

Introduction
With the recent introduction of hyperscale NLP models, dialogue systems have seen a rapid improvement in terms of natural dialogue. Among these systems, models based on open-domain dialogue have demonstrated an even faster pace of growth. While these models have the advantage of flexibility in various dialogue situations compared to scenario-based systems, there are a couple of challenges when it comes to using these open-domain dialogue models for dialogue services.
The first challenge is having largescale dialogue data for training hyperscale NLP models and dialogue models. It’s been proven that training hyperscale NLP models with largescale dialogue data is highly effective in training the model’s dialogue capabilities [Zhang et al., ACL, 2020; Roller et al., EACL, 2021]. Conversely, it’s difficult to improve open-domain dialogue capabilities without largescale dialogue data.
The second challenge is fixing the role of open-dialogue models. Hyperscale NLP models are trained with data from numerous domains and can develop a variety of identities from that data. Since dialogue services are generally designed to have a fixed role to serve a specific purpose, having a model that uses a different identity every time it initiates dialogue would lead to a very unstable service. Therefore, it’s crucial to fix the roles of your dialogue models when you use them for your service.
The two challenges are conflated when you are in the process of developing a service. You need to use data from various sources if you wish to collect largescale dialogue data, but this makes it impossible for the model to be trained with a clear role. On the other hand, collecting dialogue data of one type is costly and difficult to collect largescale data. This is especially difficult if you are creating a service with a role that was previously non-existent as there is no way to naturally collect dialogue data based on that role. You must create your own data from scratch in this case.
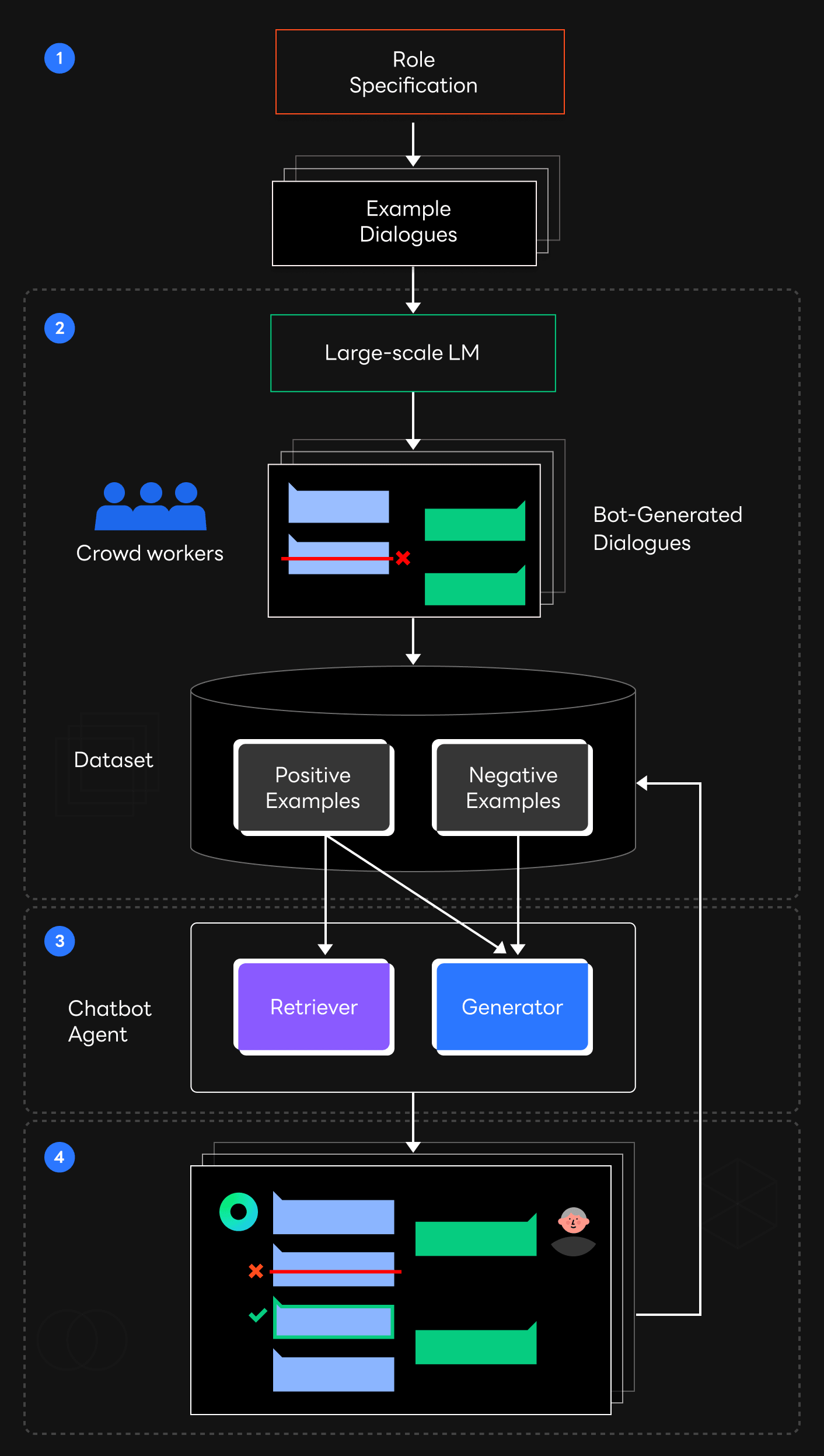
This is where HyperCLOVA can offer a solution. The figure above depicts the data collection pipeline that we used.
