

Part 3: Optimization points
Introduction
In this part, I would like to cover two technologies greatly needed for optimizing HyperCLOVA-based services. First, I'll talk about the multi-batch feature that combines multiple requests and processes them at once to efficiently process user requests. Second, I'll show you what we've done to provide a faster response in multi-turn pattern services, such as CLOVA AI Speaker, where conversations are made in turns. Here is the table of contents:
- Multi-batch
- Multi-turn
Multi-batch
Why we need multi-batch
Companies dealing with large-scale traffic may consider multi-batch when they need to increase throughput while providing services using AI models.
In general, the inference process, unlike the learning process, focuses more on reducing latency than on increasing throughput. Thus, rather than using a maximum batch size (i.e., increasing the size that can be processed at once to maximum), we reduce latency by processing only a single batch at a time. However, when an AI model has to handle large-scale traffic, even if the batch size is reduced to a minimum, the overall latency for each request may not be reduced. This is because if the amount of requests to be processed increases, the requests that came in later may spend a lot of time waiting in the queue while the AI model is processing the requests that came in first. So even if the computation latency is reduced, the waiting time for entering the computation process increases, and as a result the user experiences a slowdown.
In addition, we should also consider the GPU environment in which the service is provided and the characteristics of GPT-3-based models such as HyperCLOVA. GPUs perform parallel processing using numerous cores and high memory bandwidths. In order to make the most of GPUs with these characteristics, it is recommended to provide data at once as long as the GPU can handle the size. In this case, even if the amount of each computation increases, the latency required for the computation does not increase significantly.
