


Natural Language Processing (NLP) was one of the AI technology fields that has attracted global attention this year, and Generative Pre-trained Transformer 3 (GPT-3) was at the center of it. Technologies such as Microsoft's Copilot, formerly considered to be only possible in our wildest imaginations are becoming a reality through GPT-3. HyperCLOVA is the world's first massive AI model based on GPT-3 that is trained in the Korean language through CLOVA, and is currently being used in many NAVER AI services, such as CLOVA Speaker and Chatbot. We've made various attempts to apply the HyperCLOVA model to actual services, while also making those services more reliable and responsive. These are the five steps that we've taken to provide the services:
- Selecting a framework
- Creating a serving environment
- Implementing service features
- Optimization points
- Automating operations
From among these points, I will be covering steps 1, 3, and 4 in more detail in a series of blog posts, including this one.
Part 1: Selecting a framework
Selecting a framework to speed up the model serving process
One of the important parts of serving the HyperCLOVA model is the speed of services. The HyperCLOVA model has been growing in size for better quality and performance, thus increasing both the memory consumption and computation volume. The increased data transactions and computation volume between GPUs that resulted from the process of serving large models led to quite long latency. In fact, applying super-large models into services required a two to three times increase in speed depending on the GPU type.
We thought that optimizing computation at the low level should come first in order to increase the serving speed of the HyperCLOVA model. The serving process is largely divided into two parts as shown below: an internal transformer framework and an external service logic. GPT models, such as HyperCLOVA, carry out computation based on the transformer, and a framework is needed to create text through this process. After the text is created in the transformer framework, the result is delivered to users through the service logic. Since most of the time to respond to users are consumed in the transformer framework, reducing computation time in the framework was fundamentally important for increasing the speed.
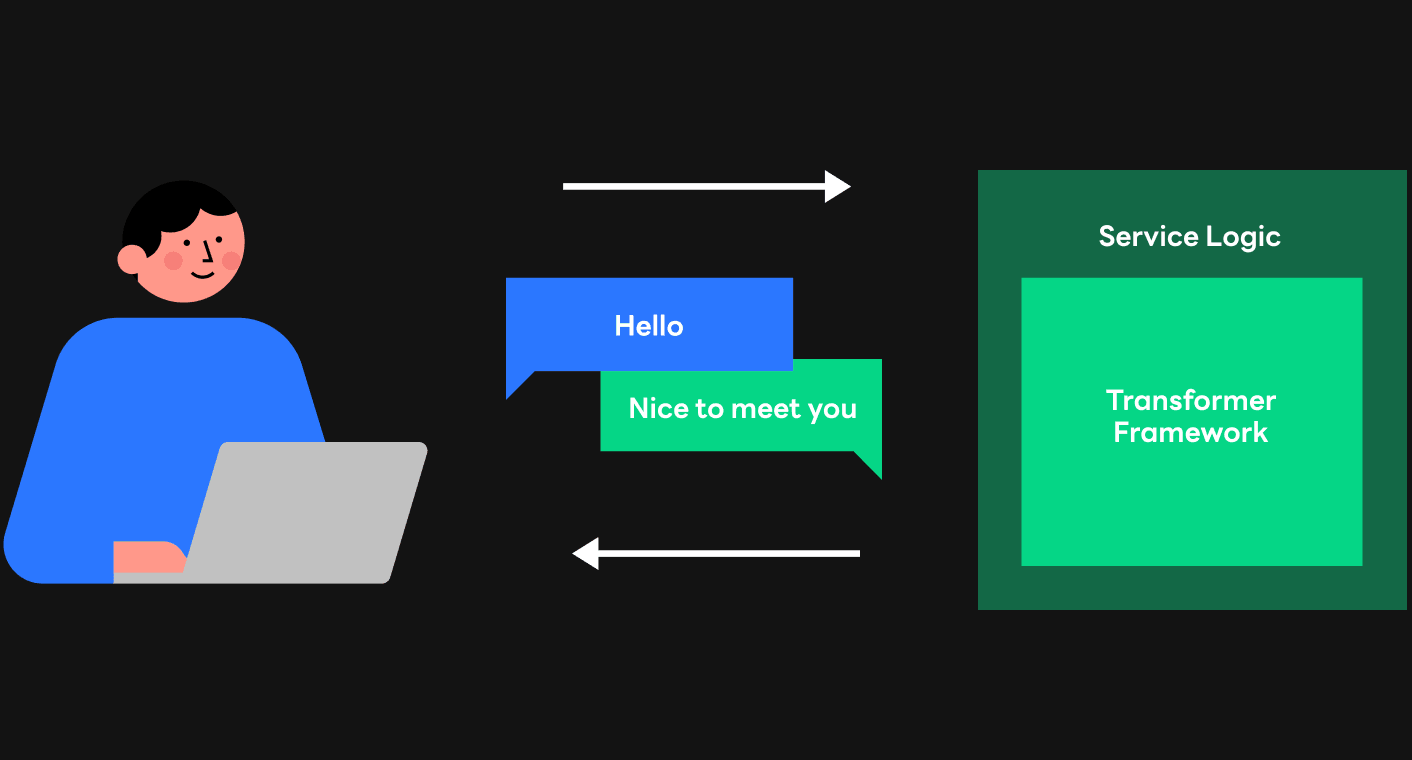
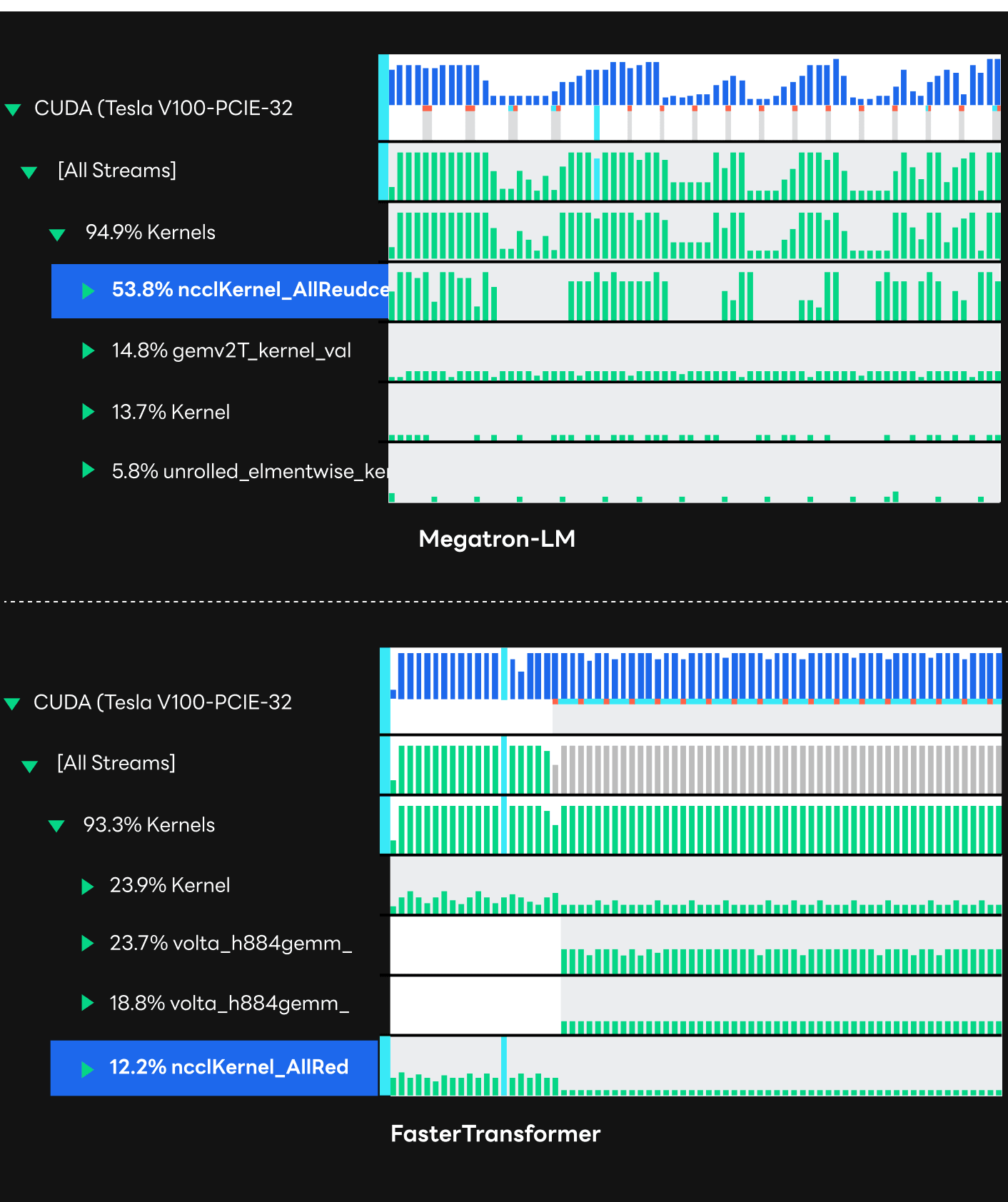
The traditional way of serving HyperCLOVA has been based on NVIDIA's Megatron-LM used for training a model through the transformer framework. Although it had the advantage of implementing desirable services relatively easily by leveraging frameworks the way it was used in training, the framework was not the optimized implementation for inference in which latency matters. In fact, inference computation profiling results via Nsight Systems says utilization is substantially low due to the poor use of GPU resources. In addition, we found that there had been plenty of overhead during the data collection process between multiple GPUs, which appeared to be ncclKernel in the following profiling results.
