


올해 세계적으로 주목받았던 AI 기술 분야 중 하나가 자연어 처리이며, 그 중심에는 GPT-3가 있습니다. Microsoft가 공개한 AI 프로그래밍 서비스인 Copilot처럼 상상 속 기술이 GPT-3를 통해 현실이 되어가고 있습니다. HyperCLOVA는 클로바에서 학습한 GPT-3 기반의 세계 최초 한국어 초거대형 AI 모델이며, 현재 클로바 스피커나 챗봇 등 네이버의 다양한 AI 서비스에 활용되고 있습니다. 우리는 HyperCLOVA 모델을 실제 서비스에 사용할 수 있도록 다양한 시도를 했고, 좀 더 빠르고 안정적인 서비스를 제공하기 위해 고민했습니다. 서비스를 제공하기 위한 작업은 크게 다음과 같은 5가지 절차로 진행했습니다.
- 프레임워크 선정
- 서빙 환경 구축
- 서비스 기능 구현
- 최적화 포인트
- 운영 자동화
이번 블로그를 포함해 총 세 편의 블로그를 통해 위 절차 중 1번과 3번, 4번에 대해서 상세하게 다뤄보려고 합니다.
Part 1: 프레임워크 선정
모델 서빙 속도를 높이기 위한 프레임워크 선정
HyperCLOVA 모델을 서빙하면서 중요하게 생각했던 부분 중 하나는 서비스의 속도입니다. HyperCLOVA 모델은 더 좋은 품질과 성능을 위해 점점 크기가 커지고 있는 추세이고, 이에 따라 더 많은 메모리를 소비하며 연산량이 증가하고 있습니다. 큰 모델을 서빙하는 과정에서 발생하는 GPU 간의 데이터 이동량과 연산량 증가 때문에 지연 시간(latency)은 상당히 길어질 수밖에 없었습니다. 실제로 초거대 모델을 서비스에 사용하기 위해서는 GPU 종류에 따라 최소 2배에서 3배까지 속도를 높일 필요가 있었습니다.
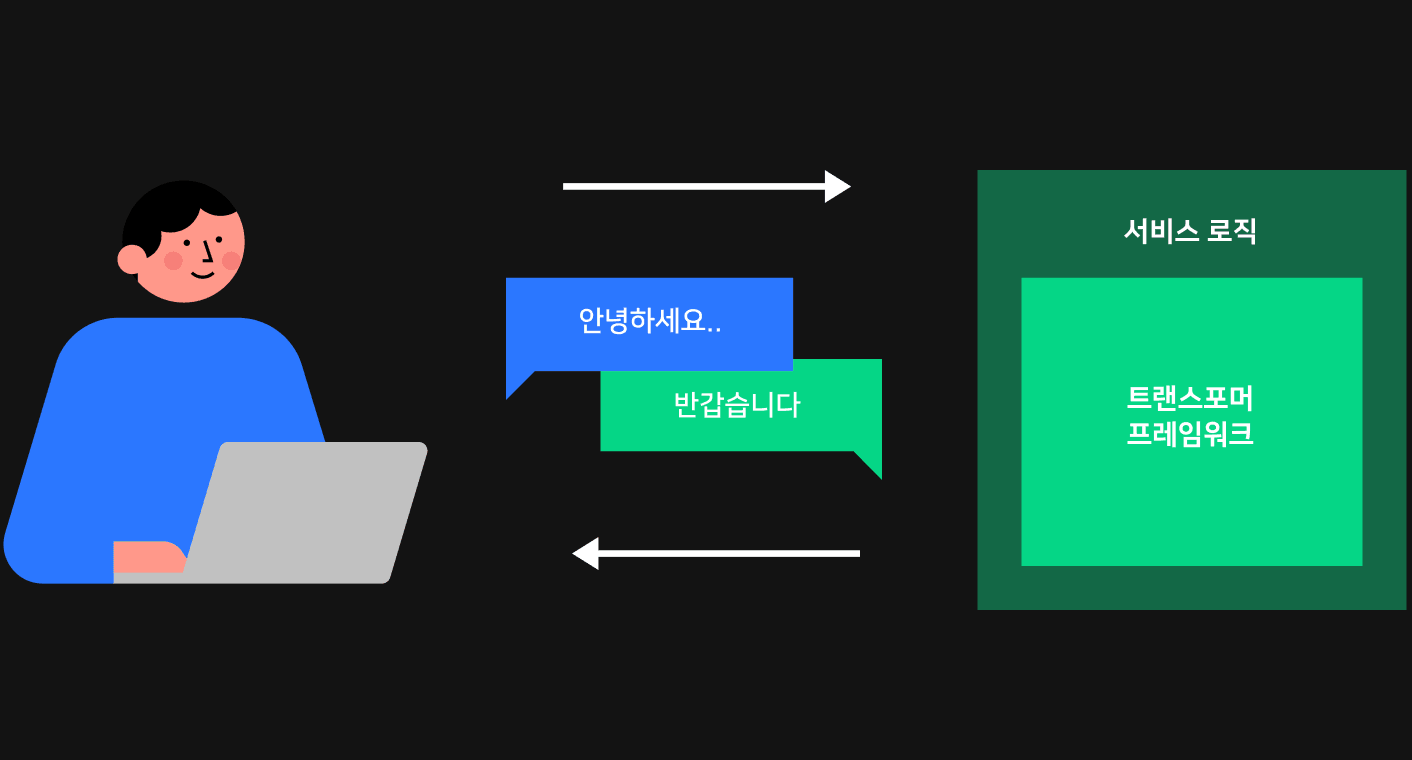
HyperCLOVA 모델의 서빙 속도를 높이기 위해서는 우선 가장 아랫단에서 연산을 최적화해야 한다고 생각했습니다. 서빙 과정은 아래 그림과 같이 크게 내부의 트랜스포머 프레임워크와 바깥의 서비스 로직으로 나뉩니다. HyperCLOVA와 같은 GPT 모델은 트랜스포머 기반으로 연산이 진행되며, 이 과정을 통해 텍스트를 생성할 수 있는 프레임워크가 필요합니다. 트랜스포머 프레임워크에서 텍스트가 생성된 이후에는 서비스 로직을 통해 해당 결과를 사용자에게 전달하는데요. 사용자에게 응답을 주기까지 걸리는 시간의 대부분은 트랜스포머 프레임워크에서 소요되기 때문에 프레임워크에서 연산 시간을 단축시키는 것이 근본적으로 속도를 높일 수 있는 중요한 지점이었습니다.
