


Part 2: 서비스 기능 구현
Introduction
이번 글은 총 세 편으로 나눈 HyperCLOVA 서빙기의 두 번째 편으로, HyperCLOVA를 이용한 서비스 기능을 구현했던 경험을 다뤄보고자 합니다. 먼저 첫 번째로 클로바 AI 스피커와 같이 HyperCLOVA를 이용하는 네이버 서비스 패턴에서 사용자에게 좀 더 빠른 응답을 전달하기 위해 구현했던 Early Stop 기능을 소개하겠습니다. 두 번째로 어떻게 문장 생성 모델인 HyperCLOVA 모델을 활용해 문서들 간의 관련도를 분석하는 기능인 시맨틱 검색(semantic search)을 제공할 수 있었는지 다루겠습니다. 마지막으로 같은 크기의 모델로도 좀 더 높은 성능을 낼 수 있는 방법인 프롬프트 튜닝(P-Tuning)을 어떻게 서빙 환경에 적용할 수 있었는지 설명 드리겠습니다. 글은 다음과 같은 순서로 진행하겠습니다.
- Early Stop
- 시맨틱 검색
- 프롬프트 튜닝
Early Stop
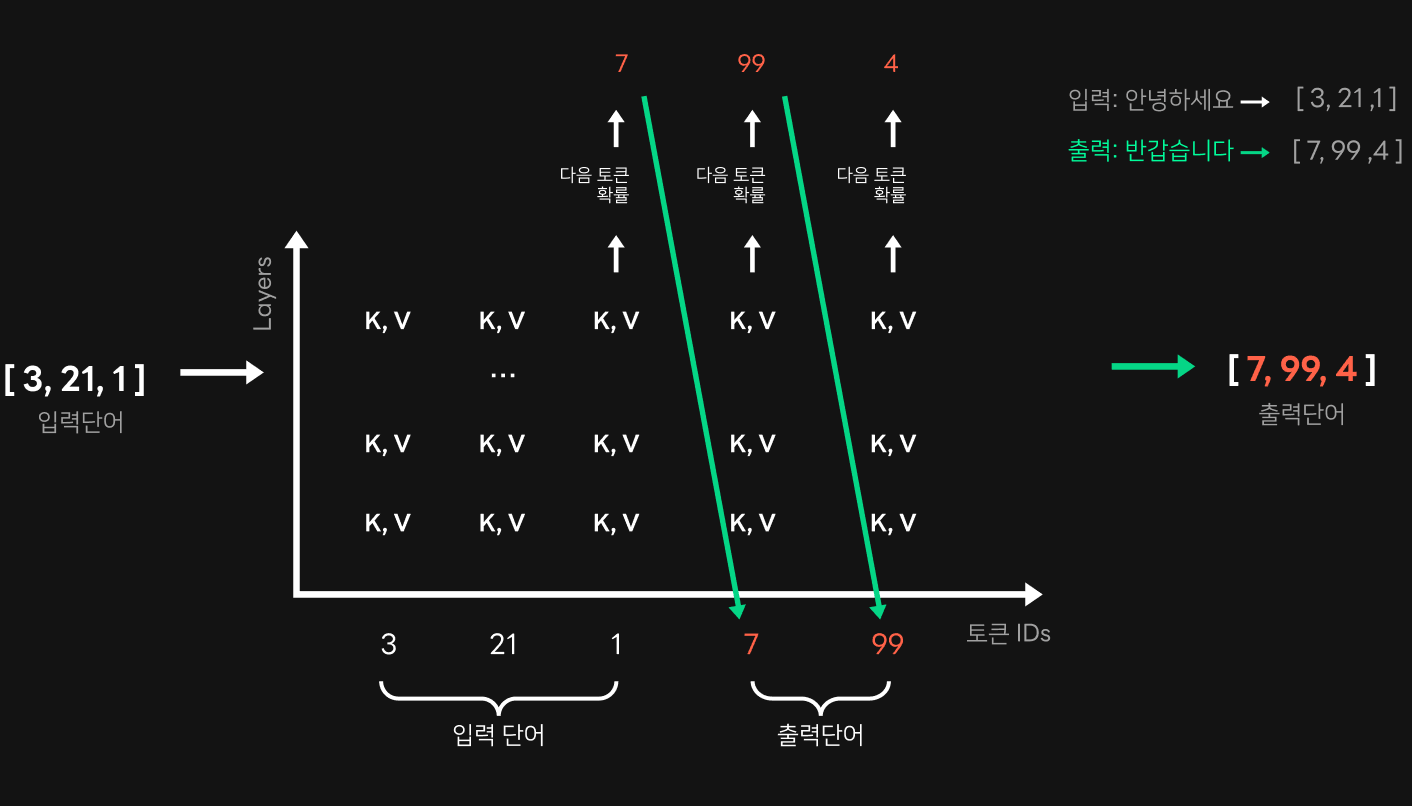
HyperCLOVA와 같은 GPT-3 모델에서 가장 많은 시간을 소비하는 단계는 문장을 생성하는 단계입니다. 트랜스포머 구조의 특성상 연산할 때는 입력 문장을 처리하는 summarization 단계와 문장을 생성하는 generation 단계로 나뉘게 됩니다. summarization 단계에서는 입력 문장에 해당하는 토큰 ID들이 배치 형태로 한꺼번에 처리되는 반면, generation 단계에서는 한 토큰씩 생성하는 순차 처리 형태로 진행됩니다. 때문에 문장 생성 단계인 generation 단계가 전체 시간 중 가장 큰 비중을 차지하게 됩니다. 따라서 문장 생성 길이를 줄이는 것은 응답 시간 단축과 직결되는데요. 그렇다면 어떻게 문장 생성 길이를 줄일 수 있을까요?
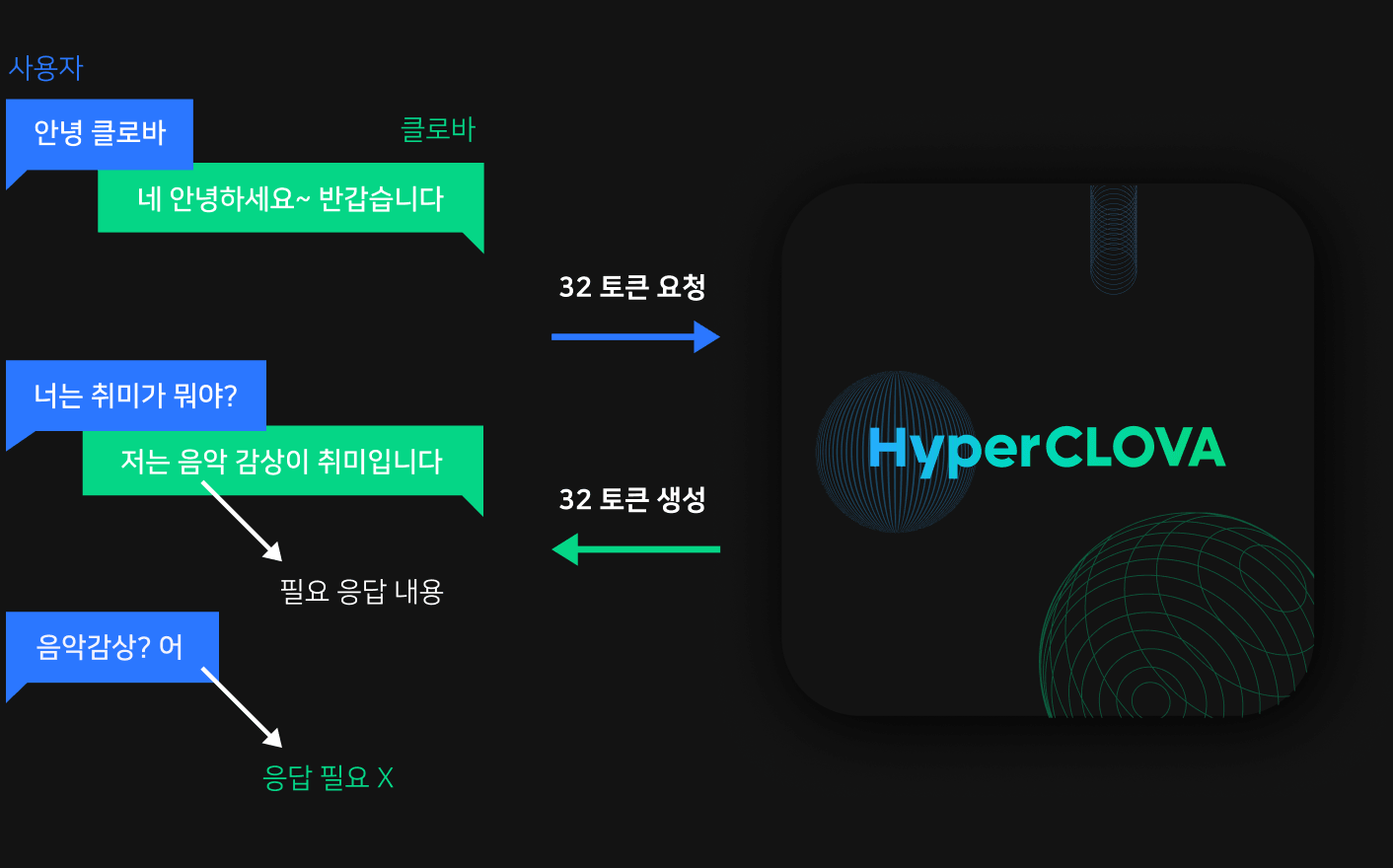
위 그림은 클로바 AI 스피커가 HyperCLOVA로 문자열 생성을 요청한 예시입니다. 클로바 AI 스피커는 클로바와 사용자가 주고받은 왼쪽 상단 대화의 마지막 사용자 질문으로 HyperCLOVA에 문장 생성을 요청하는데요. 이때 생성할 문장의 길이를 토큰 개수로 적어서 함께 전달합니다. HyperCLOVA는 요청받은 길이만큼 토큰을 생성한 뒤 이를 문장으로 바꿔서 클로바 AI 스피커 서비스로 응답합니다.