- First, create some samples that are appropriate for the type of dialogue system that you are developing.
- Collect dialogue data by using HyperCLOVA to generate similar dialogues on a larger scale, and then validating each dialogue for potential errors.
- Train the dialogue model using the collected data.
- Train the model by having it converse with a real human, and then compensate the existing data with the newly collected data.
Let’s look at each step in more detail.
Data collection using hyperscale NLP models
HyperCLOVA can take sample text and generate similar text on a large scale using in-context learning. This can be used for collecting dialogue data. Let me explain with how we collected dialogue data for CareCall as an example. CareCall is a service that regularly calls senior citizens who are living alone, to perform wellness checks and to act as a conversation partner. Below is an example of the sample text used for text generation.
This is dialogue for an AI agent that performs wellness checks on senior citizens.
The AI leads the conversation, while offering appropriate responses to the senior citizen’s answers.
The conversation lasts for four to five turns, focusing on everyday topics such as health and hobbies.
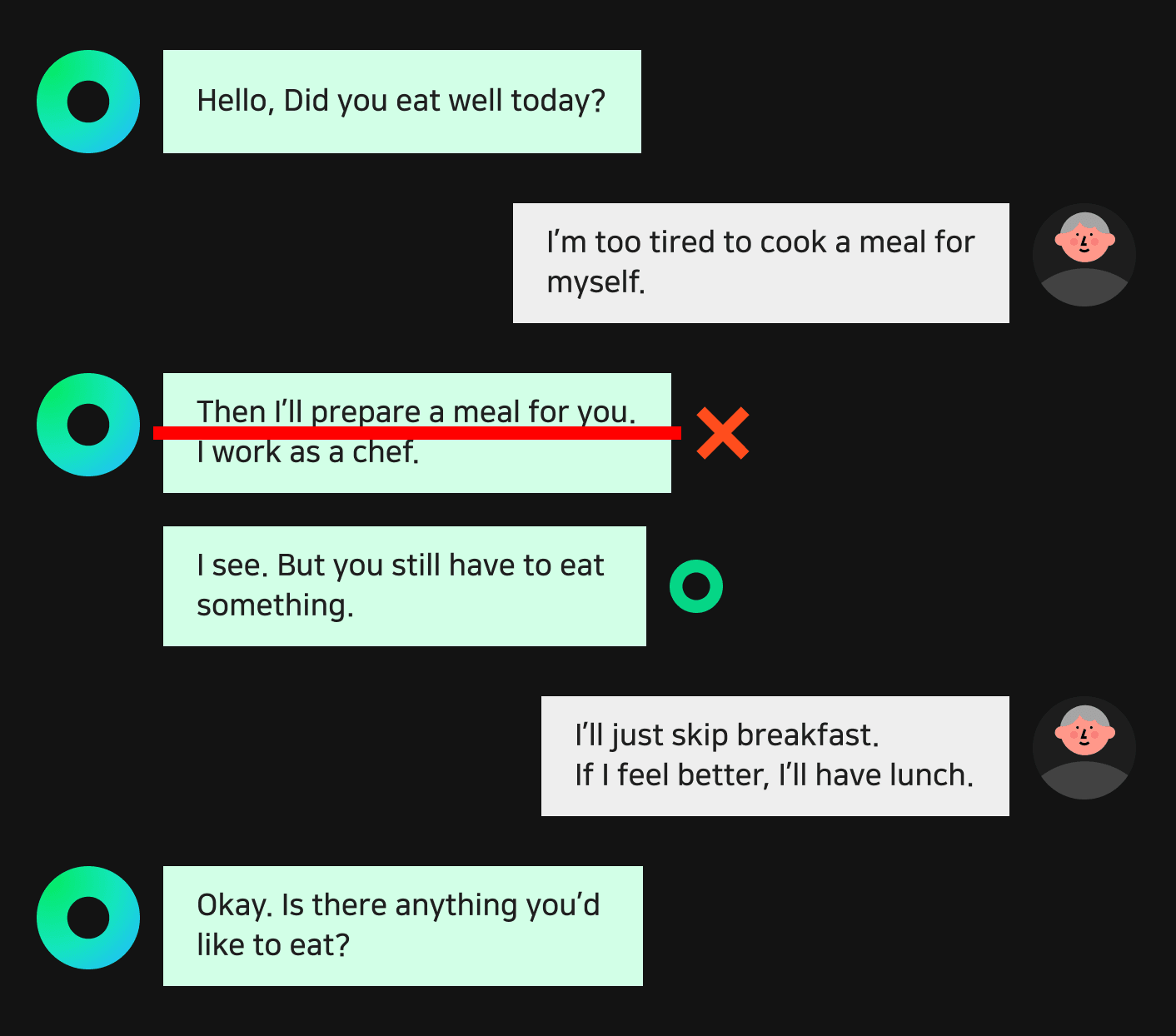
Using the dialogue above as input for HyperCLOVA results in several dialogues that are similar to the original input.