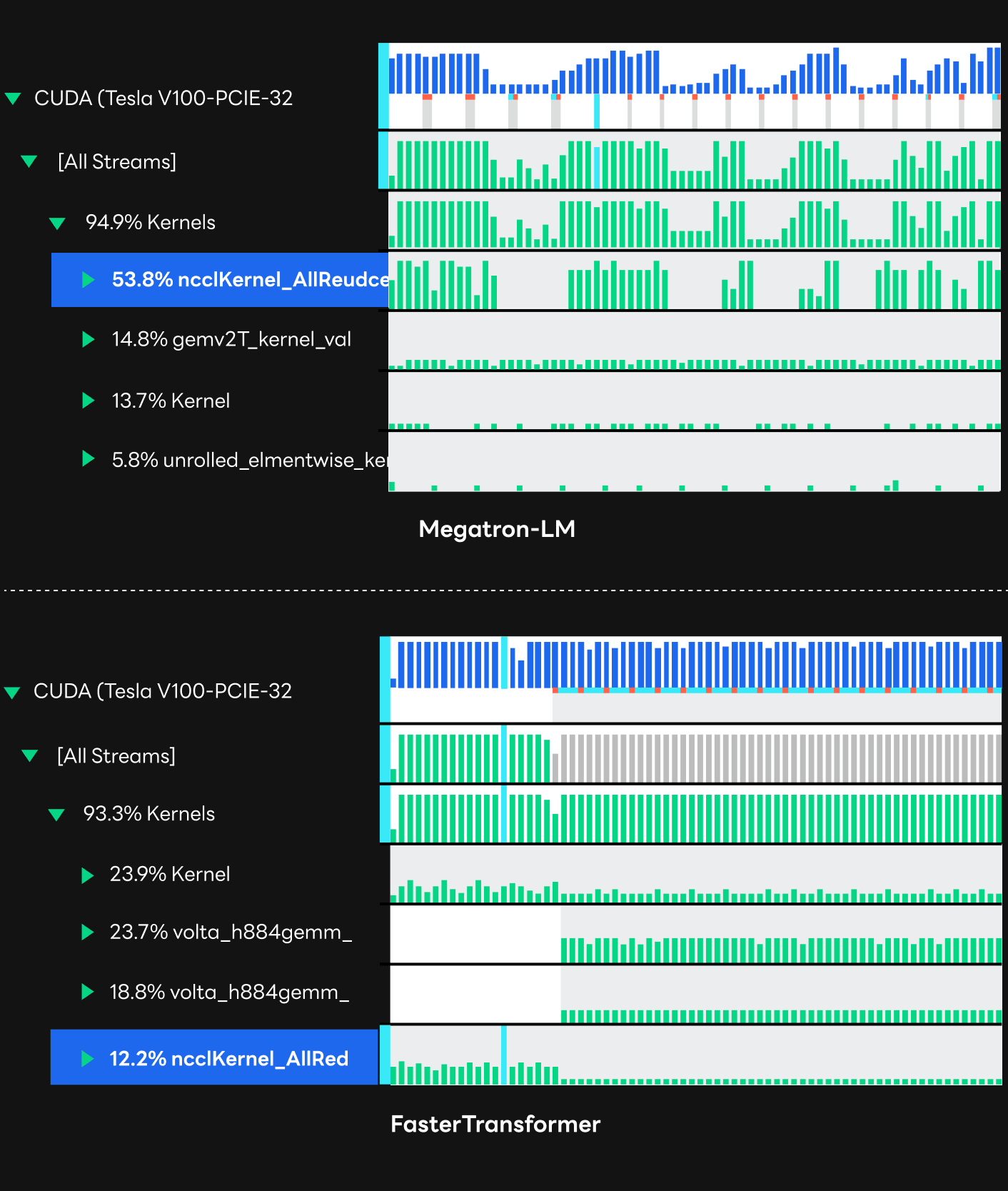
기존 HyperCLOVA 서빙은 트랜스포머 프레임워크로 모델을 학습할 때 사용한 NVIDIA의 Megatron-LM을 그대로 사용하고 있었습니다. 학습에서 사용하던 방식대로 프레임워크를 이용해 원하는 서비스를 상대적으로 쉽게 구현할 수 있다는 장점이 있었지만, 해당 프레임워크는 지연 시간이 중요한 추론(inference)에 최적화된 구현이 아니었습니다. 실제로 Nsight Systems를 통해 추론 연산의 프로파일링 결과를 보면, GPU 리소스를 잘 쓰지 못해 활용도(utilization)가 상당히 낮게 나오는 것을 확인할 수 있습니다. 또한 아래 프로파일링 결과에서 ncclKernel로 나타나고 있는, 멀티 GPU 간의 데이터 취합 과정에 상당히 많은 오버헤드가 발생하고 있다는 것을 발견했습니다.
