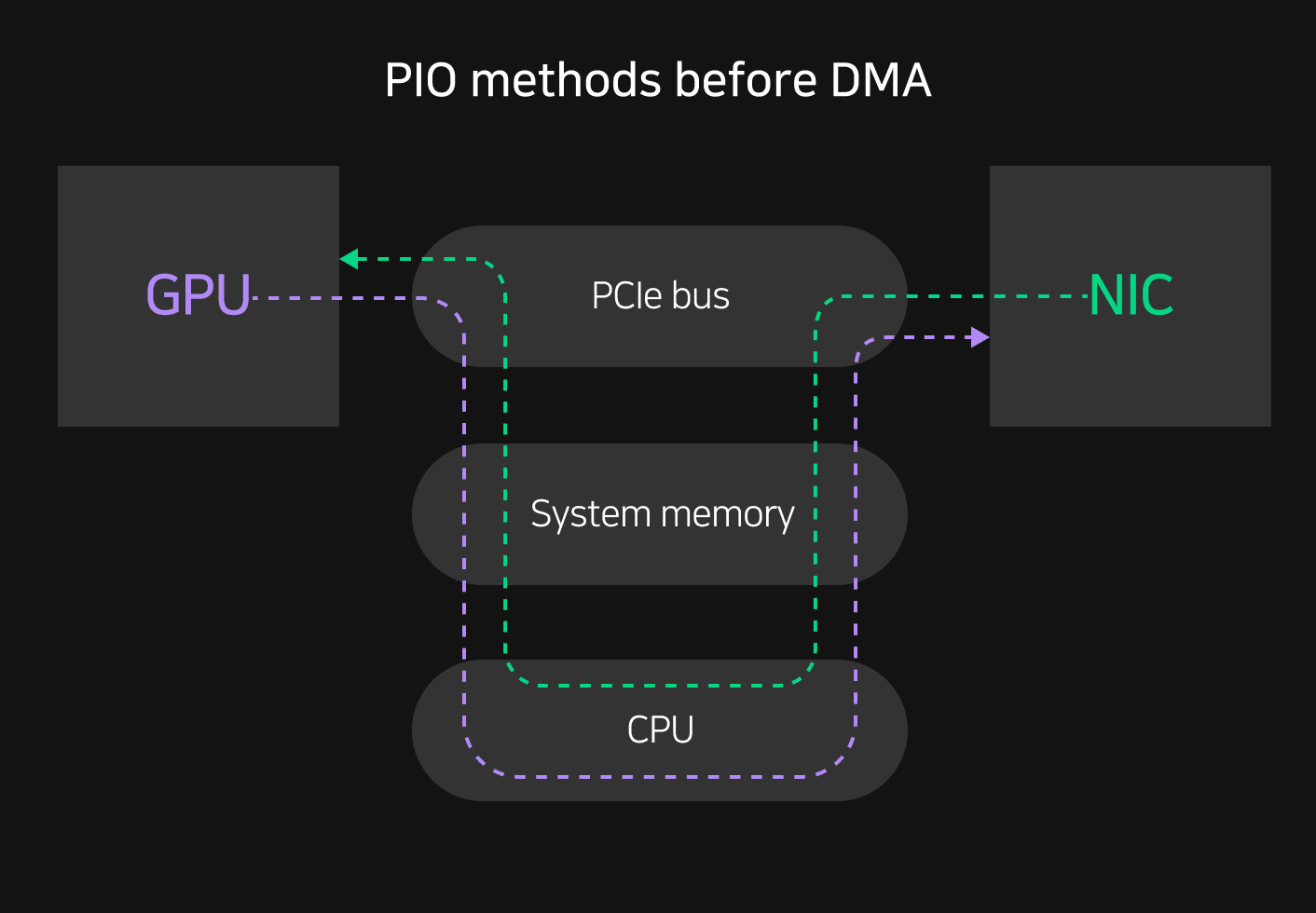
Traditional PIO (Programmed Input/Output) methods require data transfer between devices through the CPU. However, DMA (Direct Memory Access) enables direct communication between the GPU and the I/O card without going through the CPU. DMA is a feature supported by the server's internal bus, and usually a portion of memory is used for DMA, allowing the CPU to perform other tasks while data is directly transferred. In other words, DMA allows the CPU to transmit data in the middle and not directly control the flow of input/output devices, which reduces the load on data transmission and reception, improving system performance.