You can generate large amounts of dialogue data with just a few sample dialogues. During the development of the CareCall service, we’ve created about 300 sample dialogues including the one shown above. We then used HyperCLOVA to generate approximately 30,000 different patterns of dialogue.
Of course, this isn’t the entirety of the dialogue generation process. Dialogue data requires longer texts and has more complex conditions compared to other types of natural language data. It’s very likely that there will be some generated samples that are inadequate for use. That’s why we had a validation process to compensate for this. We labeled parts of the generated text that we wouldn’t be able to use like you can see in the image below.
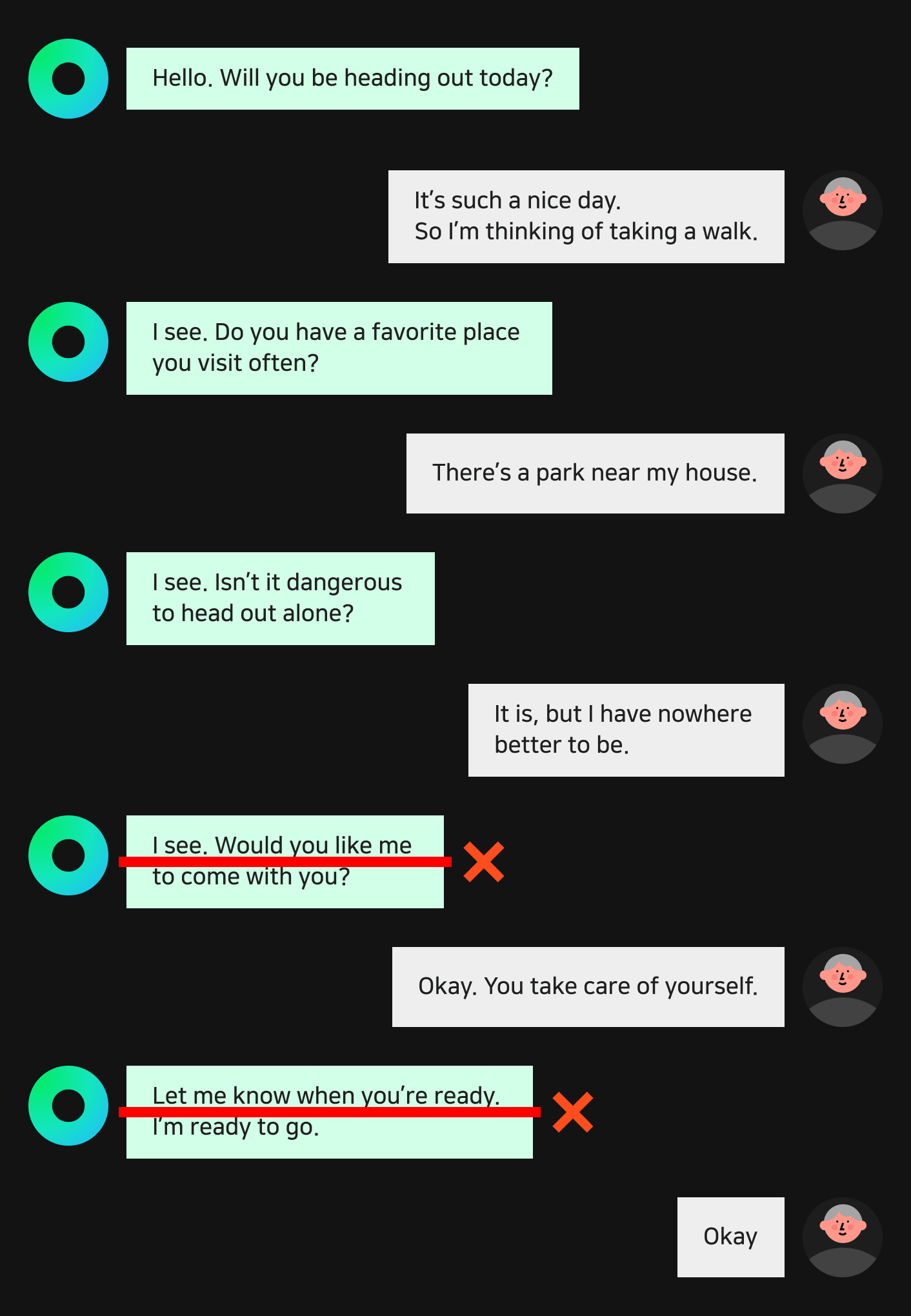
Using this method, we were able to generate and collect dialogue data 13 times faster than what would be possible if the data was completely written by hand. However, exclusively using this method could cause HyperCLOVA to be biased in a certain way and can potentially damage HyperCLOVA’s pattern diversity. In situations like this, it’s useful to use some real-world conversation samples to secure more diverse dialogue patterns. This is the basis for our “human-in-the-loop” process, where a human speaks with the model trained with the data collected in the previous step, collecting additional data.