You can see this pattern more clearly in GPT-based models, such as HyperCLOVA. As I mentioned in the previous two blog posts, GPT computation consists of a summarization step for processing data in input sentences at once, and a generation step for generating words sequentially. In the summarization step, multiple token IDs are processed at once, so the numerous cores of the GPU can be used more efficiently. However, in the sentence generation step, tokens are generated one by one, and those many GPU cores may not be fully used. This means that the utilization of cores and memory can be poor.
If we increase batch size to increase the amount of data to be processed in the generation step, computation latency does not increase significantly because the GPU's numerous cores perform the task successfully. Therefore, processing multiple requests at once using multi-batch can be a great benefit in terms of throughput in the generation step.
If you look at the figure below, you can see that the batch size has been increased from 1 to 8 in the process of generating sentences for a specific input, but the computation latency has hardly increased. So, if there are too many requests to be processed, it can be effective in increasing the batch size to increase the instantaneous throughput so that we can shorten the time each request has to wait in the queue and reduce the overall latency.
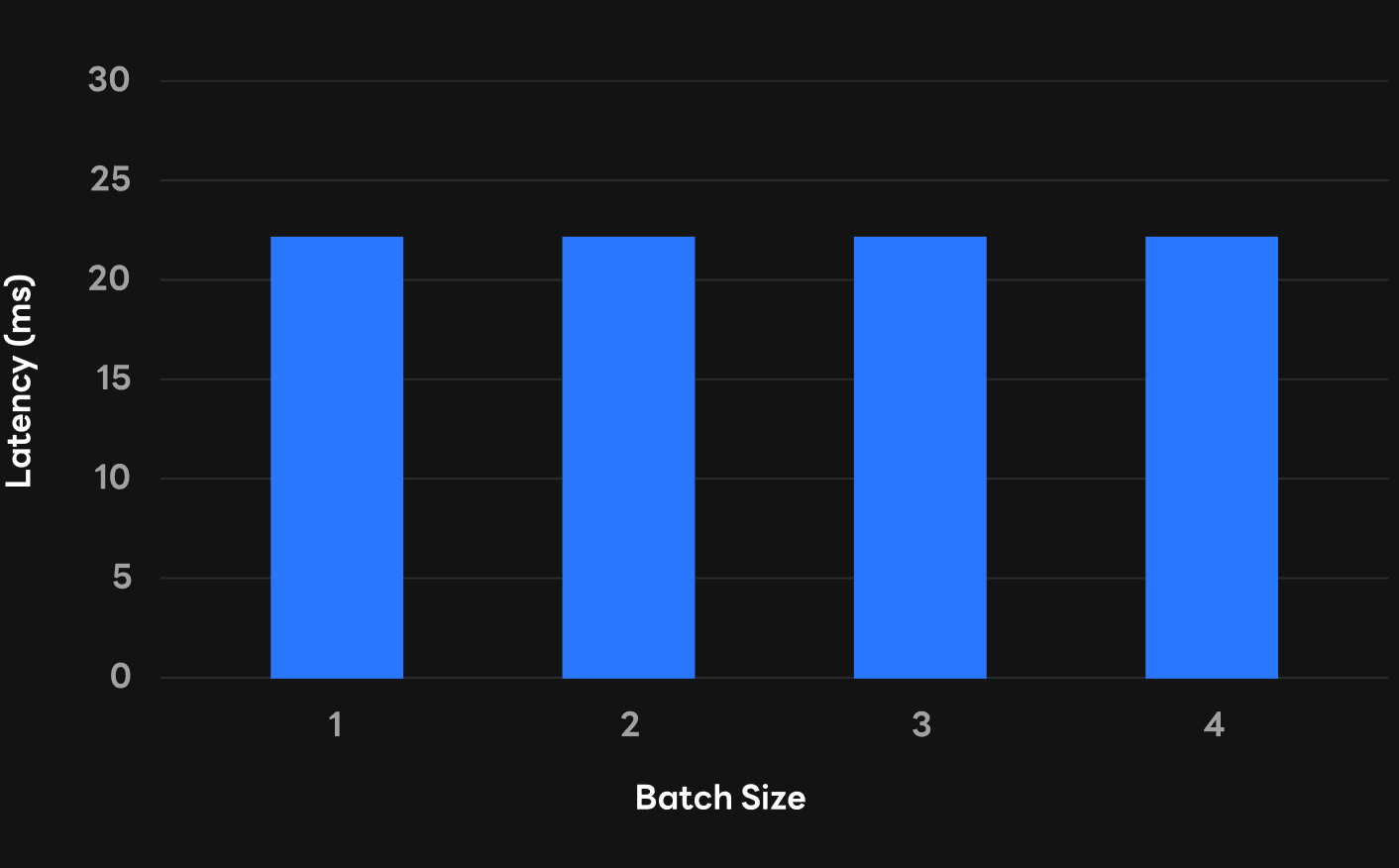
Application and problems of multi-batch
At first, we tried to apply a technology called dynamic batch for the batch process. Dynamic batching specifies a maximum batch size (e.g., 4, 8) and combines the requests received for a set duration (e.g., 1 second) into one batch before the computation. Through this, we tried to reduce the overall latency by increasing throughput and reducing the waiting time in the queue by processing several requests that came in almost at the same time.