If DMA deals with memory access within a server, RDMA (Remote Direct Memory Access) is a technology that allows for direct data transfer between servers. RDMA is a network technology that sends and receives data directly to memory without going through the OS of a remote server. Because it does not go through a CPU like DMA, it can achieve fast processing speeds and minimal network latency as well as low CPU utilization.
Adopting InfiniBand
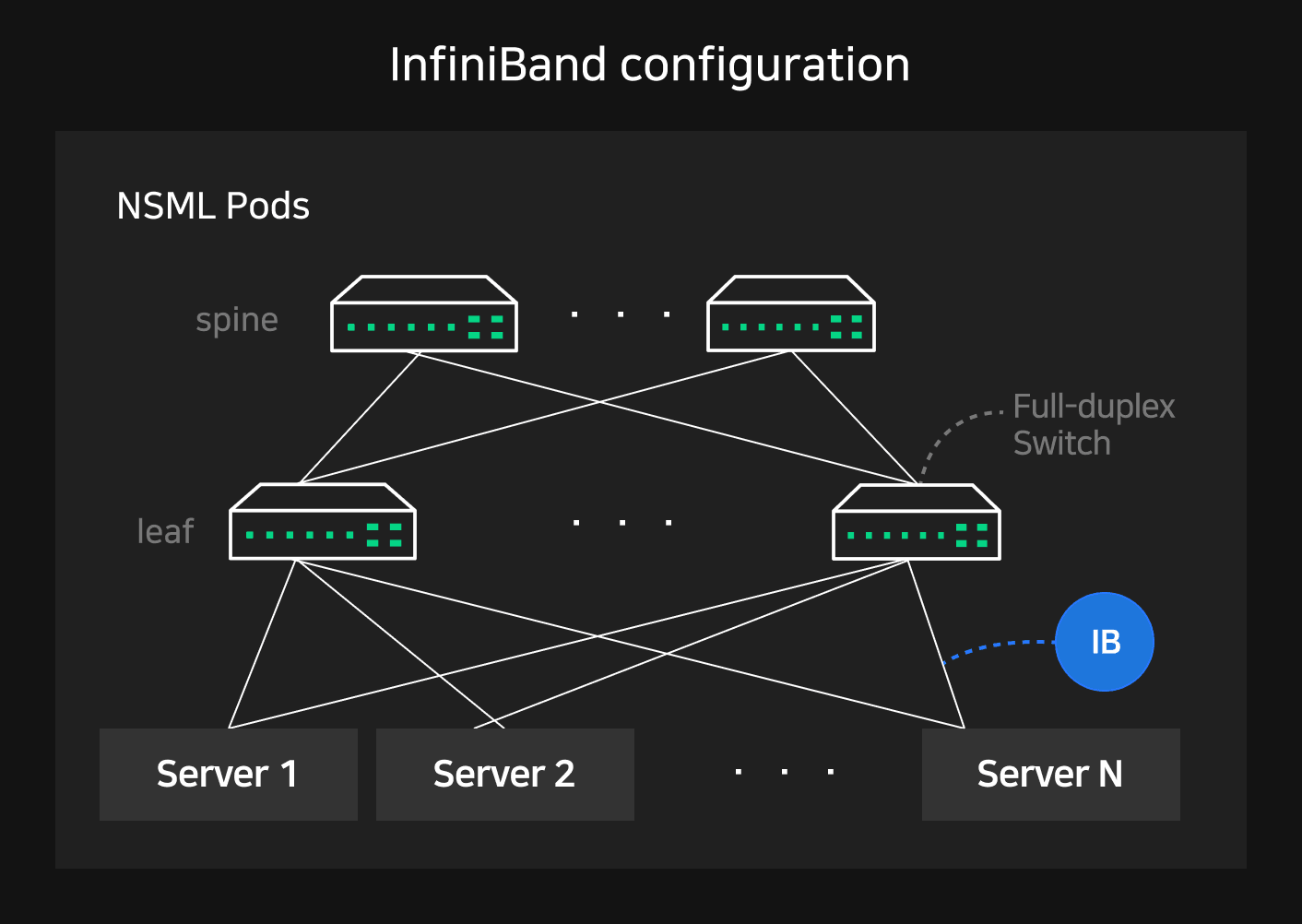
Mellanox's InfiniBand is one of the major RDMA-based high-performance networks, other options include RoCE (RDMA over Converged Ethernet) and iWARP (Internet Wide Area RDMA Protocol). NSML's deep learning cluster was built using InfiniBand.