FasterTransformer 도입
실질적으로 서빙 과정에서는 학습에서 필요한 전 과정이 모두 필요한 것은 아닙니다. 추론만 진행할 수 있으면 됩니다. 따라서 학습에서 사용하는 프레임워크가 아닌, 추론 서비스에 최적화된 프레임워크를 적용해 보고 싶었습니다. 이에 기존 프레임워크를 NVIDIA의 GPT 추론용 프레임워크인 FasterTransformer로 대체해 보기로 했습니다. FasterTransformer는 PyTorch가 아닌 C++과 CUDA 네이티브 커널로 작성되어 있고, kernel fusion 등 CUDA 커널 레벨 최적화 기법이 적용되어 있습니다. 이런 구현 방식 덕분에 GPU를 더 효율적으로 사용하면서 서빙 과정에서의 지연 시간이 줄어들기를 기대했습니다.
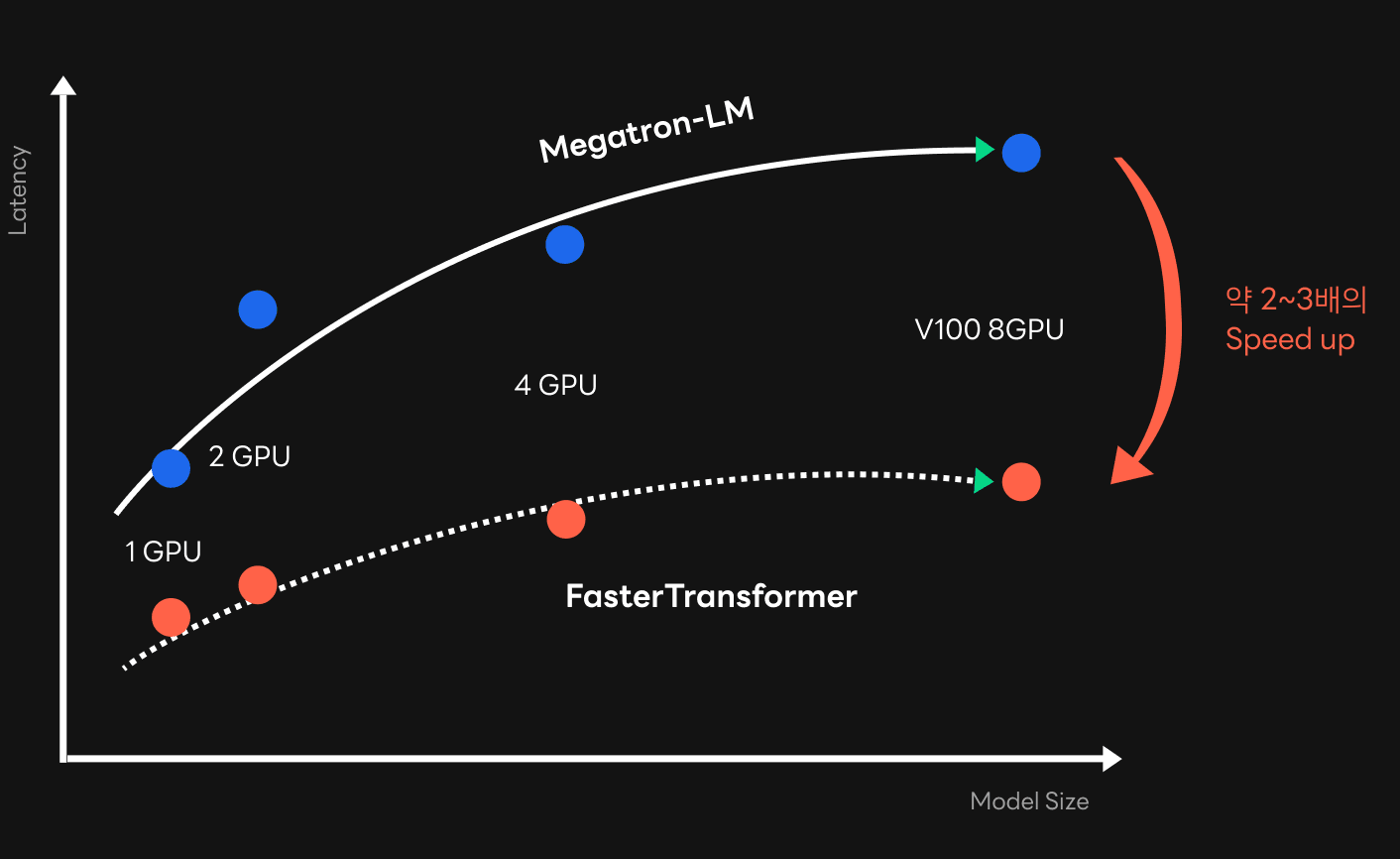
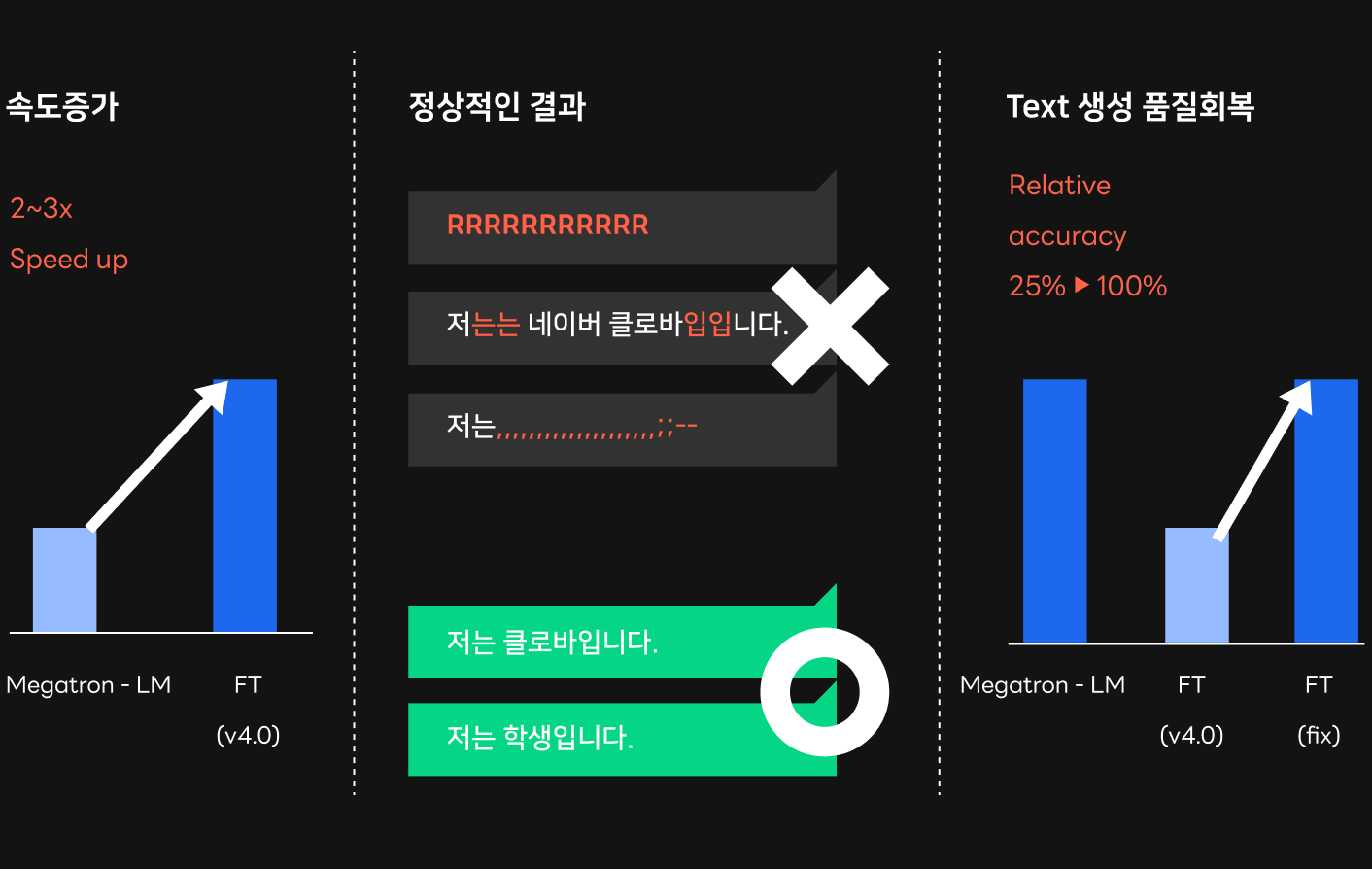