However, when multi-batch was applied, the latency doubled in certain situations while throughput increased without significant changes in latency in most cases. Looking closely, we found this problem occurred when the length of input sentences in the requests combined into one batch was significantly different.
This was due to the structural problem of the transformer. Let's look at the example below. When generating a sentence by setting the batch size to 1 (single batch) for each input sentence, you can simply process each input sentence at once in the summarization step and generate a sentence of the desired length in the generation step. However, if the two input sentences are grouped into one batch, the length of the sentence that can be processed in the summarization step is fixed to the length of the shorter sentence among the two sentences. This is because if it is set to the length of the longer sentence in the summarization step, it is impossible to accurately process the shorter sentence.
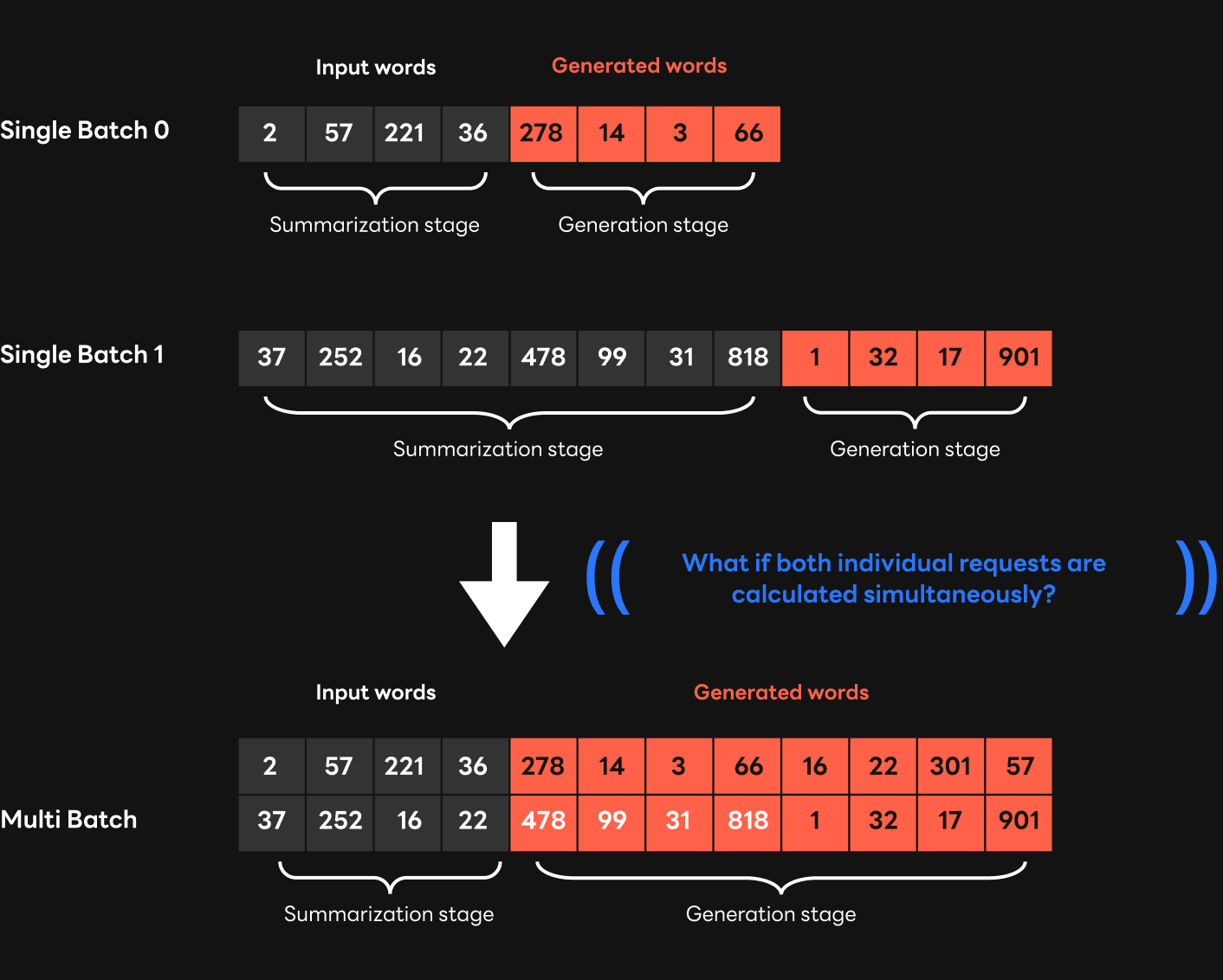
If the length of the sentence processed in summarization step is decreased for multi-batch processing like this, as all other parts need to be processed one word at a time in the generation step, it can lead to an increase in latency. In the worst case, if the length difference between the sentences you want to combine into batch is several times the length of the sentence you want to generate, multi-batch application can result in an extreme increase in latency and even a timeout.
First approach: Bucketing strategy
The first method we used to solve the problem that occurred when processing sentences of different lengths in multi-batch is the bucketing strategy. To put it simply, the bucketing strategy classifies requests with similar lengths of sentences using multiple buckets. Even if the requests came in almost at the same time, if the difference in length between the two sentences is greater than the predetermined threshold, they will not be combined and processed as one batch.
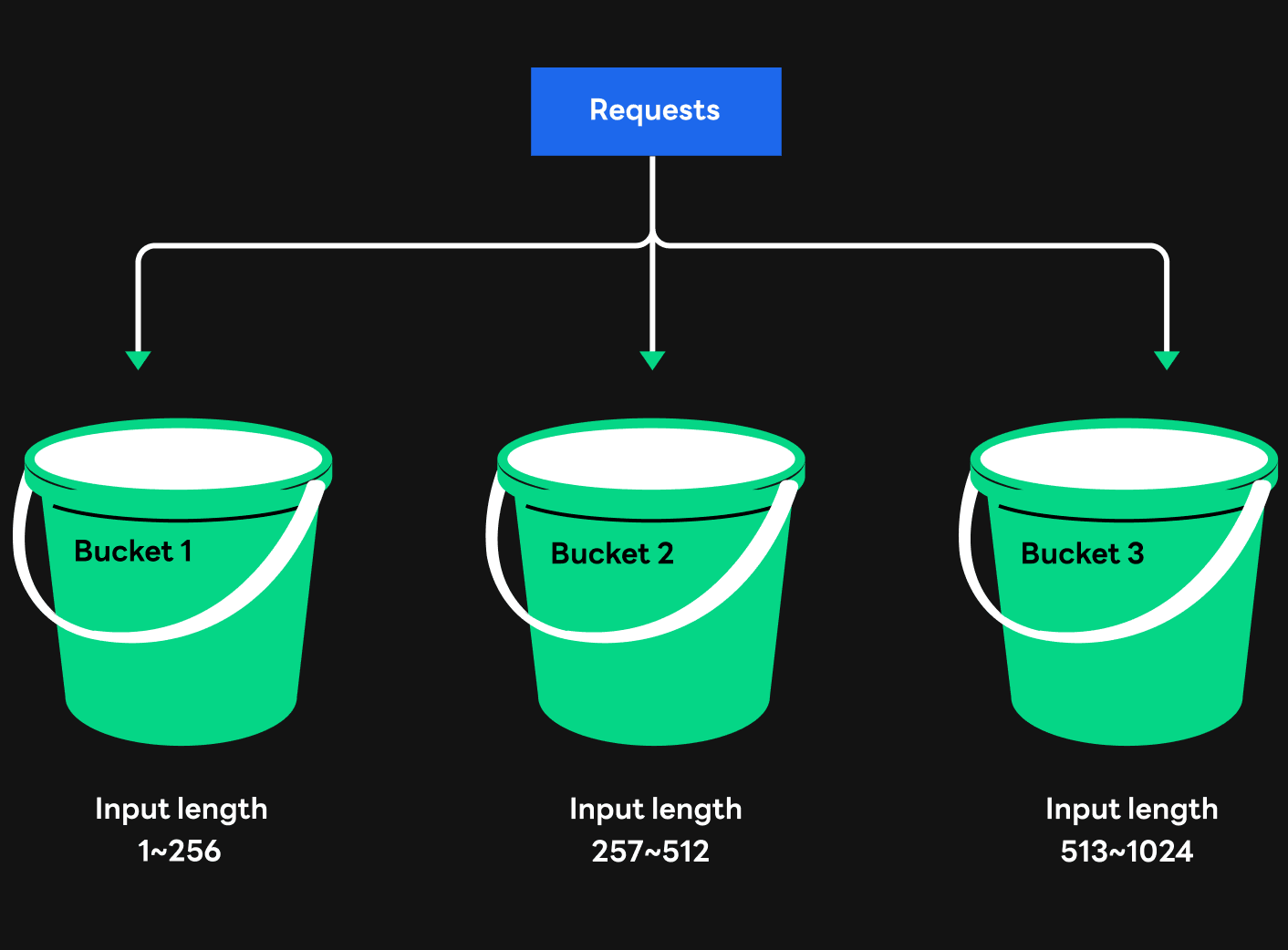