All NSML Pod servers are equipped with a high-speed network card HCA (Host Channel Adapter). GPU communication within servers use NVLink, and GPU communication between servers in a Pod use InfiniBand.
InfiniBand can use the RDMA READ function that reads data directly from a remote node or the RDMA WRITE function that records data by specifying a memory address. In particular, data can be sent and received directly from the InfiniBand HCA to the GPU based on NVIDIA's Kepler architecture (2012) and GPUDirect RDMA technology available since CUDA 5.0.
In addition, we configured our network with a dual switch leaf-spine layer to handle high traffic between servers. The HCA of all servers in Pods have uplinks and downlinks for 1:1 full-duplex communication and up to 800Gbps of bandwidth when connected 1:1 with GPUs of other servers.
Solving multiplexing bottlenecks
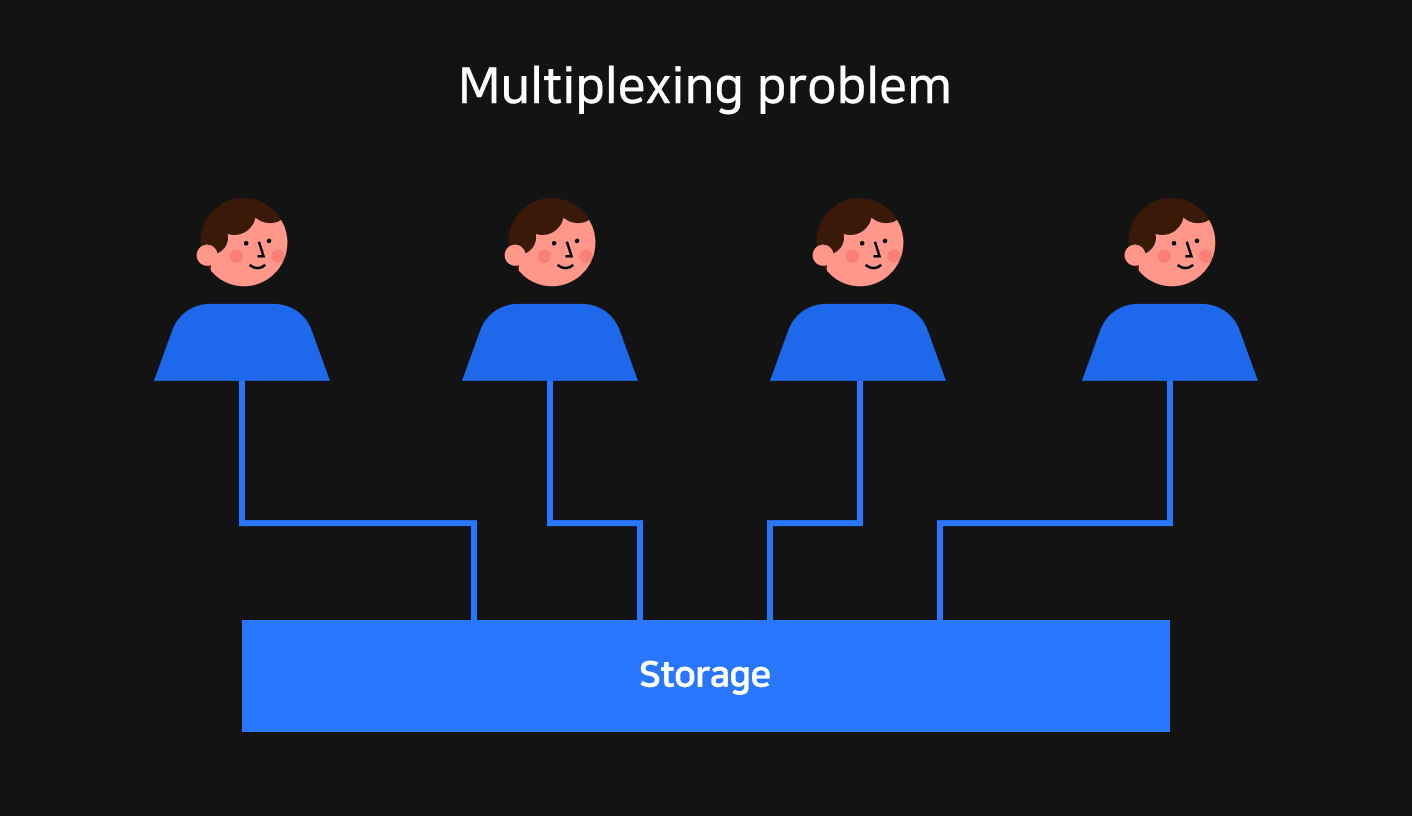
We previously confirmed that it was necessary to share GPU computation results in distributed training and more widely multi-GPU training, and that network bottlenecks between GPU servers can be resolved through an RDMA-based InfiniBand configuration. However