기존 프레임워크를 FasterTransformer로 대체해 본 결과, 속도 측면에서 상당히 성공적이었습니다. 모델의 크기에 따라 차이가 있지만 아래 모델 크기별 지연 시간 그래프에서 볼 수 있듯 최종적으로 학습에 사용한 프레임워크 대비 약 2배에서 3배까지 속도 향상이 가능했습니다. 이와 같은 속도 향상 덕분에, 특히 크기가 큰 모델에서도 서비스에 적용 가능한 목표 속도치를 달성할 수 있었습니다. HyperCLOVA 모델이 문장 생성 품질을 향상시키기 위해 점점 커지는 추세라는 것을 고려할 때 매우 유의미한 성과였습니다. Nsight Systems로 프로파일링한 결과를 보면, 기존 프레임워크와 비교해 FasterTransformer에서 어떤 점이 나아졌는지 확인할 수 있습니다. 프로파일링 결과에서 알 수 있듯이 기존 프레임워크 보다 GPU 리소스를 효율적으로 사용하고, 활용도 또한 상당히 높게 나타났습니다. 또한, 기존 Megatron-LM 프레임워크에서 문제가 되었던 GPU 간의 데이터 취합 과정(NCCL 커널)의 오버헤드가 FasterTransformer에선 상대적으로 매우 적게 나타났습니다.