This method can prevent latency from increasing significantly while applying multi-batch. However, even if this method is used, latency can still increase as the length of sentences to be processed in the generation step increases when sentences with different lengths are grouped into batches. In addition, as we try to minimize the in sentence length difference when grouping them into batches, we often cannot run multi-batch in services, which makes it difficult to benefit from multi-batch.
Second approach: Using GPT attention mask
The second approach uses GPT attention mask, a method that was inspired by Hugging Face. The bucketing strategy described earlier was not actually optimizing computation but rather preventing a sharp decline in performance in certain situations by considering service patterns. The heart of the problem of inefficient multi-batch operations is that when the input sentence lengths of requests that are to be grouped into batches are different, computations that could have been done in the summarization step are serialized, and the latency increases. So we thought about how we could go beyond the bucketing strategy and optimize computation to solve this problem.
What caught my eye was GPT's masked self-attention. In a GPT model, only decoders, not encoders, are used in the transformer. The main difference between the encoder and the decoder is that the encoder uses self-attention while the decoder uses masked self-attention. A self-attention encoder examines the context both before and after the token being learned. For this reason, it is known to have strengths in extracting the meaning of sentences. On the other hand, a masked self-attention decoder can only look at the context before the token being learned. Therefore, a GPT model composed of decoder layers has an advantage in sentence generation. Here, an attention mask is used to allow the decoder to only look at the previous context, excluding tokens that came out later from the computation.