이때 문자열 생성을 요청하는 입장에서는 답변을 받아보기 전까지는 HyperCLOVA가 문장을 얼마나 생성할지 알 방법이 없습니다. 그렇기 때문에 요청할 때는 충분한 문장이 생성될 수 있는 길이로 토큰 생성을 요청하고, 사용자에게 응답할 때는 필요한 부분만 잘라서 응답합니다. 예시에서는 클로바:로 시작하는 문장만 필요하고 사용자:로 시작하는 문장은 필요 없기 때문에 첫 번째 문장만 잘라서 사용자에게 답변합니다.
이런 상황에서 만약 아래 그림과 같이 HyperCLOVA가 문장을 생성할 때 필요한 문장만 생성해 반환한다면, 전체 지연 시간 중 가장 큰 비중을 차지하는 문장 생성 시간을 줄이면서 응답 시간 또한 많이 줄일 수 있습니다. 이와 같은 기능을 Early Stop이라고 합니다.

하지만 트랜스포머 프레임워크로 FasterTransformer를 이용하는 HyperCLOVA의 경우 Early Stop 기능을 바로 구현할 수 없었습니다. Early Stop 기능을 구현하기 위해서는 생성되는 토큰 ID를 매번 문자열로 변환해서 종료하고자 하는 문자열과 일치하는지 검사하는 과정이 필요했는데요. 컴파일 이후 공유 라이브러리(shared library) 형태로 제공되는 FasterTransformer는 정해진 인터페이스대로만 사용할 수 있어서 요청한 길이만큼 토큰 ID가 생성된 이후의 결과만 받아올 수 있었기 때문입니다.
이 문제를 해결하기 위해 우리는 생성된 토큰 ID를 매번 문자열로 변경할 수 있도록 FasterTransformer 내부에 Early Stop 기능 구현에 필요한 토크나이저(tokenizer)와 이를 처리할 수 있는 인터페이스를 추가했습니다.
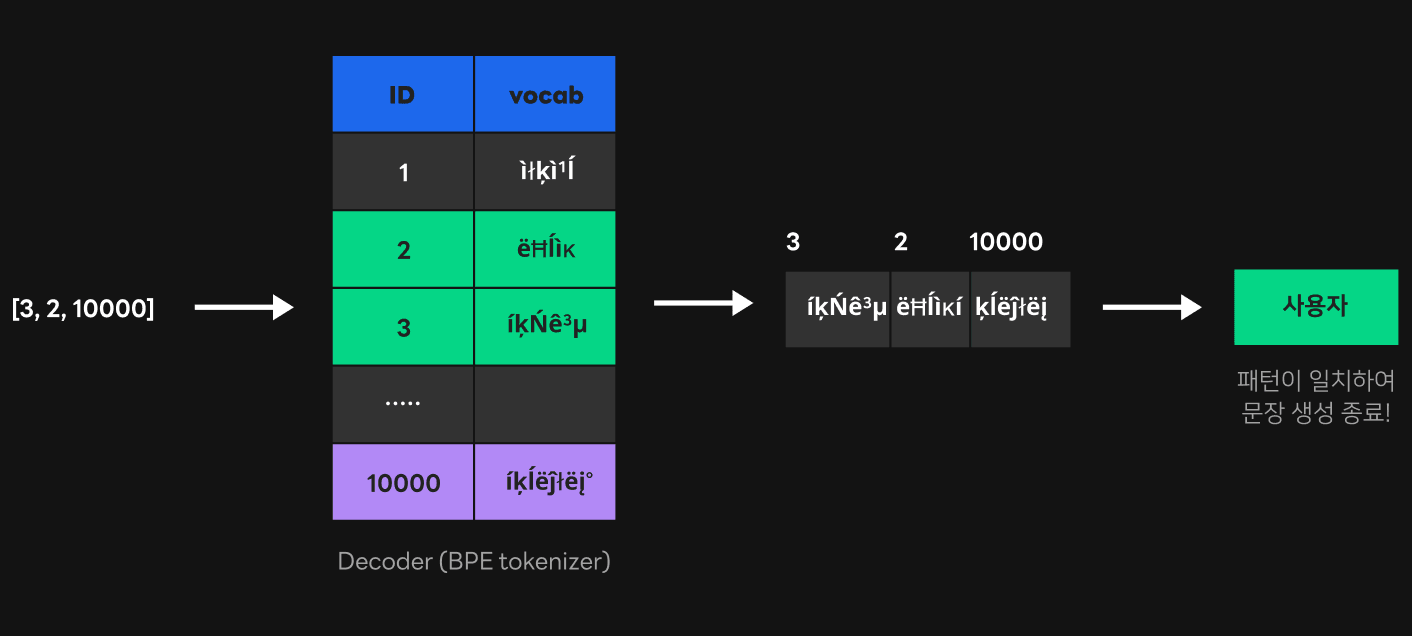
우리가 필요했던 부분은 토큰 ID를 문자열로 변환하는 기능이었기 때문에 토크나이저의 디코더 부분만 구현했습니다. 이때 디코더 부분은 단순하게 해시 맵 형태로 구현할 수 있는데요. 각 토큰 ID에 해당하는 유니코드가 매핑된 정보를 그대로 해시 맵으로 옮겨서 사용할 수 있기 때문입니다. 위 그림은 토크나이저의 디코더를 이용해 토큰 ID [3, 2, 10000]을 문자열 '사용자'로 바꾸는 과정을 보여줍니다. 토큰 ID로 각각에 매핑되어 있는 vocab을 색인하고, 이를 이용해 찾은 유니코드를 이어 붙여서 문자열로 변경하는 방식으로 토큰 ID를 문자열로 변경했습니다.
