





이번 글에서는 모델 관리와 운영에 필요한 여러 가지 컴포넌트에 대해 이야기하겠습니다. 먼저 CLOps에서 모델을 관리하고 사용하는 방법과 비동기 방식 모델 서빙을 구현한 방법 등 모델 배포와 관리 방법을 살펴보고, 이어서 지표 수집과 모델 헬스 체크, 파이프라인과 같이 모델을 운영할 때 필요한 컴포넌트를 알아보겠습니다.
모델 배포 관리
모델 관리
CLOps에서는 안정적으로 모델을 배포하기 위해 모델 레지스트리를 자체 제공하고 있으며, 좀 더 빠르고 효율적으로 모델을 전달하기 위해 배포 캐시를 도입했습니다.
모델 레지스트리
프로덕션 환경에서 모델 레지스트리는 머신 러닝 작업을 지원하기 위한 필수 구성 요소입니다. 모델 레지스트리는 학습된 모델과 모델 버전 및 학습 중 사용한 유용한 메타 데이터를 중앙 저장소에 저장하고 추적할 수 있는 컴포넌트입니다. 각 모델 버전의 메타데이터에는 학습 중에 사용한 하이퍼 매개변수와 환경 정보가 포함되어 있으며, 이를 이용하면 모델을 재현할 수 있습니다. 따라서 모델 버전을 관리하면 모델의 각 버전별 성능을 비교할 수 있고 필요하면 이전 버전으로 롤백할 수도 있습니다. 또한 임의의 스토리지에 저장된 비즈니스 핵심 모델이 덮어쓰기 등으로 손실될 위험도 제거할 수 있습니다.
CLOps 모델 레지스트리는 플랫폼의 핵심 컴포넌트로 사용자와 CLOpsDeployment가 필요한 모델 파일을 다운로드할 수 있도록 지원하고, 모델 버전 간 A/B 테스트와 같은 기능도 지원합니다. API 서버로 구현했으며, 앞단에서는 모델 및 모델 버전에 대한 CRUD 작업을 수행하면서 파일 다운로드 및 업로드 기능을 제공하고, 뒤로는 데이터베이스 및 하나 이상의 오브젝트 스토리지 버킷(object storage bucket)과 연결돼 있습니다. 데이터베이스는 모델 및 버전 정보를 추적하는 데 사용하고 저장소는 모델 파일 자체를 저장하는 데 사용합니다. 모델마다 스토리지 요구 사항이 다를 수 있으므로 모델 레지스트리는 여러 가지 스토리지 백엔드로 구성합니다. 예를 들어 어떤 사용자는 업로드 및 다운로드 시간을 줄이기 위해 고성능 SSD 스토리지를 선호할 수 있고, 더 큰 모델을 사용하는 사용자는 느리지만 저렴한 HDD 같은 콜드 스토리지를 선호할 수도 있습니다.
모델 레지스트리는 REST API를 이용해 직접 사용할 수도 있고, CLOps Python SDK에 내장돼 있기 때문에 모델을 학습하고 설치된 SDK를 통해 모델 레지스트리에 업로드할 수도 있습니다.
배포 스토리지 캐시
이전 포스팅에서 CLOpsDeployment CRD(Custom Resource Definition)를 다뤘고, 초기화 컨테이너를 통해 모델 파일을 자동으로 다운로드한다고 간략하게 설명했습니다. 이 초기화 컨테이너를 storage-initializer라고 부릅니다. 단순히 배포하기 위한 모델 스토리지를 준비하는 것이 목적이기 때문입니다. CLOpsDeployment CRD에서 사용할 정확한 모델을 지정하는 것은 배포를 관리하는 사용자의 몫입니다. 사용자가 모델을 지정하면 CLOps 오퍼레이터가 reconciliation에서 그 정보를 storage-initializer 컨테이너로 전달합니다. 지정한 모델이 다운로드되면 storage-initializer는 종료되고 디플로이먼트 파드(Deployment Pod)가 실행됩니다.
기본적으로 디플로이먼트 파드가 생성될 때마다 모델이 다운로드돼 파드의 임시 스토리지(ephemeral storage)에 저장됩니다. 이는 각 디플로이먼트의 복제본(replica)이 모델 파일의 복사본을 각자 다운로드한다는 것을 의미하는데요. 작은 모델에서는 이런 방식이 괜찮을 수 있지만 수십에서 수백 GB에 이르는 거대한 모델에서는 문제가 발생합니다.