FasterTransformer 도입 후 발생한 문제 및 해결 과정
FasterTransformer를 서비스에 바로 적용하기 위해서는 해결해야 할 문제들이 있었습니다.
먼저 프레임워크와 서비스 로직 사이의 인터페이스를 수정해야만 했습니다. 기존 프레임워크는 대부분의 기능이 PyTorch로 구현되어 있었고, 서비스 로직에서 API 수정이 수월한 형태였습니다. 하지만 FasterTransformer의 경우에는 대부분의 기능이 공유 라이브러리(shared library) 형태로 만들어져 있고, 서비스 로직에서 연산 결과에 대해서만 제한적으로 접근할 수 있는 API로 제공되기 때문에 이에 맞게 서비스 로직과 프레임워크 사이의 인터페이스를 수정해야 했습니다.
다음으로 우리가 사용했던 FasterTransformer v3.0과 v4.0에서는 정합성 문제가 발생해 서비스에 바로 적용하기 어려운 점이 있었습니다. 여기서 정합성 문제는 잘못된 연산 때문에 완전히 잘못된 단어들 혹은 품질이 훼손된 단어들이 생성되는 문제를 지칭합니다. 아래 그림과 같이 입력에 맞는 적합한 문장을 생성하는 것이 아니라 잘못된 단어들이 출력되는 문제가 발생했습니다.

정합성 문제를 발생시킨 요인에는 여러 가지가 있었습니다. 크게 몇 가지를 구분해 보자면, 체크포인트 변환 문제, FP16 연산 과정에서의 문제, GPU 커널에서 버그가 발생하는 문제들이 있었습니다.
체크포인트 변환 문제 해결
체크포인트 변환과 관련된 문제는 앞에서 설명한 프레임워크 변경 과정과도 연관이 있는 내용입니다. FasterTransformer는 추론 연산만 제공하고 모델을 학습시키는 과정은 제공하지 않습니다. 우리는 HyperCLOVA 모델을 학습시키는 데 사용한 Megatron-LM에서의 체크포인트(weight와 bias 등을 포함)를 사용해야 했고, FasterTransformer에 맞게 Megatron-LM에서의 체크포인트를 변환해야 했습니다. 기존 FasterTransformer에서 제공하는 코드를 이용해 체크포인트를 변환했고, 이 결과를 이용해 문장을 생성했지만, 완전히 품질이 훼손된 단어들만 생성되었습니다.
처음에는 어디서 문제가 생긴 건지 정확히 인지하지 못했지만, NVIDIA에서 릴리스한 과거 GPT-2 모델의 경우에는 문제없이 실행되었는데 네이버에서 학습시킨 HyperCLOVA 모델은 문제가 발생한다는 점에서 해결 포인트를 찾을 수 있었습니다. HyperCLOVA 모델의 경우, 기존 NVIDIA의 GPT-2 모델과 다른 방식으로 체크포인트를 사용하기 때문에 저장되는 체크포인트의 인덱싱이 기존 방식과 달랐습니다. FasterTransformer를 위한 체크포인트 변환 과정에서 이런 점을 고려해야 했는데 업데이트하지 않았던 것입니다. 이 문제는 Megatron-LM에서의 연산 과정을 역으로 생각해 체크포인트 변환 과정을 수정하는 것으로 해결했습니다.