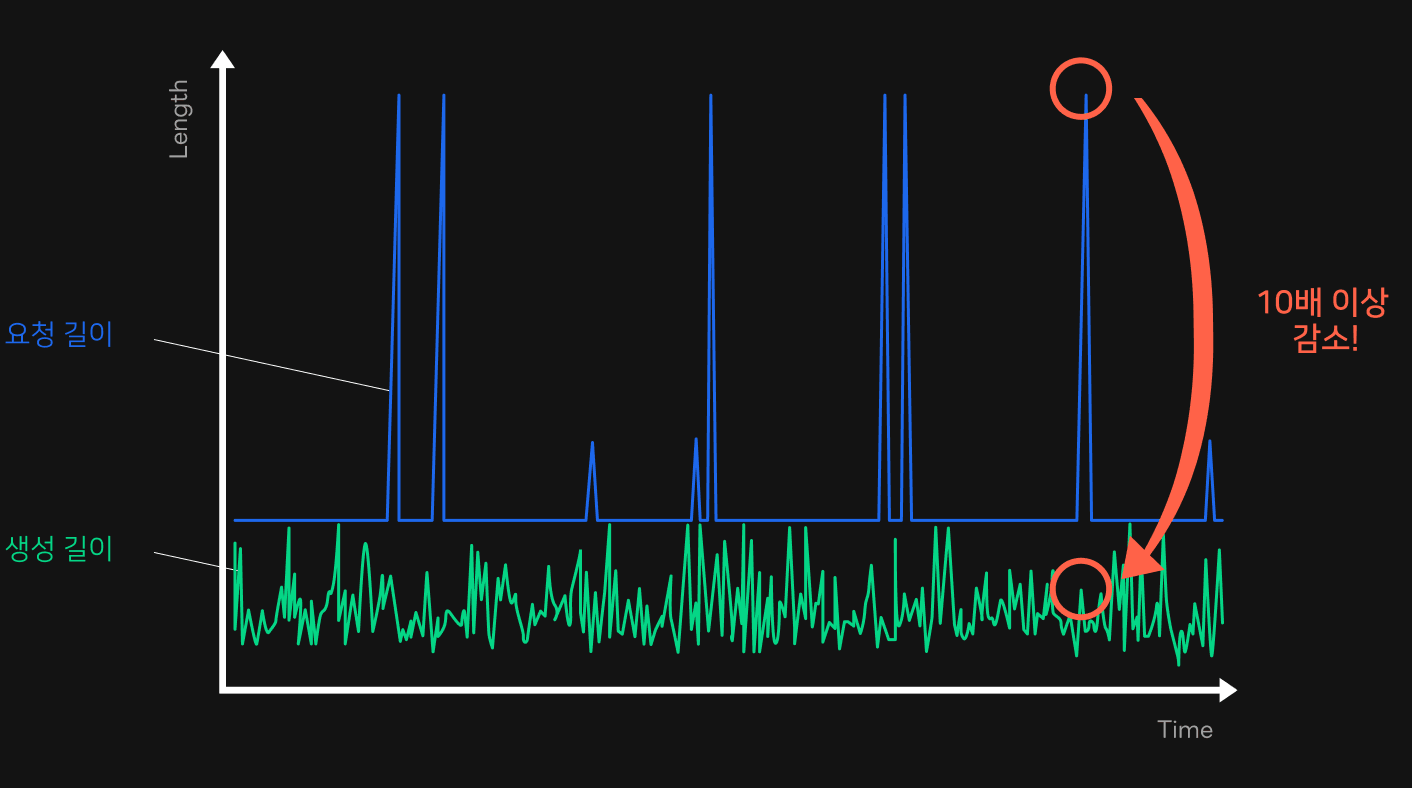
위 그림은 Early Stop 기능을 구현한 후의 문장 생성 요청 길이와 실제로 생성된 길이를 로그로 남겨 분석한 그래프입니다. 파란색 선은 요청 길이를, 초록색 선은 생성된 길이를 나타냅니다. 그래프를 보면 서비스에서 실제 생성된 길이보다 훨씬 긴 길이로 요청하고 있는 것을 확인할 수 있습니다. 극단적인 경우에는 요청 길이보다 생성 길이가 10배 이상 짧은 경우도 있는데요. 이런 경우에는 실제 응답 시간도 10배 가까이 줄어드는 것을 확인할 수 있었습니다.
시맨틱 검색
HyperCLOVA와 같은 GPT-3 모델은 기본적으로 문장 생성 작업을 처리하는 데 매우 적합합니다. 하지만 문장 생성 원리를 잘 살펴보면 다른 용도로도 사용할 수 있다는 것을 알 수 있습니다. 이번 섹션에서는 그중에서 대표적으로 시맨틱 검색(semantic search)이라는 작업을 HyperCLOVA가 어떻게 처리할 수 있는지, 또한 어떤 식으로 연산 과정을 구성할 수 있는지 정리해 보겠습니다.
시맨틱 검색이란 무엇일까요? 시맨틱 검색은 입력 문장들 혹은 단어들의 문맥 및 관련도를 추론해 점수화하는 작업입니다. 시맨틱 검색을 응용하면 문장 및 단어 사이의 연관도를 이용한 추천 시스템을 만들 수 있고, 학습된 모델이 적합한 품질의 단어를 선택하는지 평가하는데 활용할 수도 있습니다.
아래 예시와 같이, 시맨틱 검색 기능은 기본 문장과 후보군 문장을 입력 문장으로 넣으면 기본 문장과 후보군 문장들 사이의 연관도를 점수로 계산해 줍니다. 기본 문장과 후보군 문장의 연관도가 높을수록 점수가 낮게 나오는데요. 아래 예시에서는 후보군 문장들 중 ‘된장찌개야’라는 문장이 기본 문장과 가장 높은 연관도를 지니고 있다고 추론되었습니다.

HyperCLOVA에서 문장을 생성하는 과정과 시맨틱 검색 기능을 처리하는 과정을 비교해 보겠습니다.
먼저 두 과정 모두 동일하게 진행되는 과정을 살펴보겠습니다. HyperCLOVA와 같은 GPT 모델은 기본적으로 여러 트랜스포머 레이어를 통해 연산을 진행합니다. 트랜스포머 레이어 안에서는 query, key, value라는 개념을 사용하는데요. query는 현재 주어진 토큰과 관련있고, key와 value는 전체 문장 흐름과 관련있습니다. 각 트랜스포머 레이어 안에서는 이와 같은 query, key, value를 이용한 연산이 첫 번째 레이어부터 마지막 레이어까지 하나씩 순차적으로 진행됩니다. 마지막 레이어의 'Hidden state'라고 부르는 query, key, value 연산 결과로 산출되는 벡터를 이용하면, 다음 위치에 적합한 각 단어들이 지니는 확률값을 추출해 낼 수 있습니다. 추출 과정은 아래 그림과 같습니다. 마지막 레이어의 Hidden state에 LayerNorm(Layer Normalization) 연산을 실행하고, 임베딩(embedding) 테이블 값과 행렬 곱셈 연산을 진행한 뒤, softmax 연산을 진행합니다.