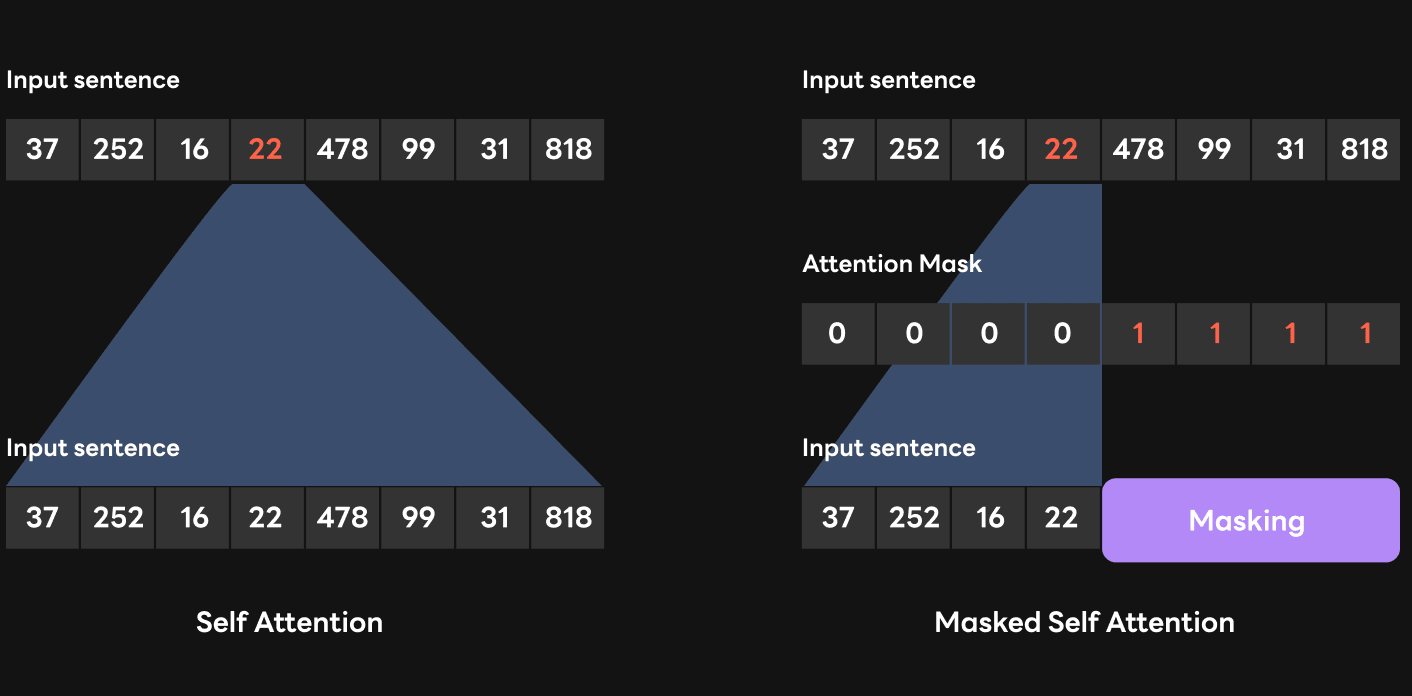
In other words, with the attention mask, we can include only the tokens we want in the computation. The problem we had with the multi-batch feature earlier was that latency increased as calculation that could have been done in the summarization step was passed to the generation step when input sentences of different lengths came in. However, the attention mask and padding can solve this problem.
So here's what you should do. First, among the sentences to be input together as a batch, add padding with a random value in the shorter sentence to match the length of the longest input. By delivering the same length of inputs to HyperCLOVA, you can generate only necessary sentences because the lengths of the inputs processed together as a batch in the HyperCLOVA model are the same.
In this case, a token corresponding to the padding is included after the sentence that came in as a short input, and this can hinder the generation of the correct input sentence. We adjusted attention mask value appropriately so that the value located in the padding would not be included in the computation. We also applied this method to the CUDA kernel inside FasterTransformer in collaboration with NVIDIA.