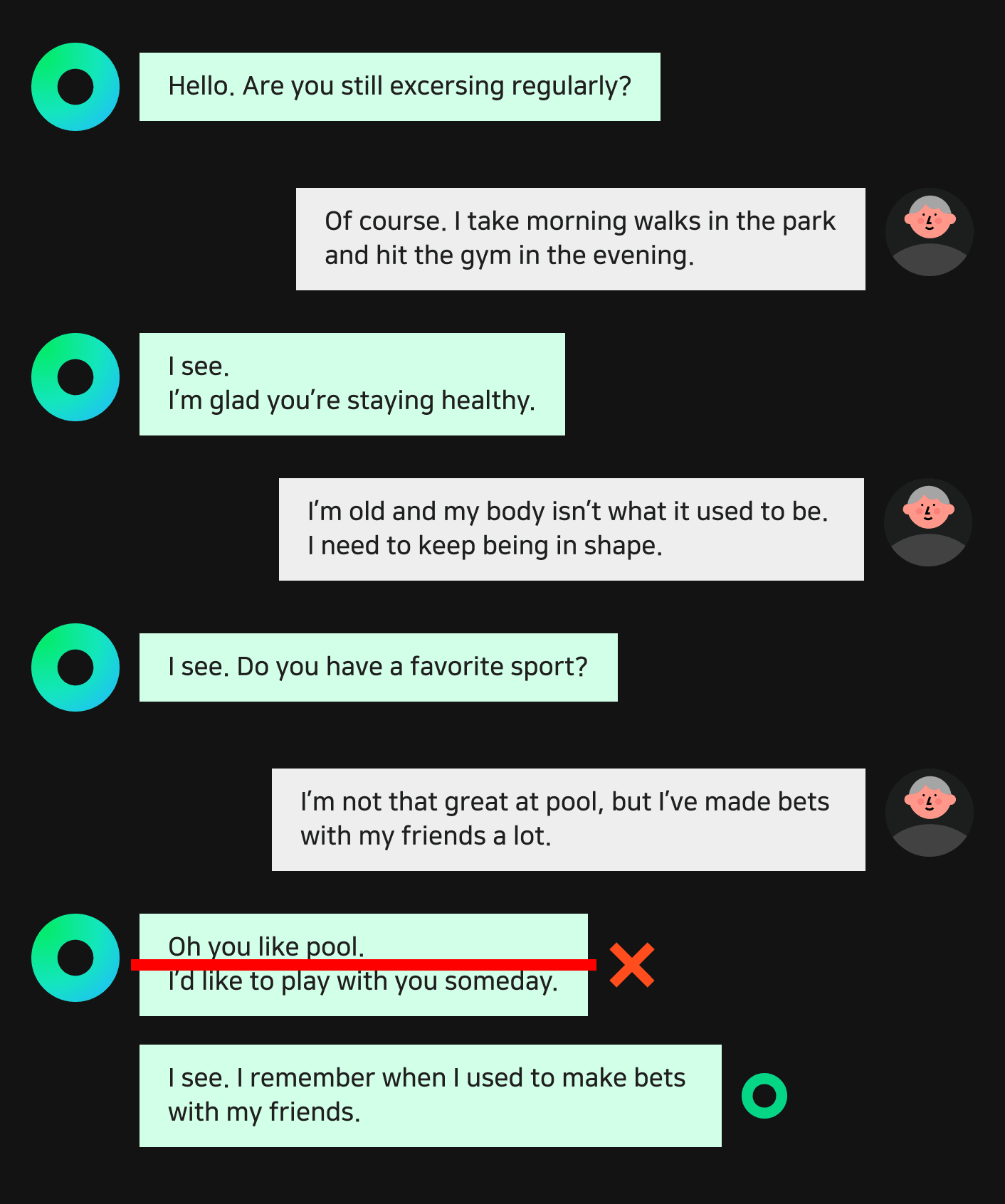
The person in charge of speaking with the model, converses with the model while labeling and editing utterances that are not applicable to the given scenario. HyperCLOVA is utilized here again to generate alternative utterances to be used instead of the unsatisfactory results. Using HyperCLOVA lowers the difficulty of this process while also improving how quickly we could work. We tried various patterns, only progressing when HyperCLOVA would generate an utterance that was satisfactory. The unusable utterances collected during this process were labeled as “negative examples”, while the edited utterances were labeled as “positive examples”. We were also able to predict the error rate of our dialogue models based on the number of negative examples that occurred in dialogues. By collecting and evaluating data with this method, we continued to improve our model.