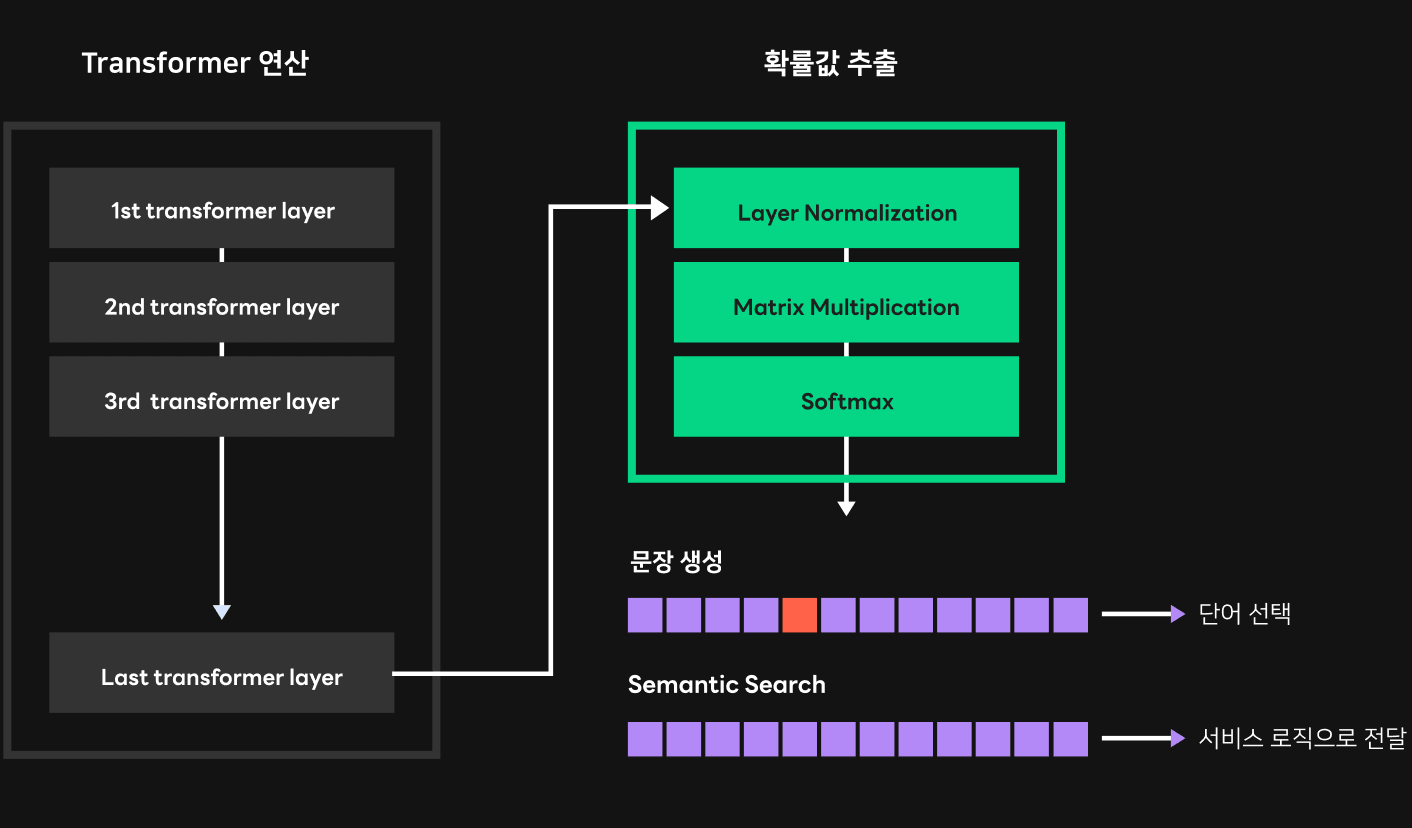
각 단어의 확률값을 추출한 뒤에는 문장 생성 과정과 시맨틱 검색 처리 과정이 조금 달라집니다. 문장 생성의 경우엔 이 확률값들을 이용해 샘플링이라는 과정을 거쳐 단어를 하나 선택하기만 하면 됩니다. 단순하게 여러 단어들 중 가장 확률값이 높은 단어를 선택할 수도 있고, 기존에 나온 단어들은 생성하지 않도록 페널티를 주거나 랜덤한 특성을 부여해 확률값이 높은 몇 개의 단어들 중에서 임의로 선택하는 방법을 선택할 수도 있습니다. 반면에 시맨틱 검색에서는 추출한 확률값들 중에서 각 위치에서의 후보군 단어들이 차지하는 확률값들을 모아야 합니다. 이 확률값들을 이용해 연산해서 어떤 후보군 단어 혹은 문장이 기본 문장과 가장 연관도가 높은지 추론합니다.
시맨틱 검색을 서비스하기 위해 꼭 필요했던 것은 FasterTransformer 프레임워크에서 이와 같은 확률값 추출 부분을 만드는 작업이었습니다. FasterTransformer에서 확률값 계산 결과를 서비스 로직에 전달할 수 있게 프레임워크를 수정했고, 서비스 로직에서는 이 확률값들을 이용해 실질적으로 시맨틱 검색에서 요구하는 점수 계산을 진행할 수 있도록 구현했습니다.
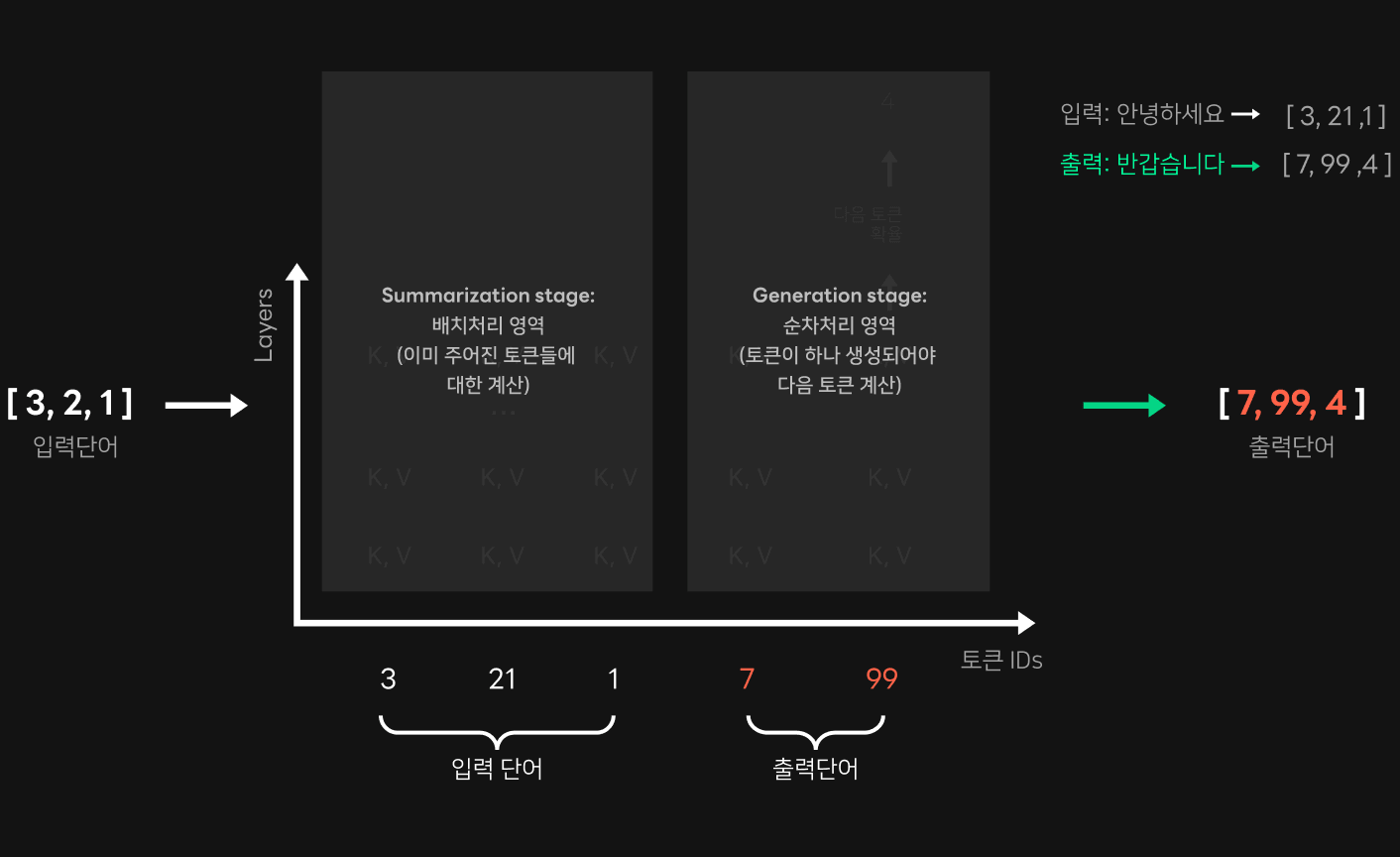
Early Stop 관련 설명에서 다룬 것과 같이, 확률값을 계산할 때 GPT 연산은 크게 입력 문장 및 단어에 대해 배치 형태로 한꺼번에 처리하는 summarization 단계와 한 단어씩 다음 단어를 생성하는 generation 단계로 나뉩니다. Generation 단계는 이전 단어 위치에서의 key와 value 값을 이용해 확률값을 추출하고 단어들을 하나하나 생성해 나가는 과정입니다.
처음에는 generation 단계에서의 연산으로 확률값을 추출한 뒤 이 값을 서비스 로직에서 전달받아 시맨틱 검색 점수를 계산하도록 코드를 작성했는데요. 이런 방식에는 문제가 있었습니다. Generation 단계는 단어 하나하나의 확률값을 추출하기 위해 직렬화(serialize)한 연산을 진행해야 하는데 이렇게 하면 지연 시간 또한 길어질 수밖에 없다는 것이었습니다.