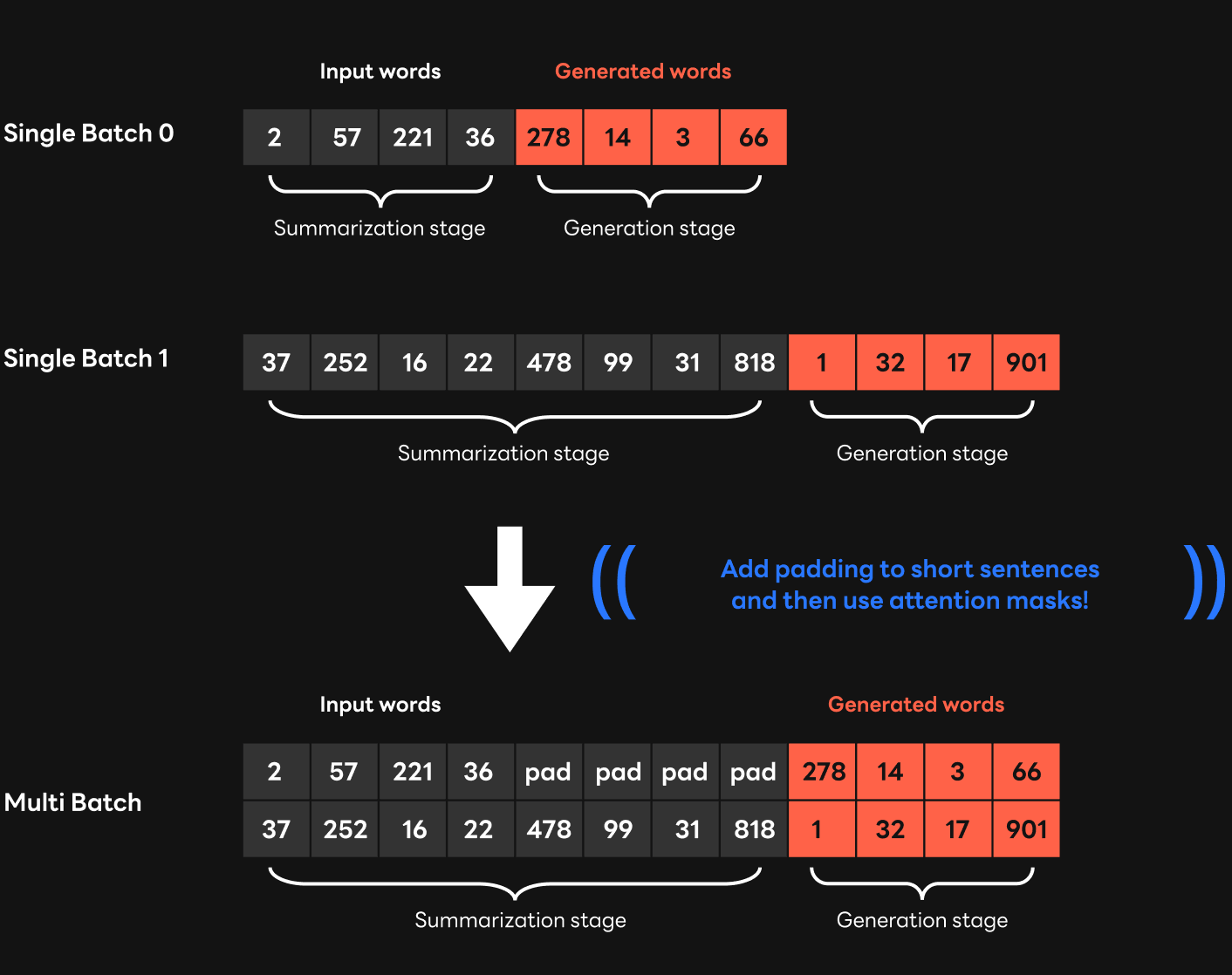
By modifying the attention mask in the multi-batch process, it was possible to prevent the computation time from increasing as computation is serialized when processing requests with different input lengths. The degree of performance improvement varied depending on the distribution of input sentence lengths in the requests, but when the batch size was increased to 8, the processing time that used to be 5 times slower than a single batch was improved to become 20% faster than a single batch. In addition, when the input sentences had similar lengths, the throughput was improved by six times compared to a single batch.
Multi-turn
There are various patterns in the service using HyperCLOVA. Among them, there is a multi-turn pattern in which HyperCLOVA and the user have a conversation every turn and create a new sentence based on the previous conversation.
In a multi-turn pattern, HyperCLOVA understands the context better and can generate high-quality sentences. This multi-turn pattern becomes an optimization point from an engineering point of view. In general, each time HyperCLOVA and the user have a conversation over several turns, records are accumulated, resulting in a longer request sentence with HyperCLOVA. However, since the previous conversation has already performed the calculation when processing the previous request, if the calculation result is well cached, the overlapping part can be skipped and the response time can be shortened.
The figure below, which was also included in the second post of the three-part series on HyperCLOVA Service, shows the decoder computation process.