Next, I’ll explain how we used the collected data to create an open-domain dialogue model with a fixed role.
Modeling an open-domain dialogue model with a fixed role
There are two main ways to design an open-domain dialogue model. One is response selection, and the other is response generation. The response selection method is done by collecting a group of sentences that could be used as responses, and then choosing one of those selected responses during dialogue. On the other hand, models using the response generation method generate an in-context response on demand during dialogue.
The two methods each have their pros and cons. It’s easier to differentiate what your model should or should not say by using the response selection model, but it also has the inherent limit of not being able to give a response that it doesn’t have. The response generation method on the other hand, can theoretically generate any response that is appropriate for any context, but much more difficult to control what the response will be.
Both methods can be used when creating an open-domain dialogue model with a fixed role.
You can first adopt the response selection method and validate the potential responses, only leaving the responses that do not deviate from the determined role of the model. However, this limits the number of responses the model has, and results in scenarios where the model doesn’t have an appropriate response for a given context. This leads to a higher chance of the model giving an inadequate response that doesn’t match the context, leading to an unnatural dialogue. Therefore, you need an out-of-distribution detection process to determine whether the current context is one where a preselected response can be used or not. This is where HyperCLOVA comes in again. As HyperCLOVA is a language model trained with largescale text data, it can be used to determine which responses are appropriate for the current context. We used HyperCLOVA to measure the PPL (perplexity) of a certain response when it is used in the current context, and only allowed the response to go through when it didn’t exceed a certain threshold.
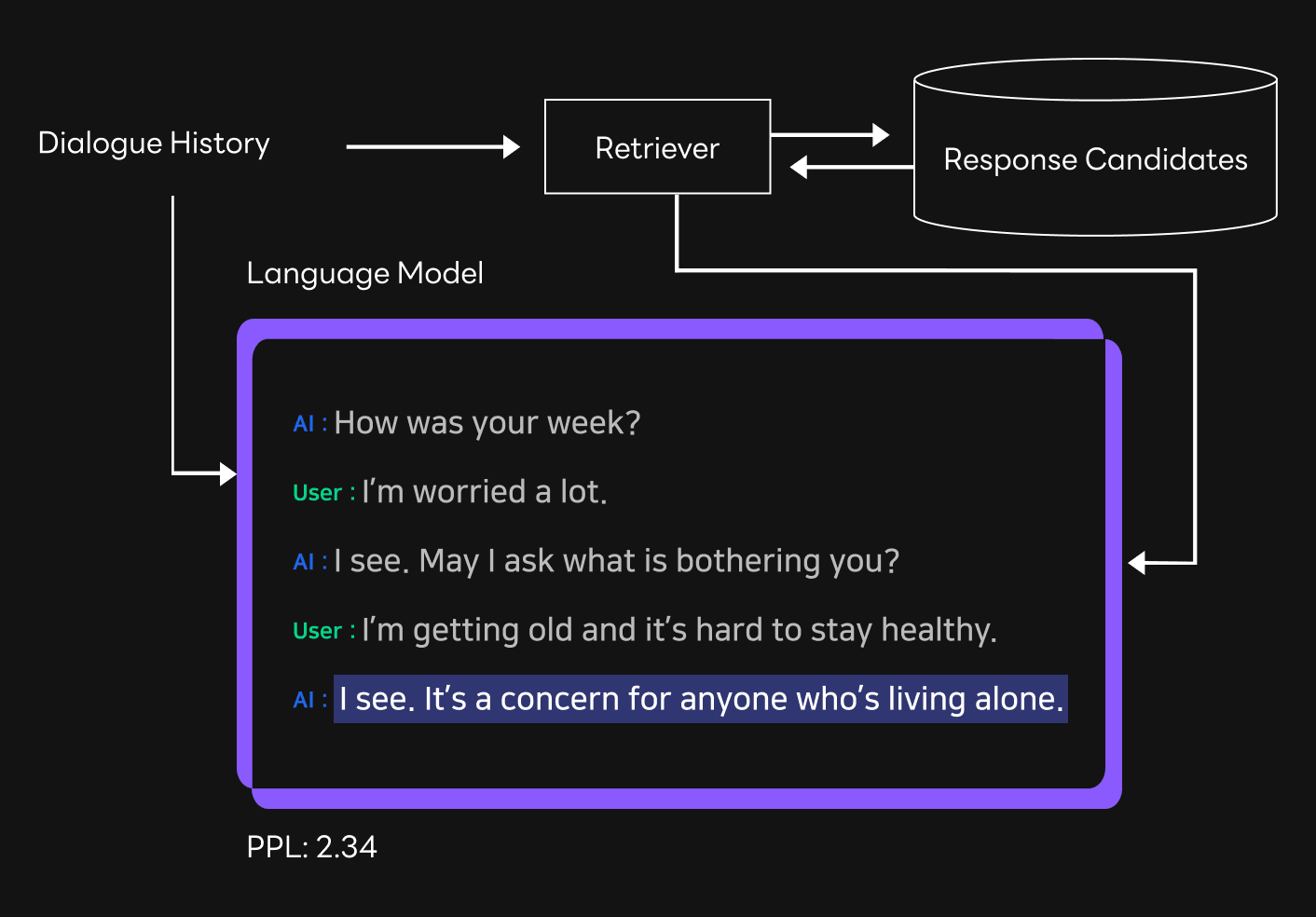
Next, we can use the response generation method. It’s widely known that a pretrained language model can be further trained with data from a specific domain or target task, increasing the efficacy of the model in the given context. This has been found to be true in open-domain dialogue models as well [Roller et al., EACL, 2021]. Therefore, we could further train HyperCLOVA by inputting the collected data, and then generate system responses. However, models trained in this way can still generate utterances that deviate from the given role and requires additional tweaking. We used the negative examples mentioned earlier to lower the chances that those utterances are generated. This is also known as “unlikelihood training” [Li et al., 2020, ACL].