Deep dive into GPT-3 with FP16
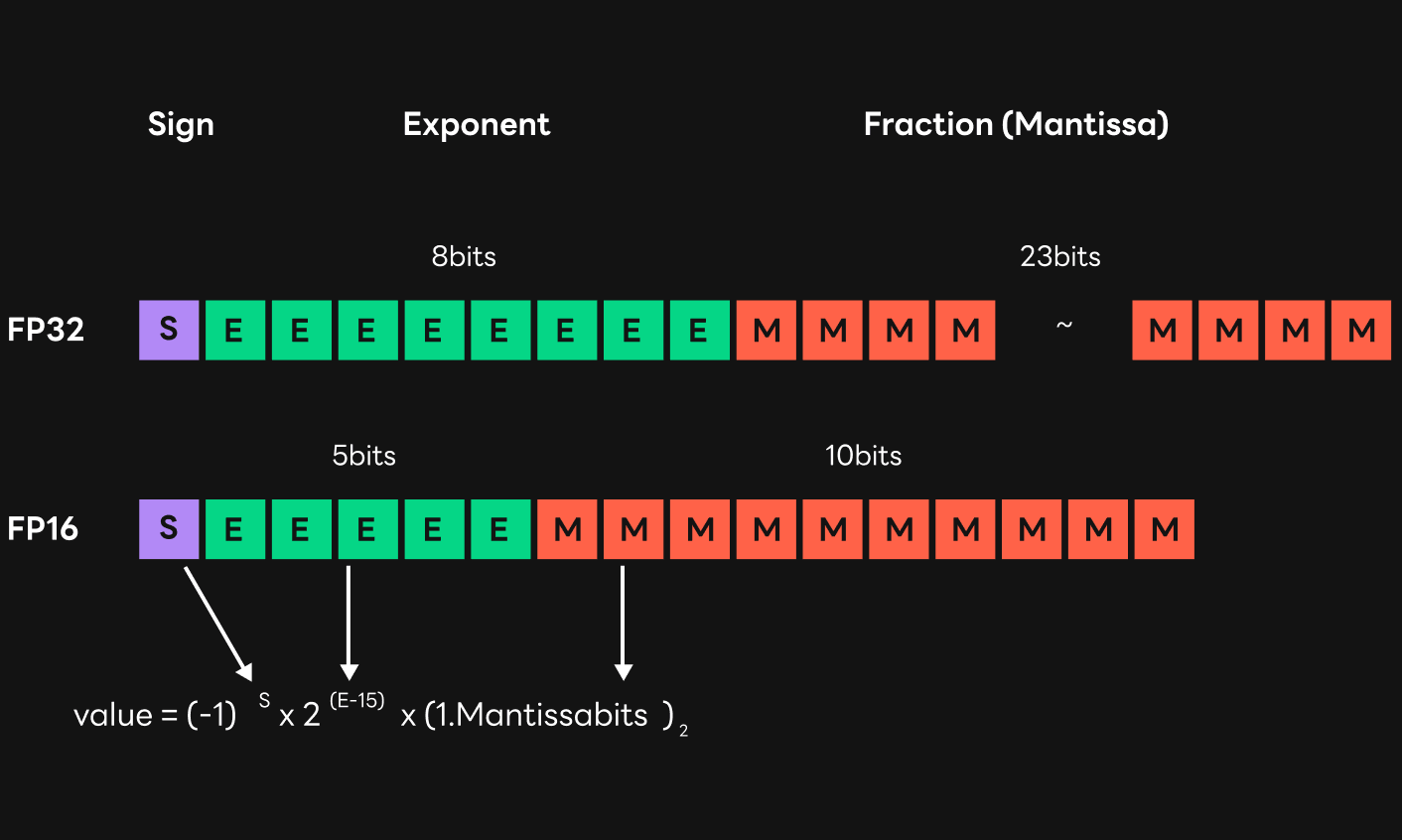
다음으로 FP(floating-point)16 타입 연산으로 인해 발생한 문제를 살펴보겠습니다. HyperCLOVA 모델은 서빙 속도를 높이기 위해 FP32 타입이 아닌 FP16 타입으로 진행됐습니다. FP16 타입으로 연산했을 때, HyperCLOVA 모델의 경우 FP32 타입 대비 약 3-4배 빠른 결과를 보여주었습니다. 학습 및 추론에 걸리는 시간을 줄이는 것이 매우 중요했기 때문에 FP16 타입을 이용한 연산은 필수였지만, FP16의 경우 FP32 타입에 비해 표현할 수 있는 범위가 좁아지고 정밀도가 낮아지기 때문에 발생하는 문제들이 있습니다.
우선, HyperCLOVA 모델의 크기가 클 때, FP32 타입으로 연산할 때는 문제가 없었으나 FP16 타입으로 연산하면서 품질이 많이 훼손되는 현상이 발생했습니다. 이는 FP16으로 연산하는 과정에서 오버플로가 발생해 데이터들의 값이 inf나 NaN(Not a Number)으로 귀결되었기 때문입니다. FP32의 경우 exponent bit가 8개로 최댓값은 3.40*e38입니다. 반대로, FP16의 경우 exponent bit가 5개로 FP32 대비 적고, 최댓값은 65504 정도로 오버플로 문제에 상대적으로 취약할 수밖에 없습니다.