Adopting FasterTransformer
In practice, serving does not require all the steps that are required while training; all you need is an inference. Therefore, we wanted to apply the framework optimized for inference services, instead of the framework used in training. We decided to replace the traditional framework with NVIDIA's GPT inference framework: FasterTransformer. FasterTransformer is written with C++ and CUDA native kernels instead of PyTorch, and is applied with CUDA kernel-level optimization techniques, such as kernel fusion. With such an implementation method, we hoped to see more efficiency while using the GPU and less latency in the serving process.
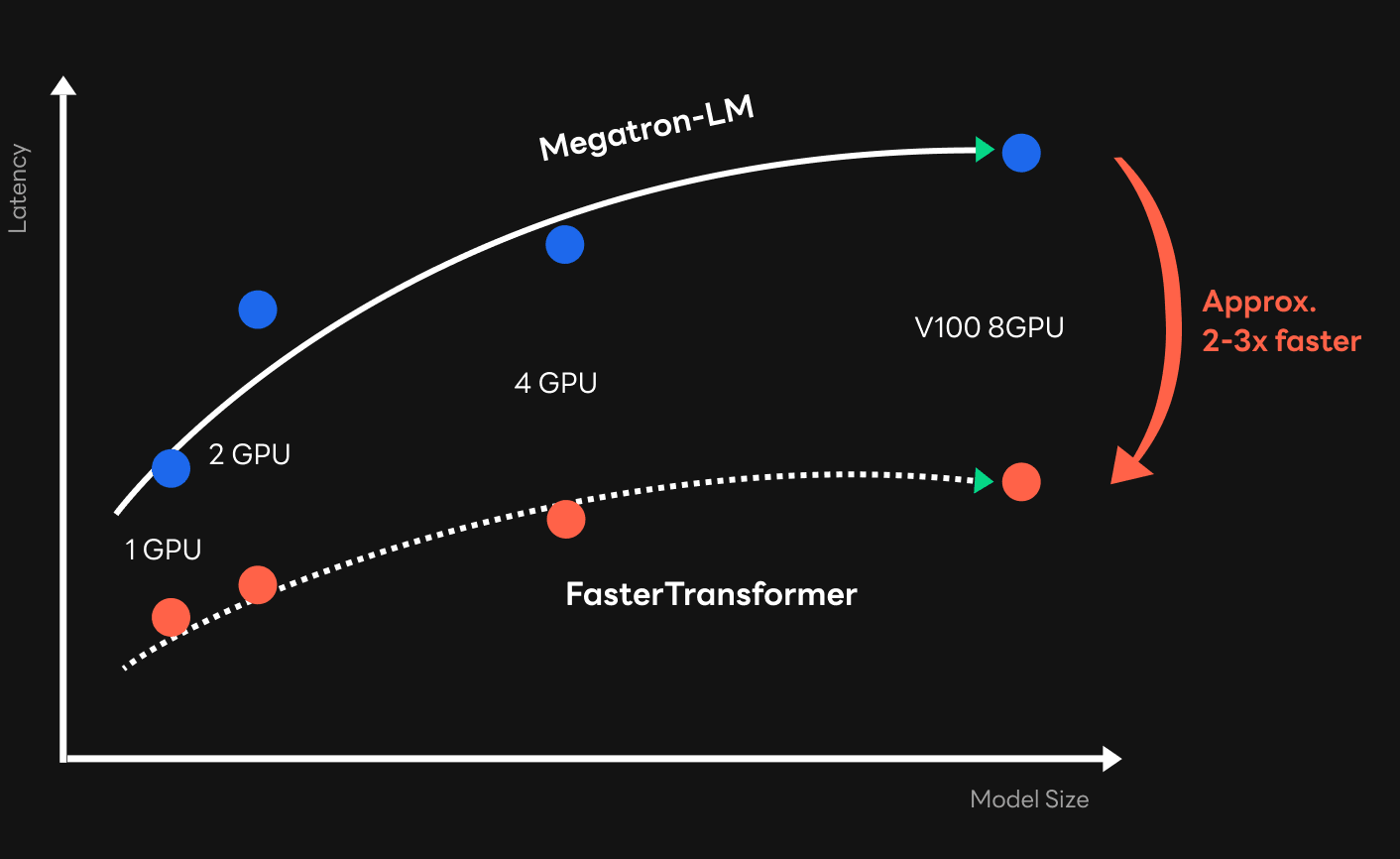
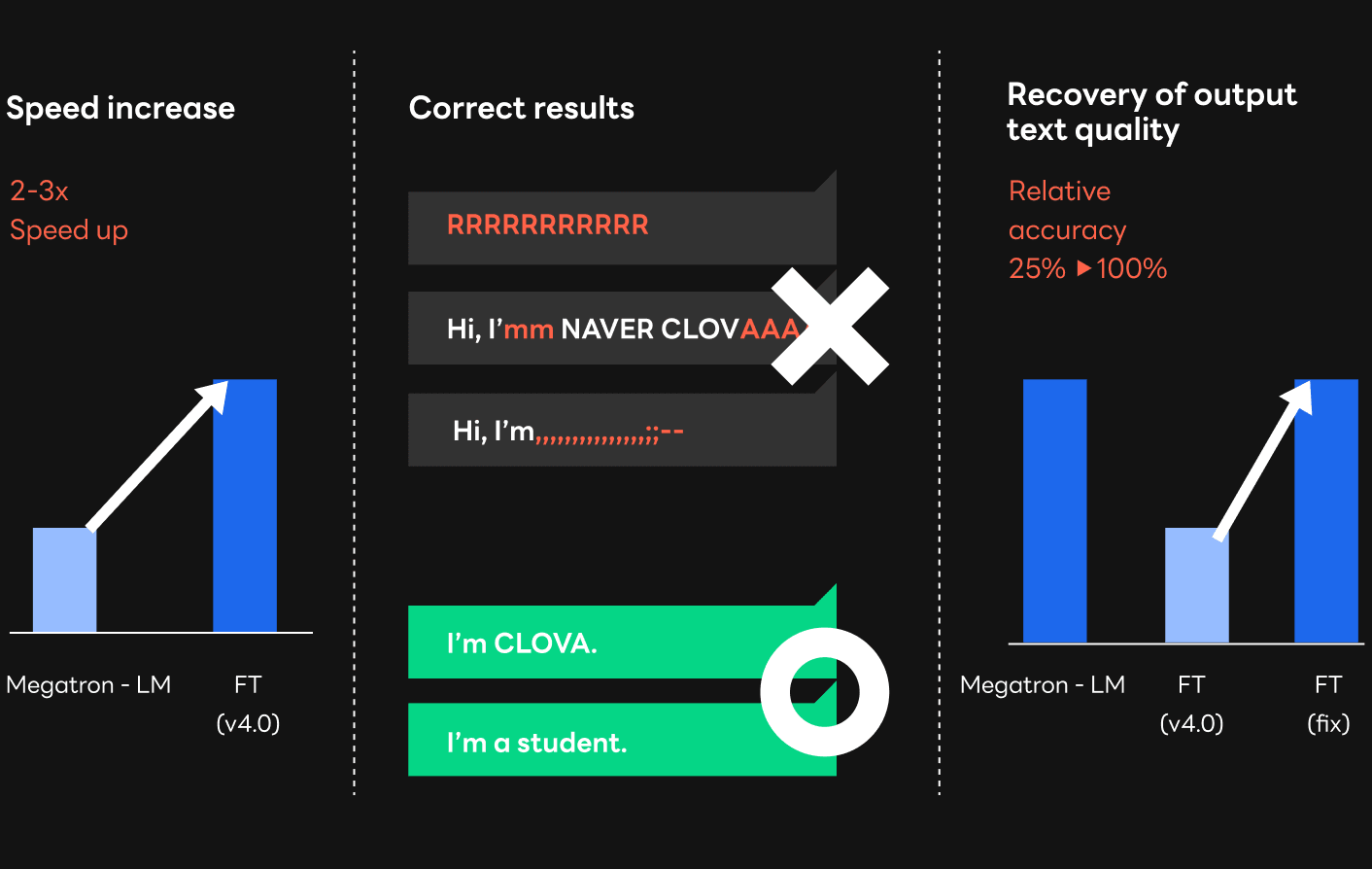
As a result of replacing the existing framework with FasterTransformer, we've seen impressive success in terms of speed. Although there is a difference depending on the size of the model, as you can see in a graph comparing latency and the model sizes below, it was possible to increase the speed about two to three times compared to the framework used in training. With such an improvement in speed, we were able to reach the target speed applicable to the service, especially in large models. Given that the HyperCLOVA model is growing in size to improve the quality of sentence generation, it was an impressive achievement. The results of profiling with Nsight Systems