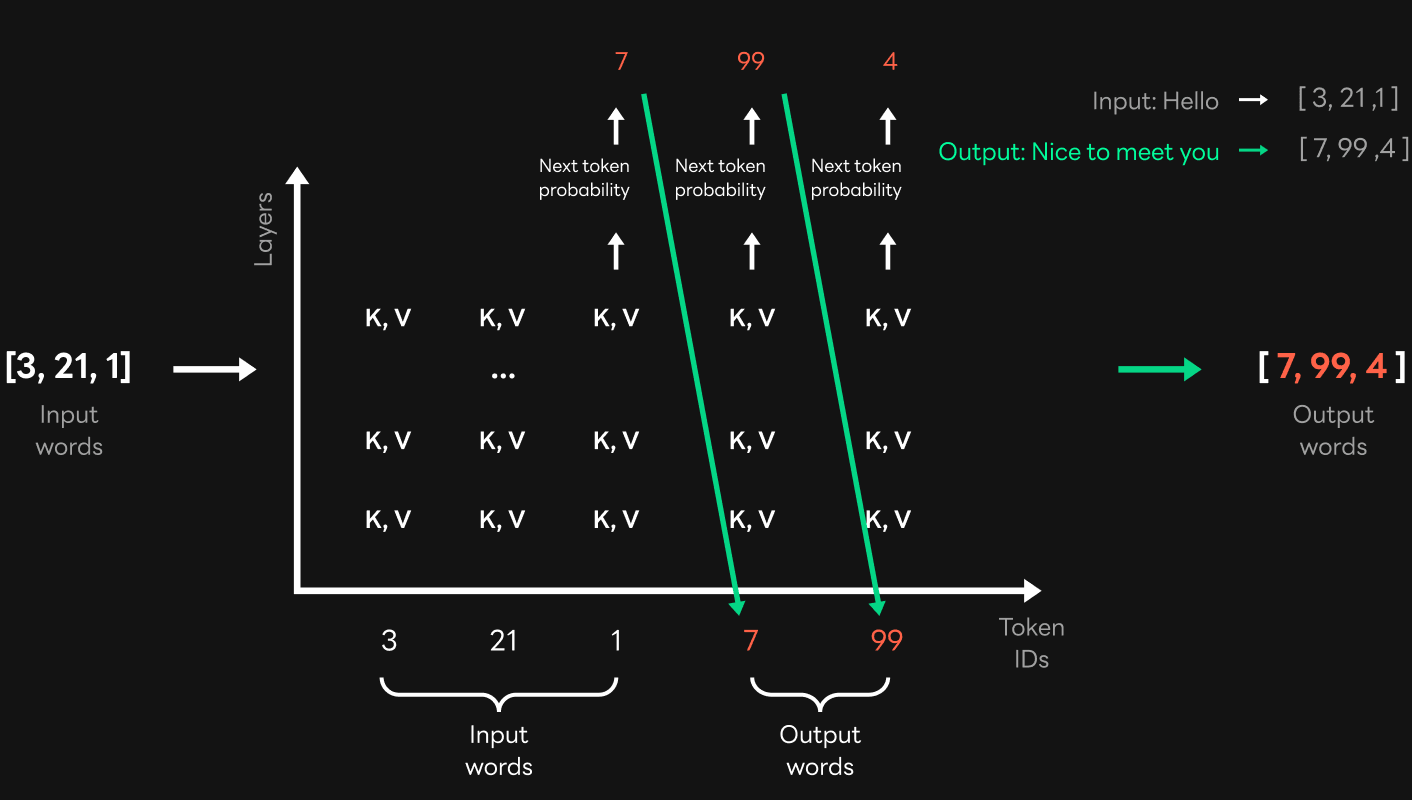
The decoder uses masked self-attention, generating its own key and value by referring to all the keys and values available as the previous input results. In the figure above, the keys and values of the Token ID [3, 21, 1] are used for the computation for Token ID 7, and for the next token, Token ID 99, the keys and values of the Token ID [3, 21, 1, 7] are used for computation. In other words, if this information is cached elsewhere and everything is the same as the previous token ID, it is possible to bring and use the cached information for the next token ID. The figure below shows how caching works in a multi-turn pattern.

For example, if you continue to receive the user's inputs when "nice to meet you" is output after "Hello," you can just use the cached results without performing computation for the keys and values corresponding to "Hello nice to meet you" again. In this way, you can omit the computation for most of the input sentences.
However, you cannot store computation results corresponding to all requests in the GPU. Since the size of the stored keys and values is proportional to the size of the model and the number of tokens, they can take up all GPU memory with just a few requests. Therefore, keys and values should be stored in a space like DRAM. In this case, it takes additional time to exchange data between the CPU and the GPU. In other words, there is a trade-off between the computational time and data transfer time. Therefore, in order to maximize performance, we allocated a part of the DRAM in the form of pinned-memory as a caching space to store the computation results.
Our test showed that performance was improved by 20% compared to the existing method in a case where the caching effect can be experienced, as shown in the figure below. When a cache miss occurred, the latency increased by about 10% due to the time spent to send the keys and values in the GPU to DRAM. However, it was also confirmed that the increase in latency can be minimized by allowing parallel operation of data transmission and computation.