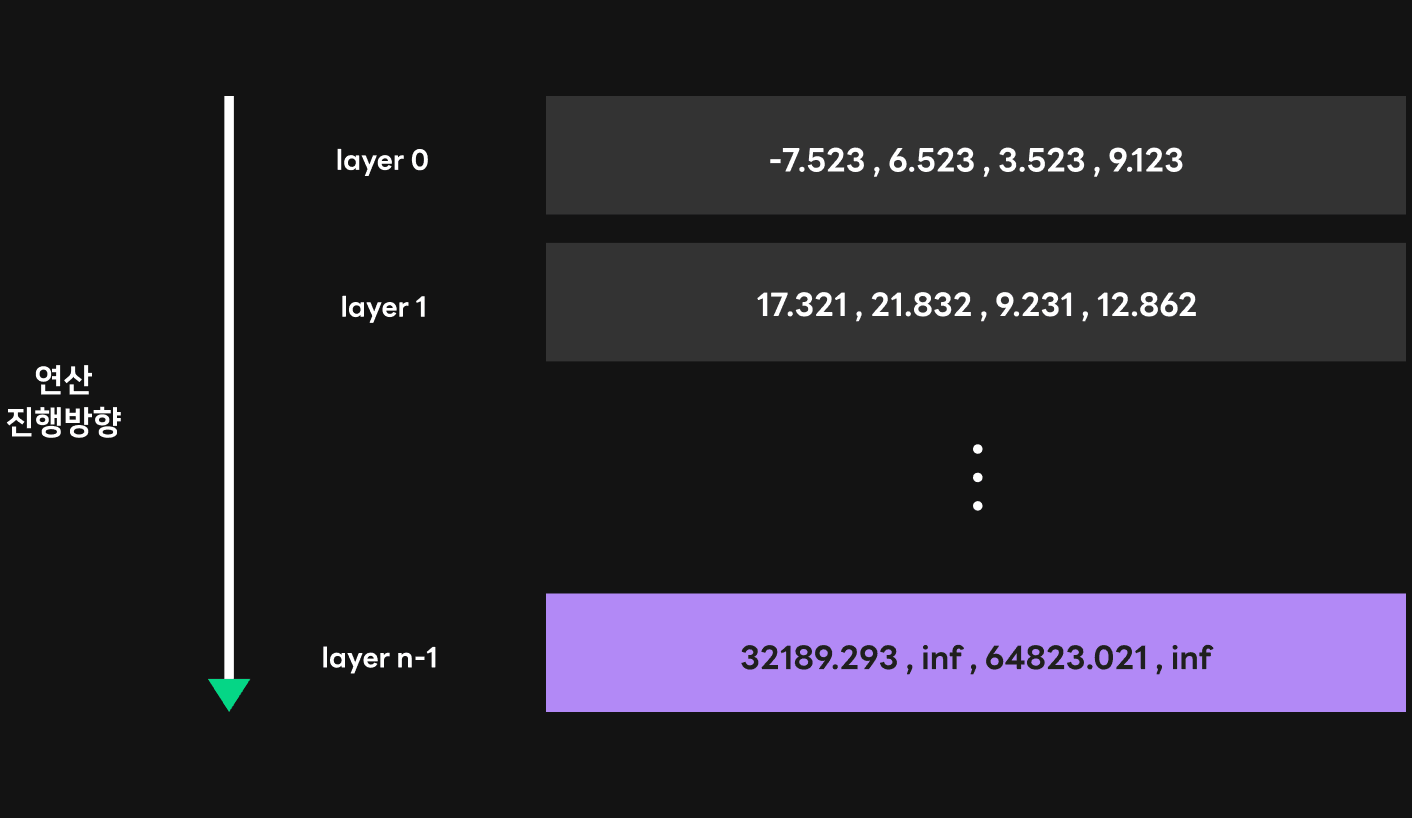
GPT 연산을 단순히 표현하면 아래 그림처럼 여러 트랜스포머 레이어에서 순차적으로 연산이 진행되고, 각 레이어 내부에서는 GEMM(GEneral Matrix-to-matrix Multiply), 즉 행렬 곱셈 연산이 진행됩니다. 이 과정에서 첫 번째 레이어에서의 GEMM 연산의 결괏값은 대체로 작은 값이지만 뒤쪽 레이어로 갈수록 점점 이 값이 커지는 경향이 있습니다. 모델이 클수록 레이어 개수가 많고, 각 레이어에서의 데이터 크기도 커지면서 뒤쪽 레이어에서 큰 값이 발생하며 오버플로 현상이 일어날 확률이 높습니다. 오버플로가 발생해 결국 연산 결괏값에 inf 값이 섞이면, 특정 시점 이후에서는 잘못된 단어들만 연속적으로 생성되는 일이 벌어집니다.
이때 취할 수 있는 해결책은 많지 않습니다. 우선 inf 값이 나타난 경우를 감지할 수 있다면 그 값을 inf 값이 아닌 FP16의 최댓값인 65504로 바꾸는 방법이 있습니다. 또 다른 방법은 오버플로가 발생할 가능성이 큰 GEMM 커널의 데이터 타입과 연산 타입을 FP32로 바꿔 기본적으로 오버플로가 발생할 확률을 낮추는 것입니다. 전자의 방법은 NVIDIA의 cuBLAS GEMM 커널을 사용하고 있어서 결괏값을 바꾸는 것 자체가 불가능했기 때문에 후자의 방법을 사용해 오버플로가 발생하는 GEMM 커널의 연산 결괏값이 FP32 데이터 타입으로 저장되게 했습니다. 이렇게 설정하면 중간 결괏값들도 FP32로 저장되기 때문에 오버플로 발생을 피할 수 있습니다.
FP32 타입에 비해 FP16 타입은 앞서 오버플로 문제와 관련있었던 exponent bit뿐 아니라, fraction bit라고도 부르는 mantissa bit의 개수도 매우 적습니다. Mantissa bit는 부동 소수점 데이터의 가수부에 해당하는 값으로, 개수가 적을수록 표현할 수 있는 소수점 이하 숫자의 개수가 적어집니다.
위와 같은 FP16 데이터 타입의 특성은 GPT 연산에서 ‘swamping’이라는 현상을 발생시킬 수 있습니다. Swamping은 큰 값과 작은 값을 더할 때 작은 값이 마치 큰 값의 늪에 빠지듯이 값이 유실되는 현상입니다. 값이 유실되는 이유는 다음과 같습니다.