shows which part has been improved in the FasterTransformer compared to the existing framework. As the profiling results shows, GPU resources were used more efficiently with much higher utilization compared to the traditional framework. Moreover, there were relatively fewer overheads in the data collection process (NCCL kernel) between GPUs, which was a problem in the existing Megatron-LM framework.
Problems and solutions occurred after introducing FasterTransformer
There were problems to be resolved to immediately apply FasterTransformer to services.
First, we had to modify interfaces between the framework and the service logic. Most of the features in the traditional framework were implemented via PyTorch and API modification in the service logic was much easier. However, since most of the features in FasterTransformer are made in the form of the shared library and provided through APIs only accessible with the computation results in the service logic, we had to modify interfaces between the service logic and the framework.
Next, we found consistency issues in v3.0 and v4.0 of FasterTransformer that we used, making it hard to apply them directly to services. Here, consistency issues refer to when incorrect computation leads to incorrect words or compromised words in quality. As shown in the images below, an issue occurred where incorrect words were outputted instead of correct sentences.

There were several factors that brought about consistency issues. A few examples include the checkpoint modification issue, the FP16 computation issue, and the bugs in the GPU kernel.
Resolving the checkpoint modification issue
The checkpoint modification issue also relates to the framework modification process described above. FasterTransformer only offers inference computation, not a model training process. We had to use checkpoints (weight and bias included) in the Megatron-LM used to train the HyperCLOVA model, and also had to modify the Megatron-LM checkpoint for FasterTransformer. We modified the checkpoints by using code provided with FasterTransformer and created sentences with these results, but still words with poor quality were created.
At first, we didn't know exactly where the issue came from, but we finally found out how to resolve this as we saw the existing NVIDIA GPT-2 model ran without any issues, but the HyperCLOVA model trained through NAVER had issues. In the case of the HyperCLOVA model, the indexing of the stored checkpoint was different from the conventional method since the checkpoints were used in a different way from the NVIDIA GPT-2 model. We had to consider this during the checkpoint modification process for FasterTransformer, but we didn't. This issue was resolved by considering the computation process in Megatron-LM in reverse and revising the modification processes.