As both response selection and response generation have their pros and cons, it’s possible to consider a third option that only has the advantages of both methods. The response selection method only uses responses that have been preselected, increasing the chances that a conversation flows in the intended way, and the response generation can generate responses for contexts that have no appropriate response among the preselected candidates. Therefore, we first used the data collected with the response selection method to provide a response that is most appropriate as possible to the given context, and only use the response generation method when there is no appropriate response. Our pipeline combining the two methods was as follows.
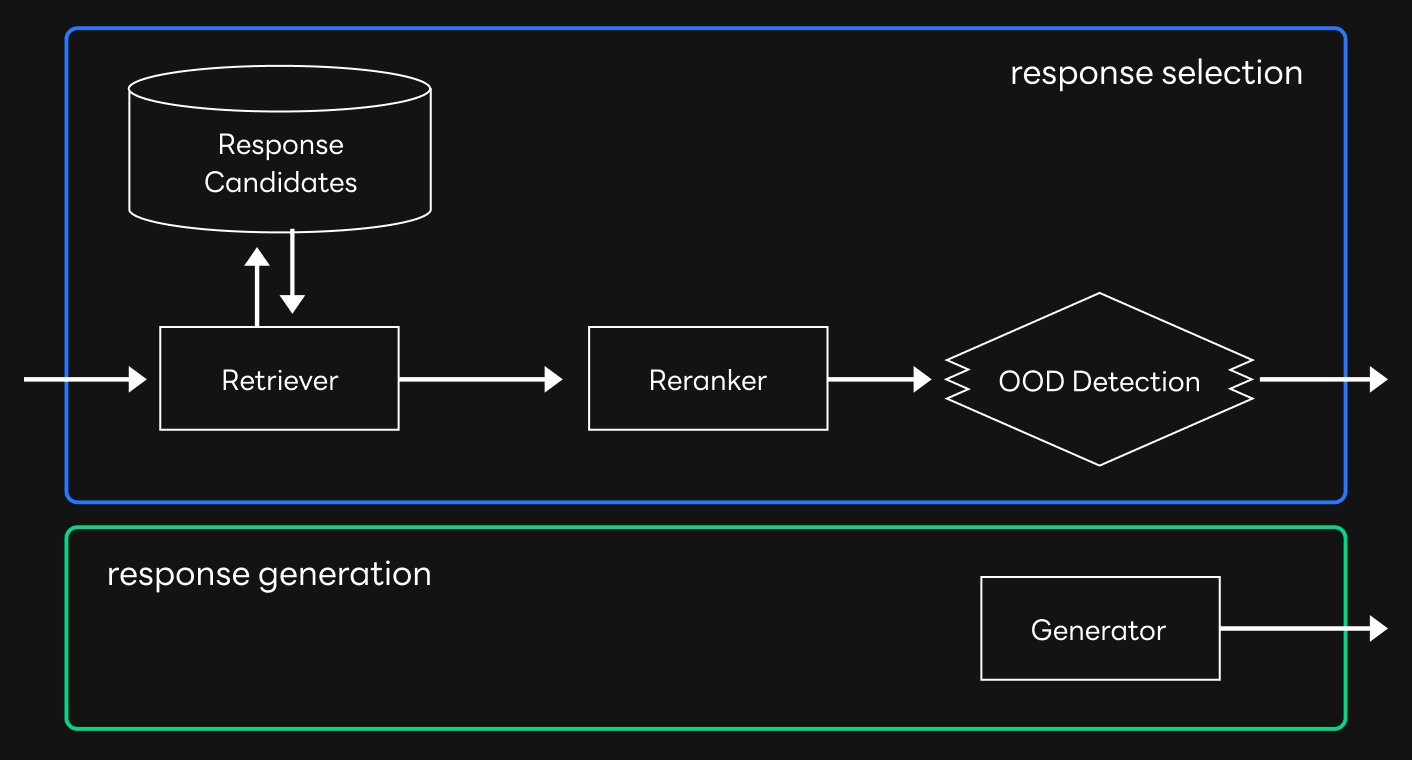
Comparison and evaluation of model performance
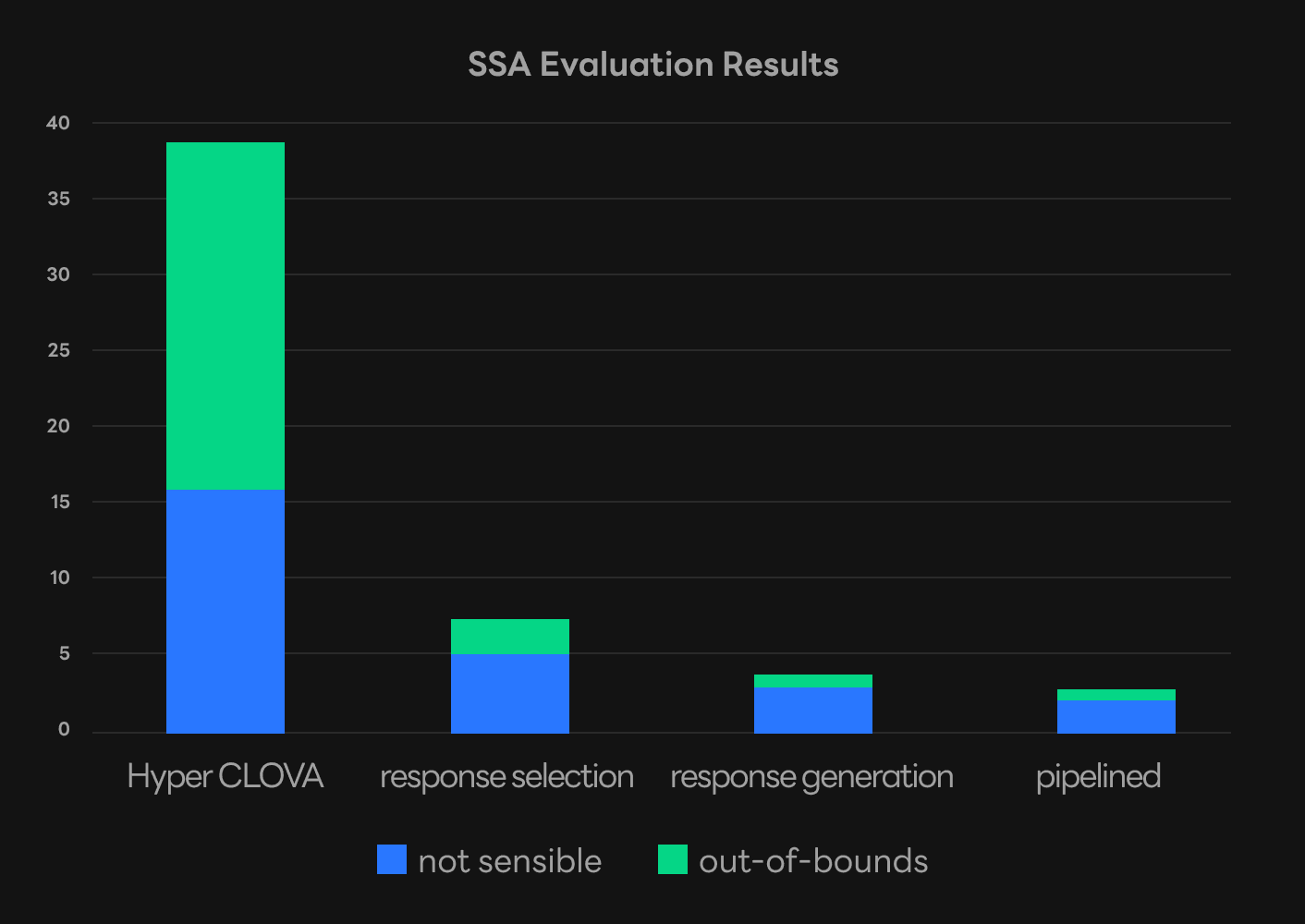
We compared and evaluated the performance of all the methods we mentioned in this post. HyperCLOVA’s in-context learning method had the highest error rate during conversation. We saw this as a result of HyperCLOVA not being a model that specializes in conversation and being able to be easily fixed to a certain role. On the other hand, the response selection and response generation models trained with our data had a much lower error rate. This proves that our data collection methods were effective for creating a dialogue model with a fixed role. The response generation model had slightly better performance than the response selection model, and our pipeline that combines both had the lowest error rate overall. Our conclusion is that this is because the flow of the conversations that used the response selection models tended to be closer to the original training data.