우리는 GPT의 특성을 활용해 확률값 추출을 좀 더 빠르게 진행할 수 없을지 고민했습니다. 앞서 GPT 연산의 summarization 단계에서 입력 단어들의 확률값을 한 번에 계산할 수 있다는 점을 설명했는데요. 기본 문장과 후보군 문장 사이의 시맨틱 검색 연산을 실행할 때, 사실 기본 문장과 후보군 문장 모두 입력 문장이고, summarization 단계에서 후보군 문장 위치의 확률값은 아래 그림처럼 한 번에 계산할 수 있다는 점에 착안했습니다.
Summarization 단계에서 필요한 확률값들을 한 번에 추출함으로써 특정 입력 문장과 후보군 문장을 입력해 시맨틱 검색 연산을 진행할 때 지연 시간이 10배 이상 단축되기도 했습니다. 만약 처음부터 GPT의 연산 과정을 잘 이해했다면 애초에 이와 같이 설계하는 것이 맞는 방법이었을 것입니다. 하지만 처음에는 이런 방법을 생각하지 못했고, 이후 GPT의 구조를 좀 더 이해한 뒤에서야 비로소 이와 같은 최적화 방법을 고안해 낼 수 있었습니다.
프롬프트 튜닝
앞서 1편에서 언급한 것과 같이 HyperCLOVA와 같은 GPT-3 모델은 크기가 크고 연산량이 많아 다른 AI 모델에 비해서 추론(inference)의 지연 시간(latency)이 깁니다. 쾌적한 서비스를 위해서는 지연 시간을 단축하는 게 중요하기 때문에 클로바에서는 지연 시간을 단축시키기 위해 다양한 시도를 하고 있습니다. 지연 시간을 단축하기 위해서는 연산을 최적화해 인퍼런스 시간을 단축하는 방법이 있고, 모델의 성능을 높여서 더 작은 모델을 사용해 시간을 단축하는 방법도 있습니다. 우리가 지원하게 된 기능은 후자에 속하는 프롬프트 튜닝(P-Tuning)입니다. 프롬프트 튜닝은 간략히 말해 사전 학습된(pre-trained) 모델을 바탕으로 특정 작업에 맞춤화된 프롬프트를 학습하는 것이라고 할 수 있습니다. 여기서 프롬프트는 입력 예제에 삽입시킨 특별한 텍스트의 일종으로, 특정 작업에 좀 더 적합한 문장 생성을 유도해 냅니다.
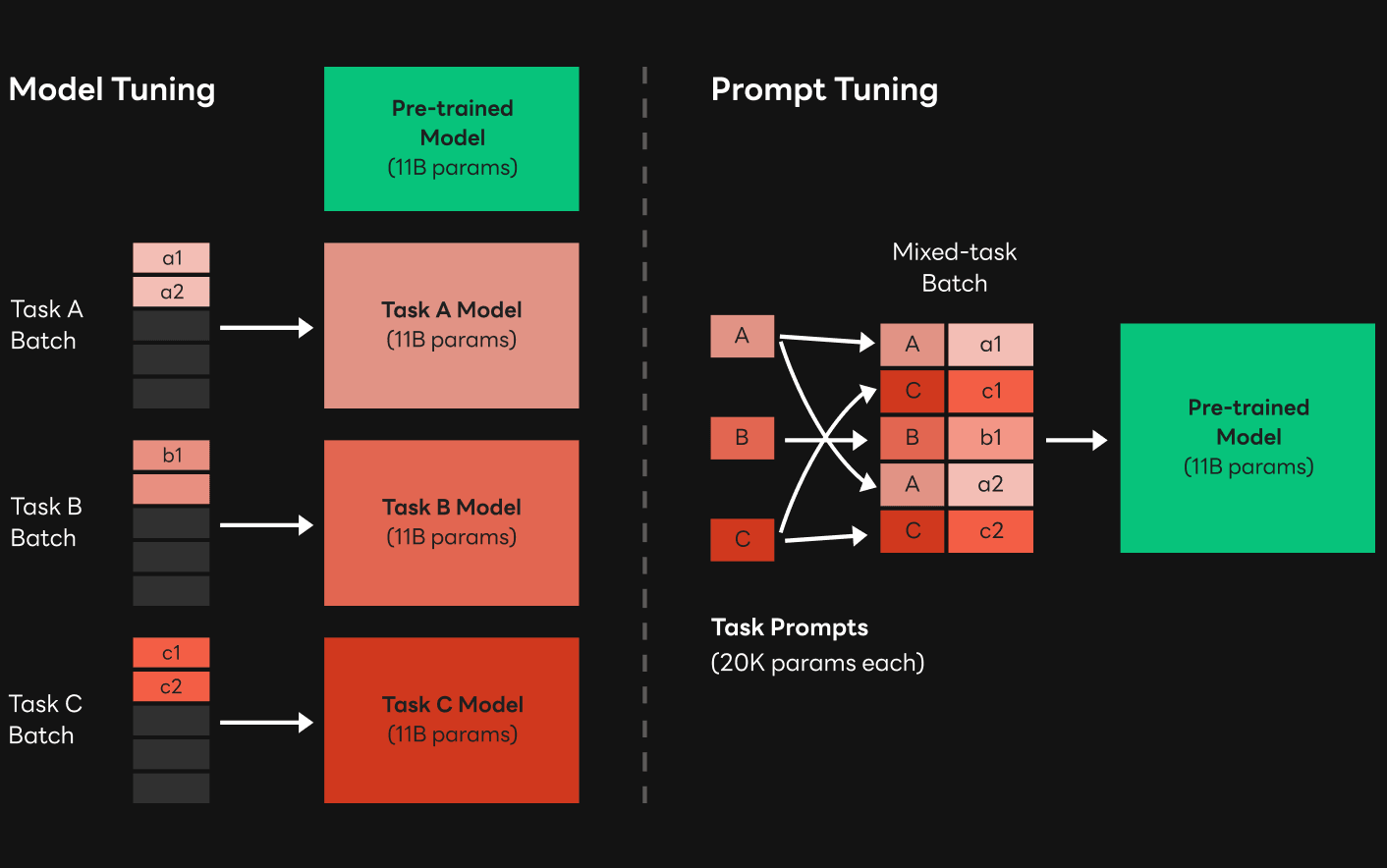
우리가 잘 알고 있는 파인 튜닝과 비교하면 프롬프트 튜닝을 좀 더 쉽게 파악할 수 있습니다. 서로 다른 작업의 여러 AI 서비스를 기획하고 있다고 가정해 보겠습니다. 이런 경우에는 일반적으로 각 작업에 맞는 모델을 밑바닥부터 학습하기보다는 사전 학습된 모델을 상황에 맞게 튜닝해서 사용합니다. 이때 파인 튜닝은 사전 학습된 모델을 각 작업에 맞는 데이터 셋을 이용해 상대적으로 짧은 시간 동안 학습하는 것으로 모델의 weight가 변경되기 때문에 모델 튜닝이라고 합니다. 반면 프롬프트 튜닝의 경우에는 사전 학습된 모델의 weight는 변경하지 않고 모델에 입력될 프롬프트에 해당하는 weight만 학습합니다. 일반적으로 모델의 weight보다는 프롬프트의 weight가 훨씬 작기 때문에 프롬프트 튜닝 방식은 파인 튜닝에 비해 학습 부담은 낮으면서 확장성은 높습니다. 이런 프롬프트 튜닝의 특징은 GPT-3와 같은 거대한 모델에서 더욱 두드러지게 나타납니다. 위 그림은 이와 같은 모델 튜닝과 프롬프트 튜닝의 차이를 잘 보여주고 있습니다.
이런 장점을 활용하기 위해 클로바 모델 팀에서는 프롬프트 튜닝을 이용한 서비스를 계획했고, 서빙 환경에서 지원하기 위해 준비해야 했습니다. 모델 학습 환경이 아닌 서빙 환경에서 프롬프트 튜닝을 지원하기 위해서는 어떤 것들을 고려해야 했을까요? 학습된 프롬프트라는 새로운 입력이 생겼기 때문에 이를 모델이 처리할 수 있게 만드는 것이 필요했습니다. 모델이 새로운 입력을 처리하게 만들기 위해서는 먼저 모델이 프롬프트의 존재를 인식하게 만들어야 하고, 다음으로 인식된 프롬프트에 해당하는 weight를 모델까지 잘 전달할 수 있어야 합니다. 먼저 입력 문장이 트랜스포머로 전달되는 과정을 상세하게 살펴보겠습니다.