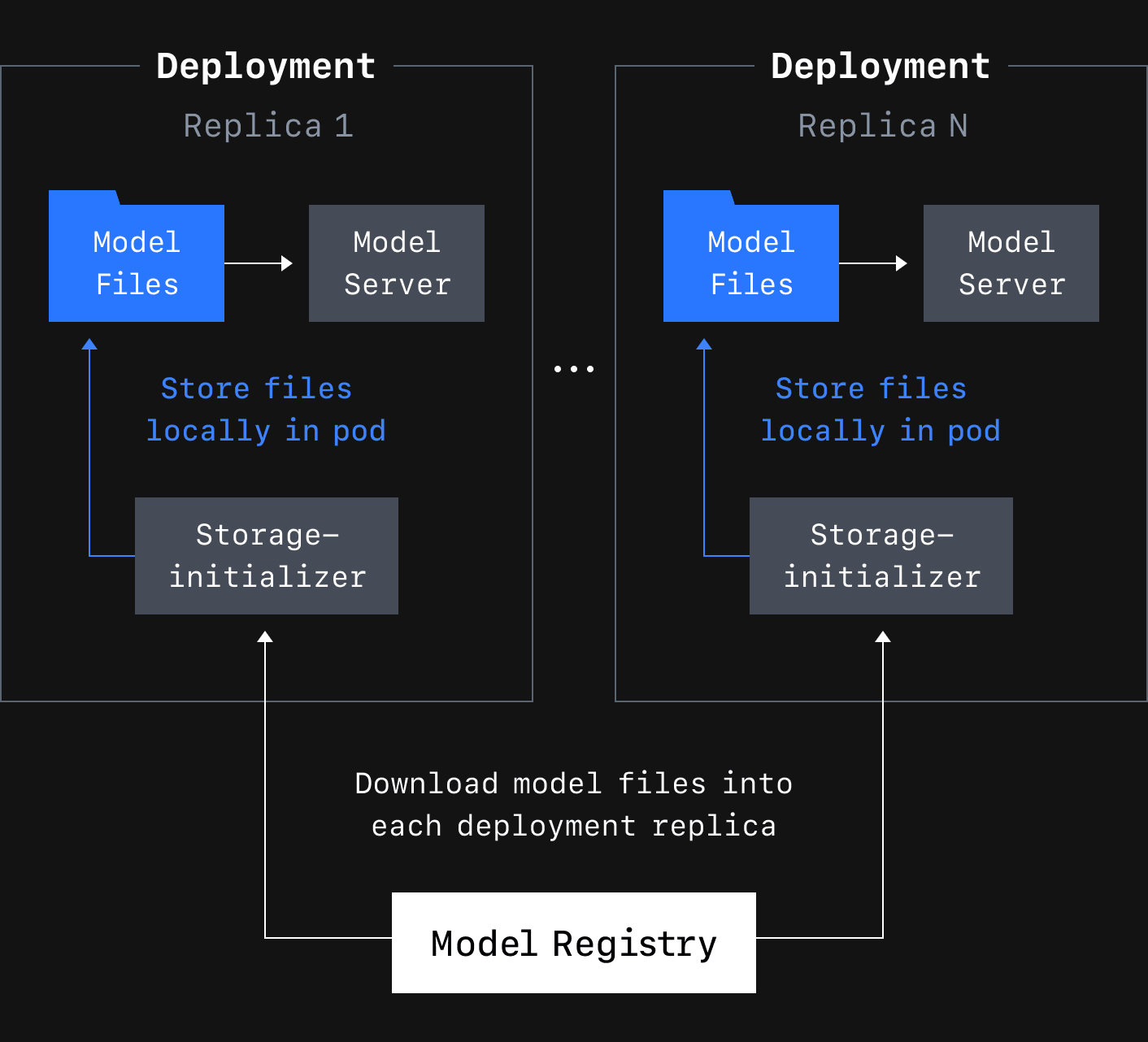
먼저 각 파드가 수백 GB에 이르는 동일한 모델 파일의 복사본을 보유하기 때문에 디스크 공간이 낭비됩니다. 그보다 더 큰 문제는 고성능 네트워크가 없으면 모델을 다운로드하는 데 몇 분 이상이 걸릴 수도 있다는 것입니다. 즉, 배포가 중단되고 다시 시작되면 한동안 트래픽을 처리할 수 없게 됩니다. 배포를 확장하는 것 역시 문제가 될 수 있습니다. 트래픽이 증가했을 때 모델 다운로드 때문에 새로운 복제본이 시작하는 데 오랜 시간이 소요되기 때문입니다. 따라서 더 큰 모델을 다루기 위해선 대체 스토리지 옵션이 필요합니다.