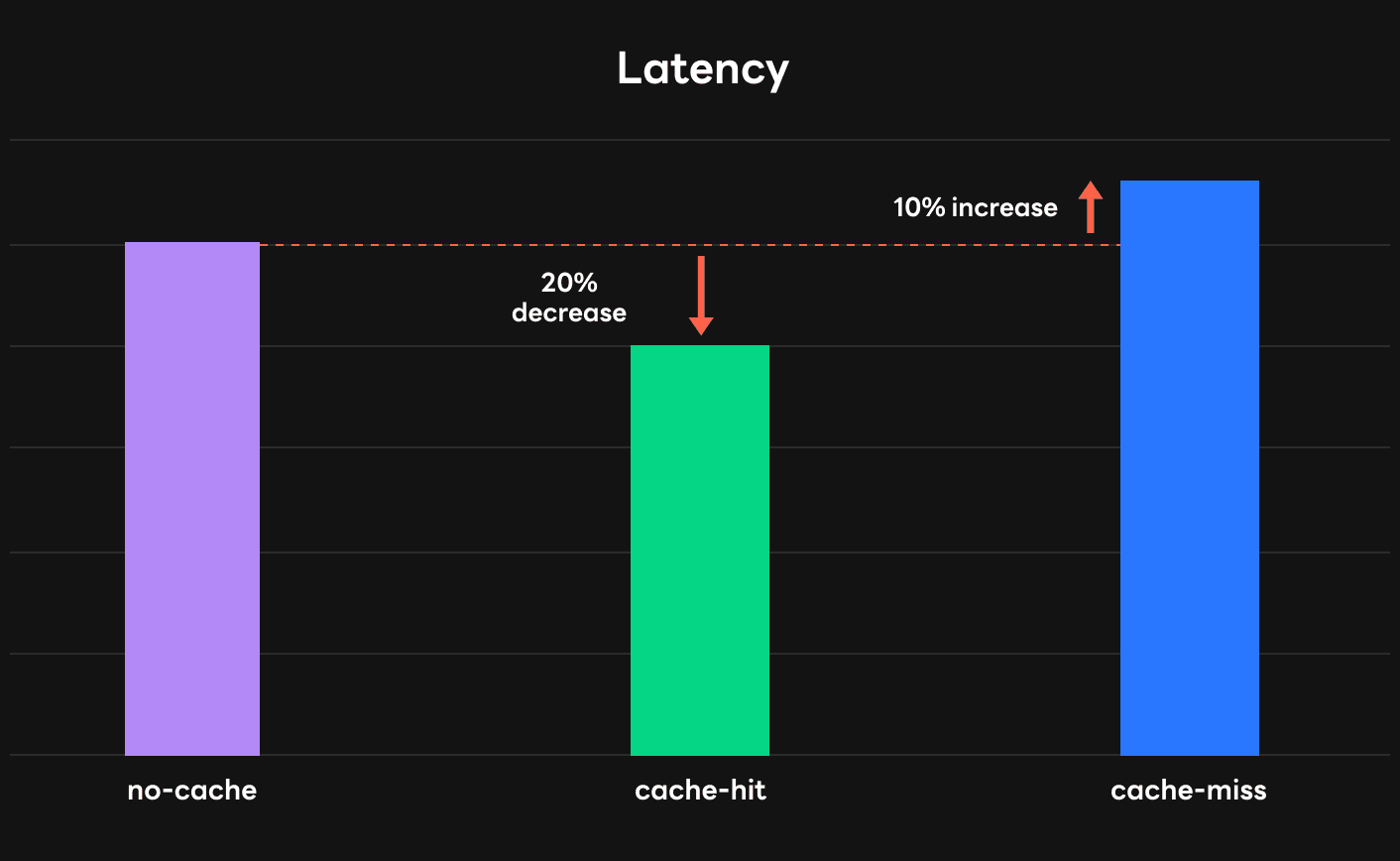
So we confirmed that the performance can be improved, but we did not apply this to the service. This is because the benefits were not as great as expected. As I mentioned earlier, in GPT-3, a bottleneck usually occurs in the sentence generation step, so caching did not have much effect. In addition, the size of the keys and values to be cached was large, so it took longer than expected to retrieve data from the GPU.
To provide faster service, we will continue to improve HyperCLOVA by identifying ways to reduce the size of keys and values or more appropriate cases for applying the caching techniques.