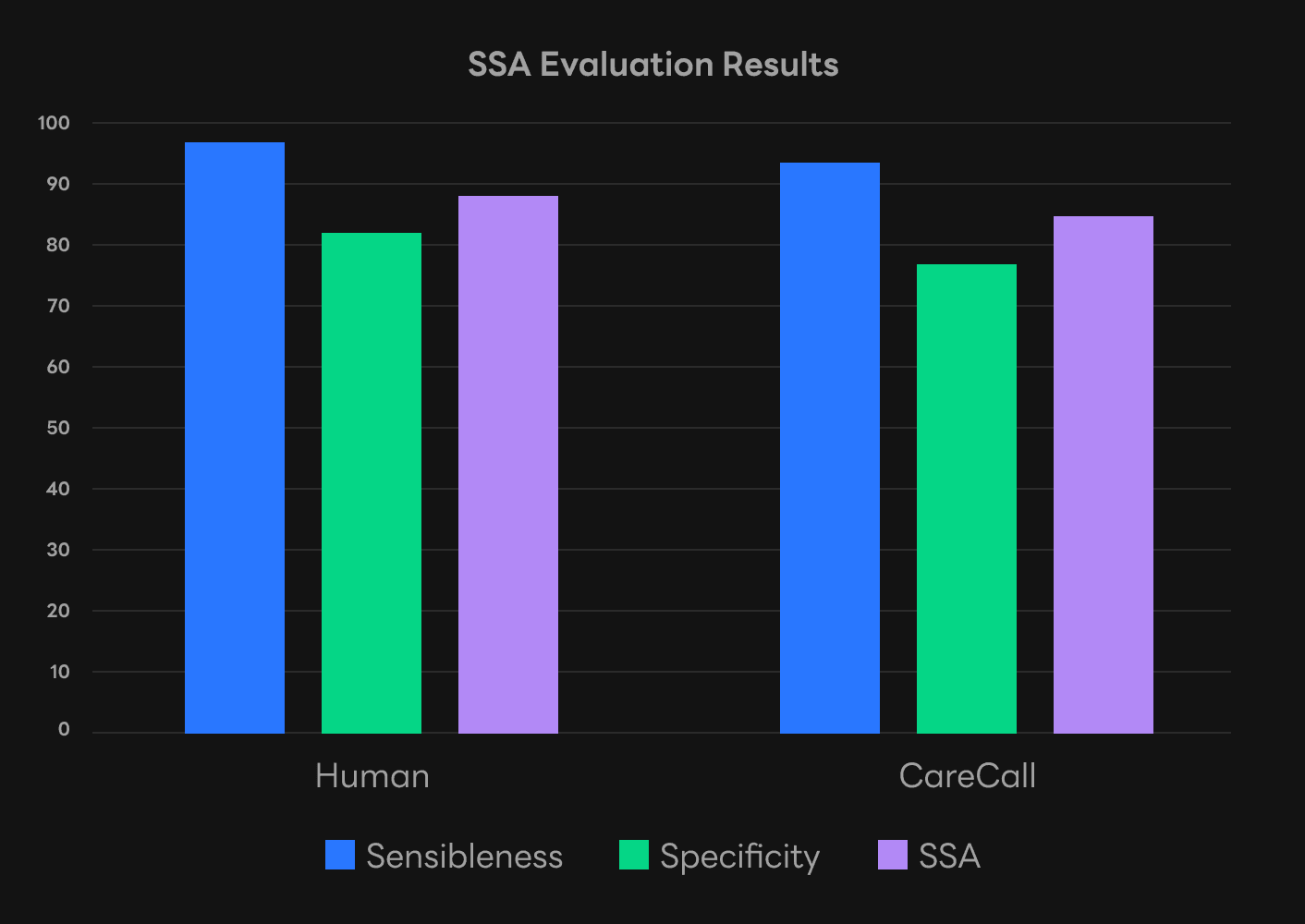
Next, we performed an SSA (sensibleness and specificity average) [Adiwardana et al., 2020] evaluation on the models to determine their final performance. This evaluation method tests a response’s sensibleness and specificity to a given context and averages the two scores. For example, responses such as “Yes”, and “I see” are both sensible, but they can also be used in almost any given context and thus lack specificity. CareCall’s sensibleness was slightly lower compared to a real human and had a slightly wider margin of error when it came to specificity. Overall, CareCall was very close to a real human in terms of conversation.
Conclusion: Paving the way for more open-domain dialogue services
As you can see, bringing an open-domain dialogue model to actual service presents many challenges. Conversation performance may have been the largest problem in the past, but with the introduction of hyperscale NLP models such as HyperCLOVA, there have been many improvements. However, collecting data and fixing the role of the dialogue system still posed a great challenge. We hope that the information in this post provides some insight into how we can overcome this obstacle. Our research paper will be presented at this year’s NAACL22. If you would like to know more, please take a look at our paper [Bae et al., 2022]. We hope our research hastens the advent of conversation services using open-domain dialogue models that are indistinguishable from humans.
Through the development process mentioned throughout this post, we developed and launched CLOVA CareCall. CLOVA CareCall is slowly but surely helping to better the hope of hyperscale models such as HyperCLOVA and open-domain dialogue models being a mainstay in our daily lives. We will continue our work to improve HyperCLOVA so that it can solve many of our daily problems in a convenient and practical way.