there was still one more problem left. In deep learning training, you must load data from storage or save the results as checkpoints during training before GPU computation. If there's a bottleneck during this I/O process, GPU utilization will be reduced throughout the training process and the length of training time will be lengthened as a result.
Usually there's an initial large sequential write that occurs when storing large-scale training data, and then a periodic random read that occurs during the training process. Distributed training requires even more simultaneous random read performance on storage devices that most frequently communicate with GPUs because multiple GPUs will access the same data simultaneously.
Adopting high-speed storage DDN
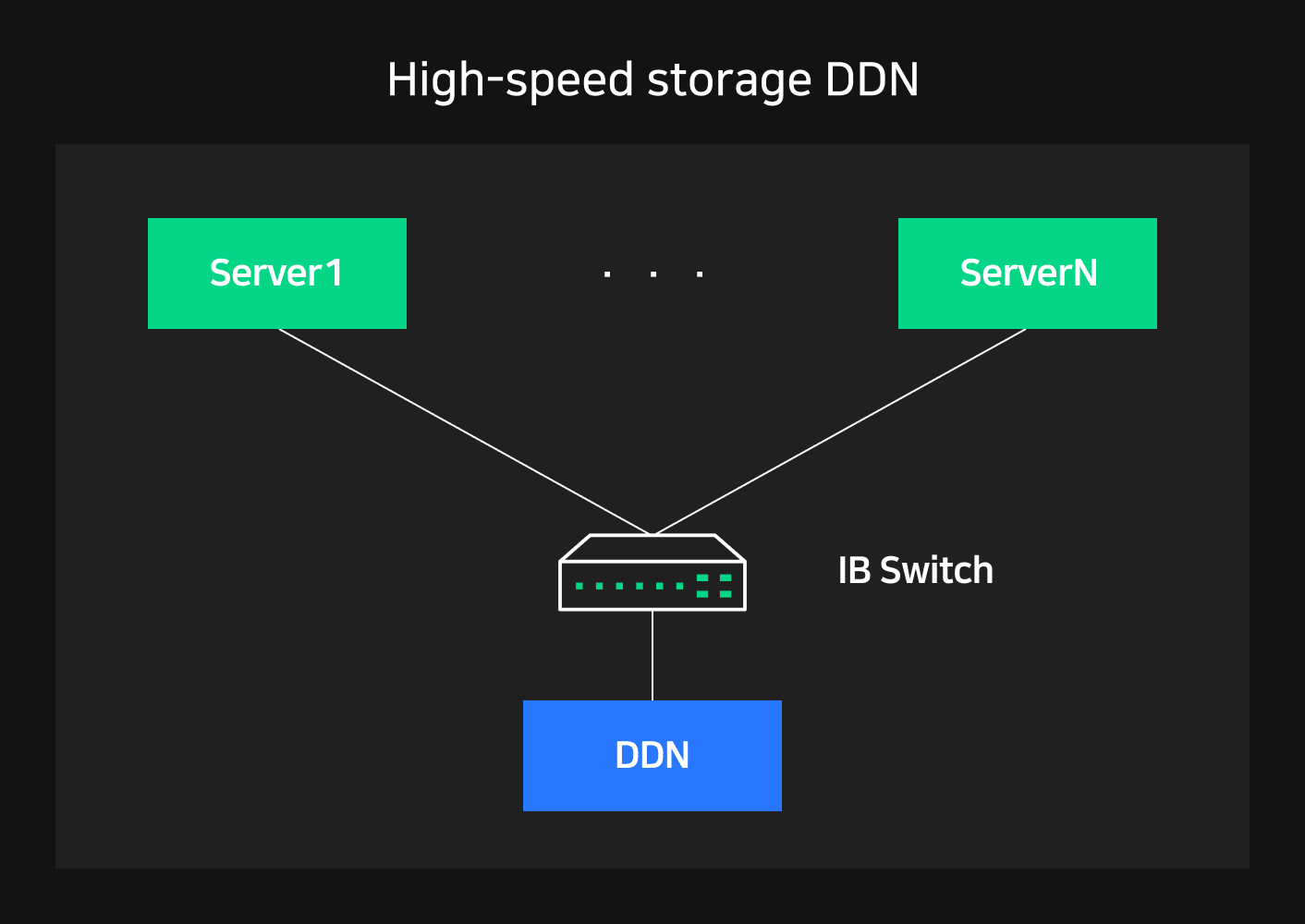
To address this, NSML adopted DDN (Data Direct Network) high-speed storage. DDN is optimized for A100 Pod configurations based on the Lustre file system, and is an NVIDIA partner solution that's already a proven storage platform in the world's largest SuperPOD environments. It allows for concurrent access to parallel file systems, making it easy to scale, and has shown the best IOPS and bandwidth performance that's required for handling a variety of user requirements and workloads.
NSML has one DDN storage per NSML Pod. DDN storage is connected to all NSML Pod hosts with InfiniBand. This enables communication with up to 800 Gbps bandwidth when multiple nodes simultaneously access DDN storage. InfiniBand-based GPU Direct Storage technology also enables GPU memory and remote storage to send and receive data directly.
Taking advantage of these characteristics, NSML uses DDN storage to cache training datasets. DDN can be shared across multiple nodes and ensures sufficient I/O parallelism. It can also communicate directly with the GPU, quickly sending DDN data to the GPU. Therefore, caching data in DDN can significantly increase training efficiency in intervals where training data as large as the batch size is repeatedly read.
In this first post in a series about NSML, we looked at how NSML started, what components it has, and what problems NSML Pods were designed to solve. The next post will explain the logical components of NSML and how we used Kubernetes, one of the most prominent orchestration tools, to implement them.