Deep dive into GPT-3 with FP16
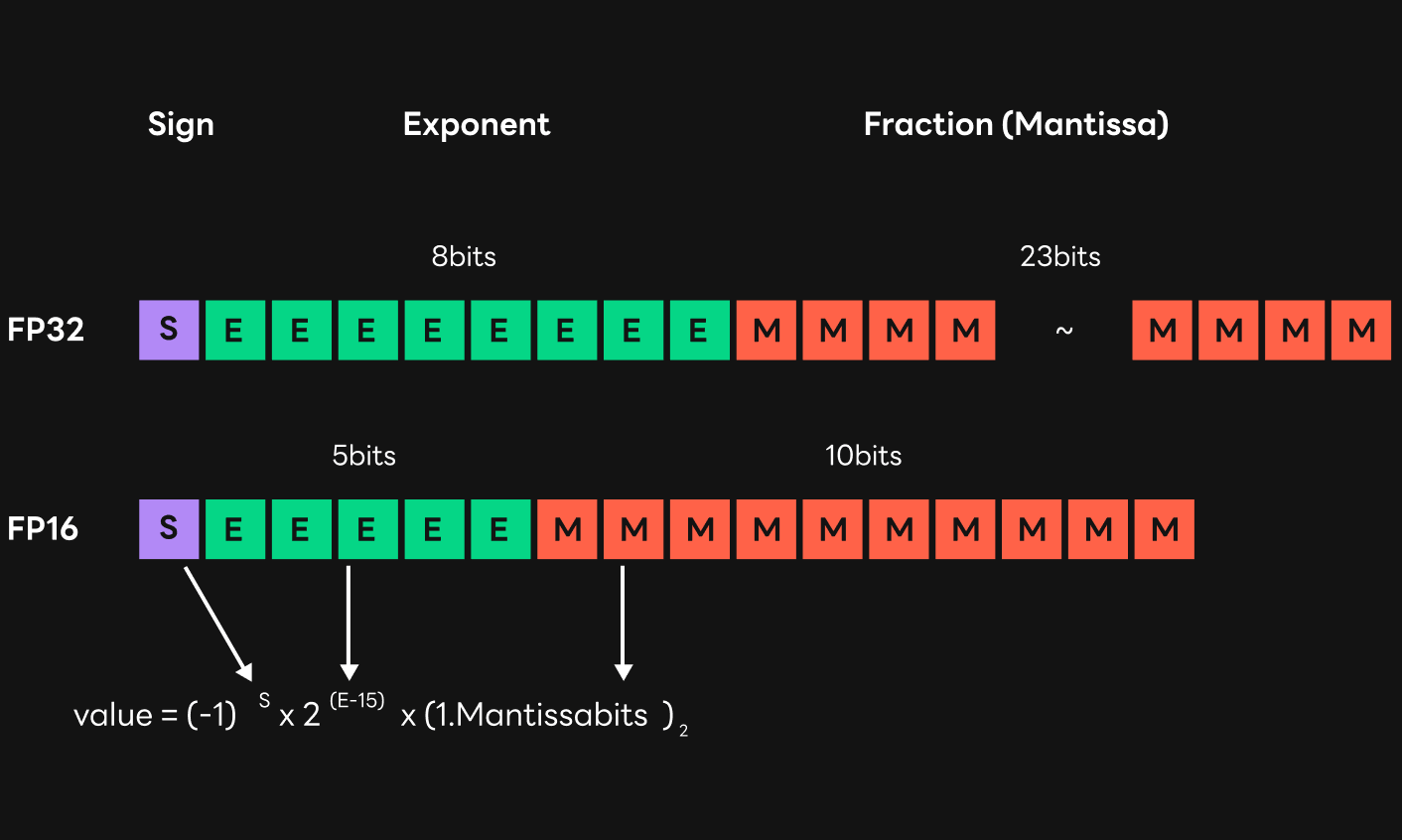
Next, let's look at issues caused by the Floating-Point (FP) 16 type computation. The HyperCLOVA model was conducted with the FP16 type, instead of FP32, to speed up the serving process. In the case of the HyperCLOVA model, computation with the FP16 type was three to four times faster than with the FP32 type. Computation with FP16 was very important for reducing the time for training and inference, but FP16 caused some issues because the range of expression and the degree of precision were reduced compared to FP32.
First of all, when the HyperCLOVA model was large, computing with FP32 was okay, but computing with FP16 caused quality loss. This is because FP16 caused overflow during computation, resulting in the data values being inf or Not a Number (NaN). In the case of FP32, the maximum value is 3.40*e38 with eight exponent bits. However, the maximum value of FP16 is 65504 with five exponent bits, which is less than FP32, so FP16 is relatively vulnerable to overflow issues.