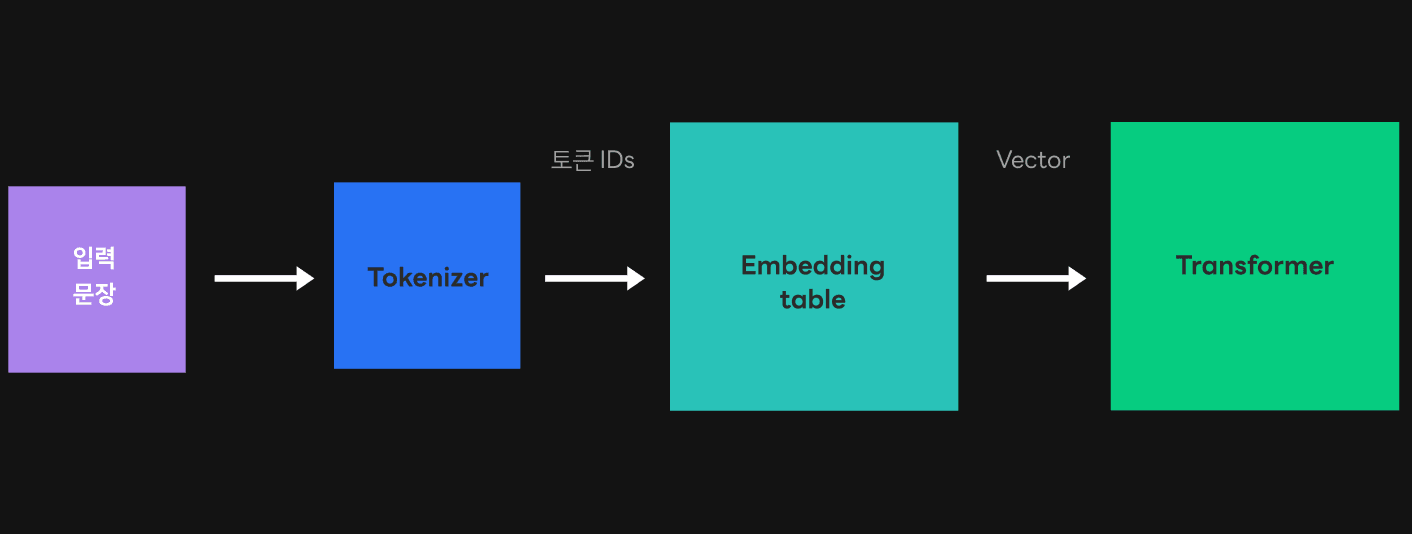
위 그림과 같이 사용자는 HyperCLOVA로 요청을 전송할 때 문자열을 보내지만, 트랜스포머가 처리할 수 있는 입력은 벡터이기 때문에 해당 문자열을 벡터로 변경하는 과정이 필요합니다. 이에 따라 입력 문장은 먼저 토크나이저를 통해서 토큰 ID로 변경되고, 토큰 ID는 다시 임베딩 테이블을 거쳐 벡터로 변경되는데요. 이때 토큰 ID가 일종의 테이블 오프셋(offset) 역할을 합니다. 이렇게 토크나이저와 임베딩 테이블을 거치고 나면 비로소 트랜스포머가 인식할 수 있는 벡터로 변환됩니다.
그렇다면 프롬프트 튜닝을 위한 프롬프트의 weight는 어떻게 트랜스포머로 전달할 수 있을까요? 우선 다른 문자열 입력과 마찬가지로 프롬프트에 해당하는 문자열을 지정하고, 이를 토크나이저에 등록해 토큰 ID로 변경할 수 있게 해야 합니다. 토크나이저의 특별 토큰(special token) 기능을 이용하면 프롬프트에 해당하는 문자열을 토크나이저 끝에 등록할 수 있습니다. 이때 한 가지 주의할 점은 새로 등록한 특별 토큰은 기존 토큰에 영향을 주지 않도록 조심히 선택해야 한다는 것입니다.
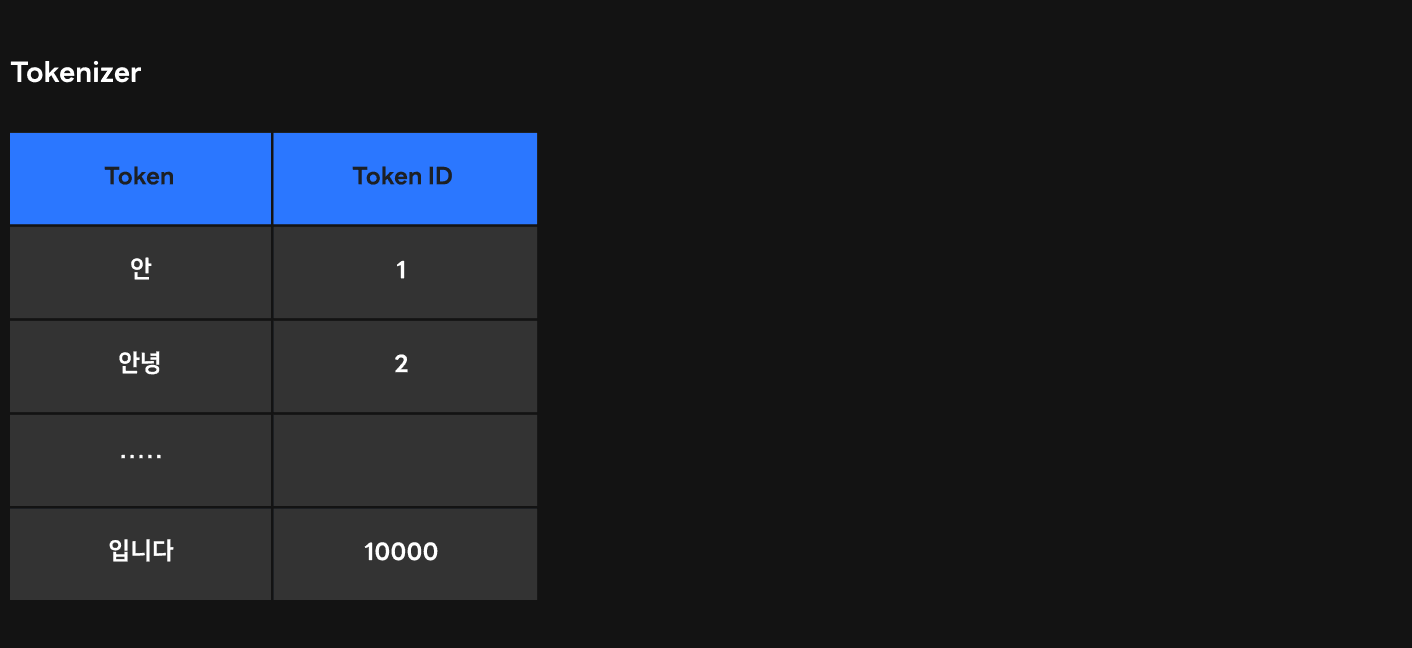
위 그림은 토크나이저의 토큰과 그에 해당하는 토큰 ID를 보여줍니다. 우리가 프롬프트를 토크나이저에 등록한다고 가정하겠습니다. 만약 이 프롬프트의 토큰을 '안녕'이라고 정하면 어떻게 될까요?

그림에서 볼 수 있듯이 '안녕'에 해당하는 토큰은 이미 토크나이저에 ID 2로 등록되어 있습니다. 하지만 우리가 프롬프트를 안녕이라는 토큰으로 두고 특별 토큰으로 등록시키면 '안녕'은 토크나이저의 마지막 ID인 10001번을 부여 받습니다. 그리하여 기존의 '안녕' 토큰과 프롬프트 '안녕' 토큰을 구분할 수 없게 됩니다. 이를 방지하고자 우리는 아래와 같이 기존 토큰으로 나타나지 않을 특수한 토큰을(<|PROMPT|>) 특별 토큰으로 만들고 이를 프롬프트의 토큰으로 사용할 수 있게 했습니다.