부동 소수점 타입의 덧셈은 두 값의 exponent bit를 동일하게 맞추는 것으로 시작합니다. 이때 작은 값의 exponent bit를 큰 값의 exponent bit로 맞춰야 합니다. 이 과정에서 작은 값은 exponent bit를 바꾸기 전과 후의 값을 동일하게 유지하기 위해서 mantissa bit를 적절하게 이동시켜 주어야 하는데요. 이때 mantissa bit의 오른쪽에 위치한, 가수들의 일부를 나타내고 있던 값들이 소멸되어 버립니다. 아래 그림은 이러한 상황의 예시를 보여주고 있습니다. 연산 과정을 보면, 큰 값인 3.75에 상대적으로 작은 값인 0.00098을 더하고 있는데요. 연산 결과가 3.75098이 아닌 3.75로 나옵니다. 큰 값과 작은 값의 exponent bit을 맞추는 과정에서 FP16의 적은 mantissa bit 개수 때문에 0.00098이란 값이 덧셈 결과에 반영되지 못한 것입니다. FP32 데이터 타입의 mantissa bit는 FP16 데이터 타입의 mantissa bit와 비교해 개수가 2배 이상이기 때문에 이 과정에서 유실되는 데이터 값의 비중이 작지만, FP16 타입에서는 상당한 비중에 해당하는 값이 유실될 가능성이 있습니다. Swamping 현상으로 발생하는 데이터 유실 문제는 더하고자 하는 값의 차이가 클수록 발생 가능성이 높아집니다. 이런 이유 때문에 학습 단계에서 weight 분포가 고르지 못하다면 swamping 현상으로 인한 문제가 심화될 가능성이 커집니다. 또한 GPT 모델의 전체 연산 과정을 생각해 보면, GPT는 레이어 개수가 많고, 앞 레이어의 연산 결과가 뒤 레이어에서 사용되기 때문에 뒤쪽 레이어로 갈수록 swamping으로 인한 오차는 점점 누적됩니다.

FP16 연산 과정에서 발생하는 swamping 현상 때문에 HyperCLOVA와 같은 GPT-3 모델에서 두 가지 문제가 발생할 수 있습니다. 먼저, 위에서 설명한 데이터 유실 때문에 기존 FP32 연산과는 다른 결과 혹은 조금 품질이 훼손된 텍스트가 생성될 가능성이 있습니다. 다음으로, 특정 옵션을 사용해 동일한 입력에 대해 동일한 단어가 생성되기를 기대하는 상황에서 트랜스포머 연산이 싱글 배치로 수행되는지 멀티 배치로 수행되는지에 따라 다른 결과가 나올 수 있습니다. 여기서 특정 옵션은 greedy 옵션을 가리키는데요. Greedy 옵션을 사용할 때는 결과가 임의의 값에 영향받지 않고 동일한 입력 문장에 대해서는 동일한 문장 및 단어가 생성되기를 기대하지만, FP16 타입 연산에서 발생할 수 있는 swamping 효과로 인해 greedy 옵션을 주어도 다른 결과가 나올 수 있습니다.
이러한 문제를 해결하기 위해, cuBLAS GEMM 커널의 데이터 타입은 FP16을 그대로 사용하지만, 컴퓨트 타입을 FP32로 설정해 주었습니다. 입력 데이터 타입이 FP16이라고 하더라도 컴퓨트 타입을 FP32로 설정하면, 중간 덧셈 과정들이 FP32 데이터 타입에 저장되며 이를 통해 mantissa bit을 충분히 확보할 수 있기 때문에, swamping으로 인해 유실되는 데이터 값의 정도를 완화시킬 수 있었습니다. 결과적으로, greedy option으로 실행 시 swamping 효과 때문에 싱글 배치와 멀티 배치에서의 수행 결과가 달라지는 빈도 또한 줄어드는 것을 확인하였습니다.
결과 정리
앞서 말씀드린 문제 외에도 GPU 커널 내부의 잘못된 인덱싱들, 레이스 컨디션(race condition), 메모리 누수 등의 버그를 해결한 후에야 비로소 FasterTransformer를 안정적으로 서비스에 이용할 수 있었습니다. 결과적으로 Megatron-LM 대신 FasterTransformer를 서비스에 이용하면서 모델의 크기나 GPU 환경에 따라 약 2배에서 3배까지 서비스 속도를 높일 수 있었습니다.
FasterTransformer의 정합성 문제 해결 과정을 요약하면, 작업 초기에 FasterTransformer 버전에서 잘못된 결과가 발생하는 문제를 바로잡았고, 특정 모델에서 Megatron-LM 대비 상대적인 정확도가 75%나 떨어졌던 문제도 해결했습니다. 이를 통해 Megatron-LM 수준의 텍스트 생성 품질을 기대할 수 있게 되었습니다.
정합성 문제를 해결한 결과는 오픈 소스 기여를 통해 FasterTransformer v5.0 beta 버전에 적용되었습니다. 관련 내용은 DEVIEW 2021 발표(https://deview.kr/2021/sessions/416)에서도 자세히 다루었으니 참고하시기 바랍니다.