The figure below shows the simple description of GPT computation sequentially processed in multiple transformer layers and then General Matrix-to-matrix Multiply (GEMM), or a matrix multiplication computation, continues in each layer. In this process, the GEMM computation value in the first layer is relatively small, but this value gradually increases as it goes to the rear layers. Larger models mean more layers and larger data values in each layer, thus increasing the probability of overflow as larger values are made in rear layers. If overflow occurs and the computation values come with inf values, only incorrect words are generated continuously after a certain point.

There aren't many solutions for this situation. If the inf value can be detected, you can change the value to 65504, the maximum value of FP16, instead of the inf value. Another way is to decrease the overflow probability by changing the GEMM kernel data type and computation type, which are likely to cause overflows, into FP32. Since the former method used NVIDIA's cuBLAS GEMM kernel, it is impossible to change the value. So we used the latter method to ensure the GEMM kernel computation value that causes overflows was stored as a FP32 data type. This configuration can prevent overflows from occurring since the values in between are stored in FP32.
Compared to FP32, FP16 has a very small number of exponent bits that were related to previous overflow issues, as well as mantissa bits called fraction bits. A mantissa bit is a value corresponding to the mantissa of a floating-point data, so the smaller the number, the smaller the number of decimal digits that can be expressed.
Such characteristics of the FP16 data type can lead to "swamping" during GPT computation. Swamping is a situation in which a small value is lost when adding a large value along with a small value, as if the small value is drowned in the swamp of the larger value. These are the reasons for the loss of value.
Addition of floating-point types starts by matching the exponent bits of two values. At this time, the small value's exponent bit must be set to the exponent bit of a large value. For the small value, you need to move the mantissa bit appropriately to keep the value the same before and after changing the exponent bits. Then, the values representing some of the mantissa located to the right of the mantissa bit are lost. The figure below is an example of such a situation. You can see that 0.00098 is now being added to 3.75. The result is 3.75, not 3.75098. In the process of matching exponent bits of small and large values, the value of 0.00098 was not reflected to the addition because of the small number of mantissa bits in FP16. Since the number of mantissa bits of the FP32 data type is more than double that of the mantissa bits of the FP16 data type, the smaller proportion of data values were lost in this process, but significant values are likely to be lost in the FP16 type. The data loss issue caused by swamping is more likely to occur when the gap between the values for addition increases. For this reason, if the weight distribution is uneven in the training process, the swamping-induced issue can be intensified. Moreover, considering the entire computation process of the GPT model with multiple layers, the computation result of the previous layer is used in the rear layer, thus errors caused by swamping accumulates as it goes to the rear layers.

Because this swamping issue occurred in the FP16 computation process, two problems can occur in the GPT-3 model, such as HyperCLOVA. First of all, due to the data loss described above, there is a possibility that different results from the existing FP32 computation or damaged text can be produced. Next, in a situation where you expect to generate the same words from the same inputs through a specific option, different results may come out depending on whether the transformer computation is carried out in a single batch or a multi-batch. Here, the specific option is the greedy option. When using the greedy option, it is expected that the same sentences will lead to the same sentences or words regardless of the random values, but different values can be created even with the greedy option because of the swamping effect that comes from the FP16 type computation.
To resolve this issue, we used FP16 for the cuBLAS GEMM kernel data type but set the compute type to FP32. Even if the input data type is FP16, the FP32 compute type setting ensures that the intermediate addition processes are stored in the FP32 data type, and it secures mantissa bits sufficiently, thus mitigating the degree of data lost. As a result, we've also seen that the frequency of different results in a single batch and a multi-batch due to the swamping effect was reduced with the greedy option.
Results
FasterTransformer was reliable for using with our services after resolving the problems mentioned above, along with additional bugs such as incorrect indexes in the GPU kernel, race conditions, and memory leaks. As a result, using FasterTransformer for services instead of Megatron-LM ensures that we could speed up our services about two to three times depending on the model size or GPU environment.
While resolving the consistency issues of FasterTransformer, we fixed the problem of incorrect results in the earlier version of FasterTransformer, and the issue that caused a 75% drop in relative accuracy compared to Megatron-LM when using certain models. This allows you to expect Megatron-LM level text quality.
The results of resolving the consistency issue were applied to the FasterTransformer v5.0 beta via open source contribution. Please refer to the DEVIEW 2021 presentation(https://deview.kr/2021/sessions/416) for more details.