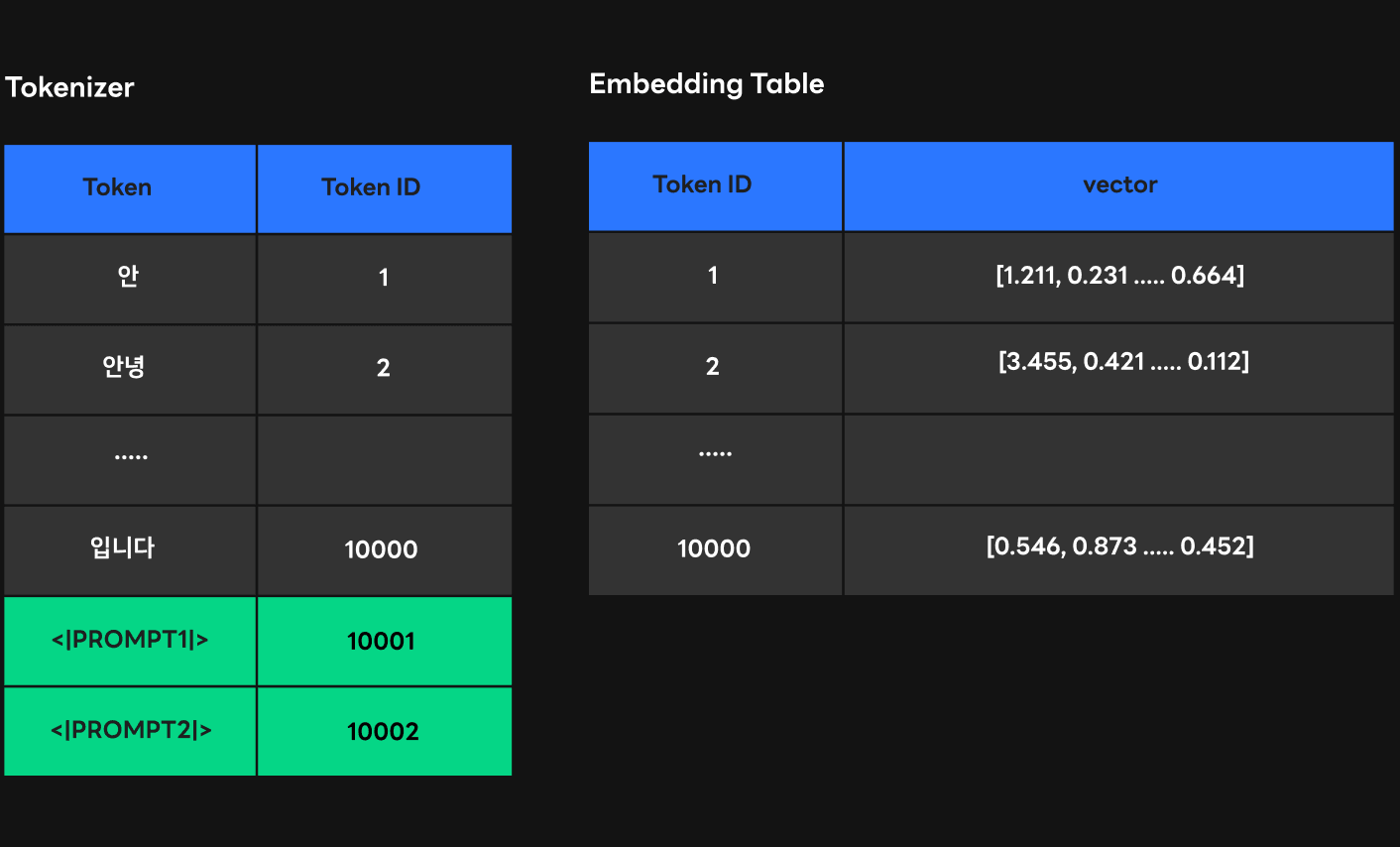
그럼 프롬프트에 해당하는 weight는 어떻게 트랜스포머로 전달할 수 있을까요? 우리는 이를 위해 두 가지 방법을 시도했습니다. 첫 번째는 임베딩 테이블에 토큰 ID에 해당하는 벡터를 등록하는 것이고, 두 번째는 인퍼런스 타임에 트랜스포머로 벡터를 직접 전달하는 것입니다.
1) 첫 번째 접근 방법: 임베딩 테이블 수정
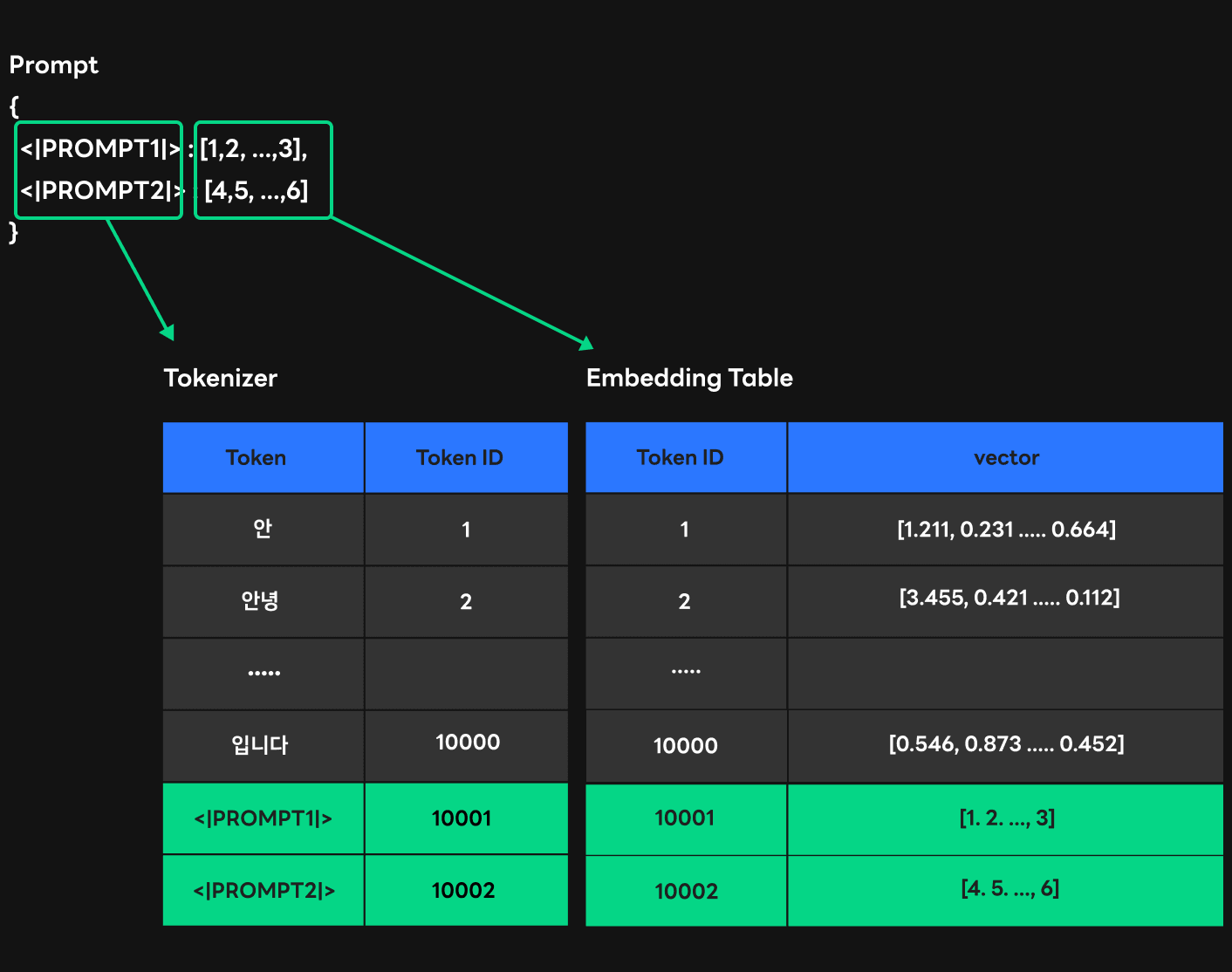
위 그림은 임베딩 테이블을 수정해 프롬프트 weight를 트랜스포머로 전달하는 방법을 보여줍니다. 앞서 토크나이저의 결과로 나오는 토큰 ID는 임베딩 테이블의 오프셋처럼 사용된다고 말씀드렸는데요. 이는 바꿔 말하면 우리가 토큰 ID를 가지고 있을 때 이 위치의 임베딩 테이블에 weight를 추가한다면 일반적인 형태와 동일하게 동작할 수 있다는 것을 의미합니다. 여기서 한 가지 주의할 점은 이렇게 추가한 프롬프트 토큰 ID가 트랜스포머의 결과로 출력되면 안 된다는 것입니다. 하지만 트랜스포머의 연산 구조상 다음 토큰 ID를 선택할 때 임베딩 테이블과의 연산을 진행하기 때문에 프롬프트에 해당하는 토큰 ID가 출력될 가능성이 있습니다. 이를 예방하고자 sampling size라는 변수를 두어서 그 범위 안에서만 토큰이 선택될 수 있게 했습니다.
위와 같은 방법에는 두 가지 이점이 있었습니다. 첫 번째는 구현의 편의입니다. FasterTransformer의 내부는 CUDA로 구현되어 있어 수정하고 확인하는 과정이 오래 걸리지만 임베딩 테이블은 파일로 존재하는 weight만 수정하면 되기 때문에 Python에서 빠르게 구현해 볼 수 있었습니다. 두 번째는 캐싱 효과입니다. 임베딩 테이블에 속한 weight는 GPU 메모리에 상주하는 값으로 CUDA core가 가장 빠르게 접근할 수 있습니다. 우리는 임베딩 테이블 끝에 프롬프트에 해당하는 weight을 등록했기 때문에 같은 프롬프트 값이 왔을 때 따로 전달할 필요 없이 빠르게 색인할 수 있도록 했습니다.
하지만 위 방법에는 확장성이 제한된다는 치명적인 단점이 존재했습니다. 프롬프트 튜닝을 이용한 서비스가 몇 개 없을 때는 위와 같은 방법이 효과적일 수 있지만, 서비스가 늘어나고 등록해야 할 프롬프트가 많다면 어떻게 될까요? 토크나이저와 임베딩 테이블에 계속해서 프롬프트에 해당하는 토큰과 weight를 등록해야 할 것입니다. 일반적인 경우에는 토크나이저에서 소요되는 시간이 얼마 안되지만, 특별 토큰이 많아지면 많아질수록 성능이 급격하게 떨어집니다. 또한 임베딩 테이블은 상대적으로 크기가 작은 GPU 메모리 내부에 있기 때문에 무한정 늘릴 수가 없습니다. 이런 이유로 우리는 프롬프트 weight를 임베딩 테이블을 거치지 않고 직접 트랜스포머로 전달하는 방법을 선택했습니다.
2) 두 번째 접근 방법: 인퍼런스 타임에 직접 전달
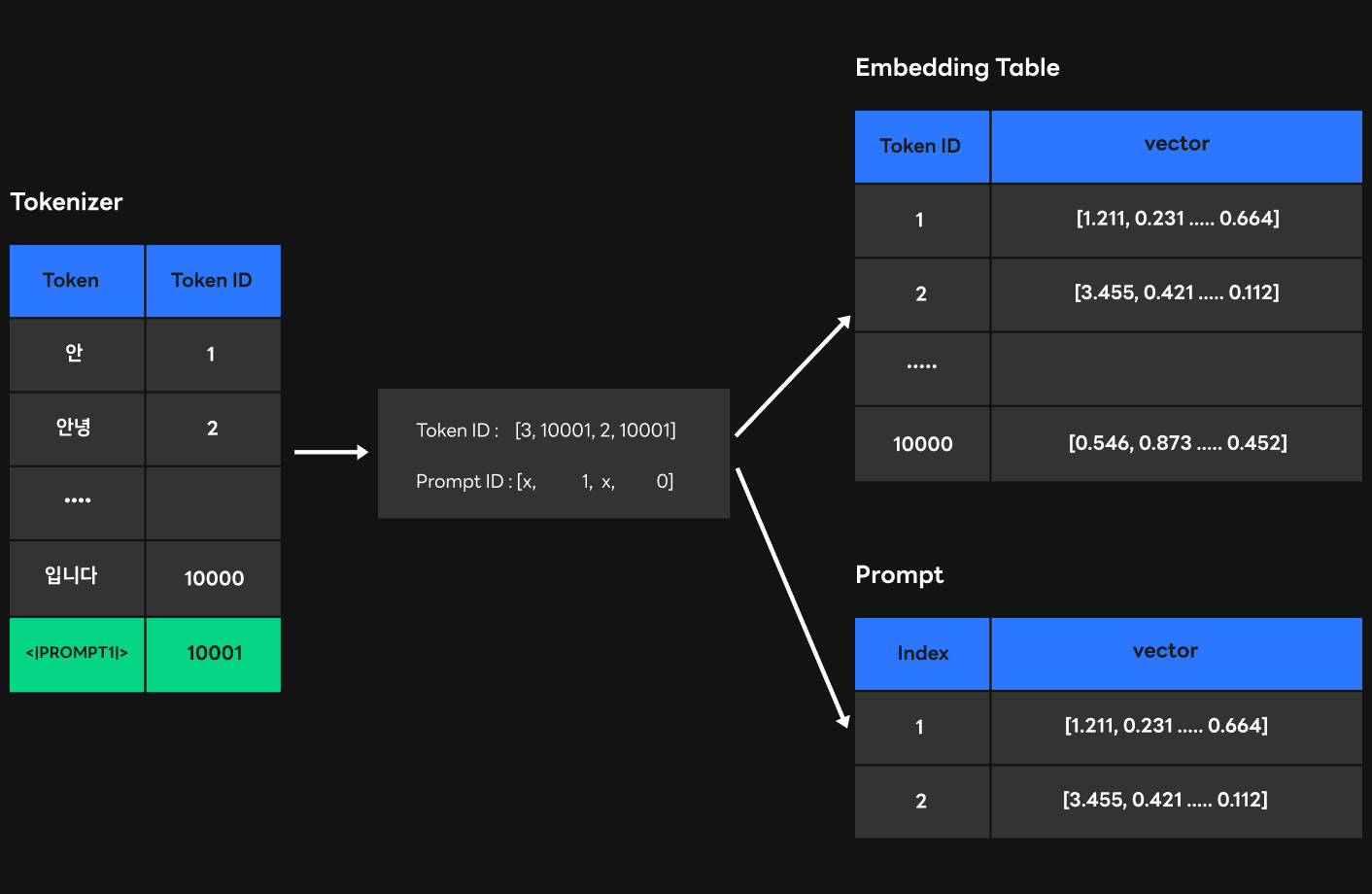
위 그림은 인퍼런스 타임에 프롬프트 정보를 직접 전달하는 방법을 보여줍니다. 앞서 설명드린 방법과는 다르게 토크나이저에서 여러 가지 프롬프트를 모두 하나의 토큰 ID로 인식하도록 했습니다. 이를 통해 토크나이저의 성능 하락은 예방할 수 있었지만, 서로 다른 프롬프트를 구분할 수 있는 다른 방법이 추가로 필요했습니다. 이에 기존의 토큰 ID 정보와 함께 프롬프트 ID를 FasterTransformer로 전달하는 방법을 선택했고, 프롬프트 ID로 색인할 수 있는 프롬프트의 weight를 FasterTransformer로 함께 전달했습니다. 이와 같은 방법으로 FasterTransformer는 토큰 ID 정보에서 학습한 토큰 범위 내의 ID(1 ~ 10000)를 확인하면 임베딩 테이블에서 색인하고, 범위를 벗어난 토큰 ID(10001)를 만나면 같은 위상에 있는 프롬프트 ID를 이용해 프롬프트 weight에서 색인할 수 있게 되었습니다.
결과적으로 두 번째 방법을 이용해 프롬프트 튜닝 요청을 일반 요청과 유사한 응답 시간 안에 서비스할 수 있었습니다.