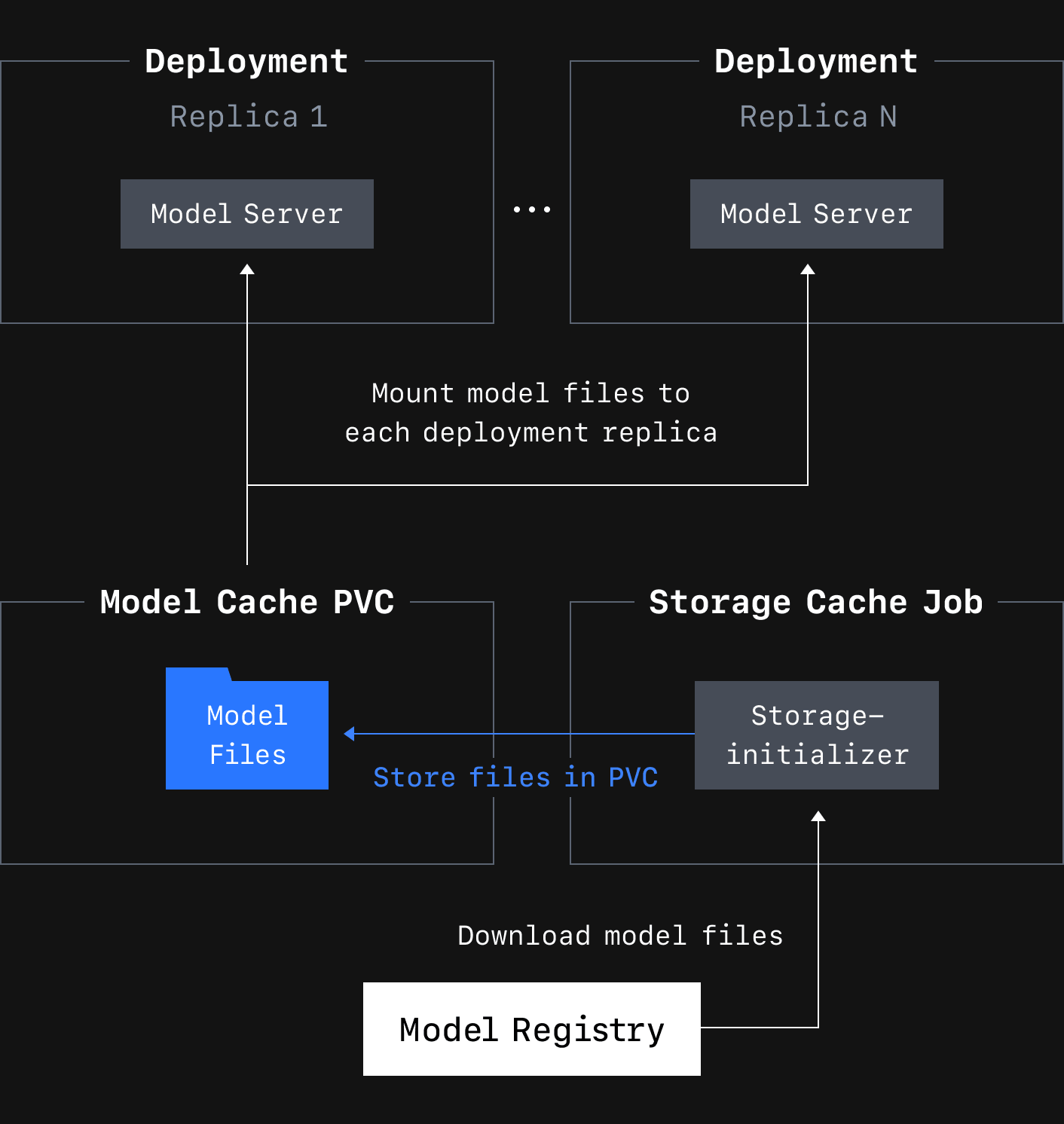
우리가 선택한 해결 방법은 쿠버네티스(Kubernetes)의 퍼시스턴트볼륨(PersistentVolume)을 이용해 모델 캐싱을 지원하는 것입니다. 이때 볼륨 드라이버는 네트워크에 연결돼 있어야 하며, 배포되는 파드의 모든 복제본 간에 공유될 수 있도록 동시 접근을 허용해야 합니다. 또한 CLOpsDeployment에서 사용할 모델을 지정할 때 cached로 구성하는 것도 가능합니다. cached로 구성하면 오퍼레이터가 배포를 시작하기 전에 모델 캐시를 준비합니다. 오퍼레이터는 원하는 캐시 모델당 하나의 PersistentVolumeClaim(이하 PVC)을 생성한 뒤, 앞서 언급한 storage-initializer을 실행하는 쿠버네티스 Job을 시작해서 생성된 모든 클레임을 탑재하고 각 대상 모델을 해당 볼륨에 다운로드합니다. 모든 다운로드가 완료되면 오퍼레이터는 작업 완료를 감지하고 모델 배포 조정을 진행합니다. 이때 오퍼레이터는 모델이 캐시에 있다는 것을 알고 있기 때문에 초기화 컨테이너(storage-initializer) 실행을 건너 뛰고, 대신 캐시 PVC를 배포에 읽기 전용 마운트로 추가합니다. 이제 디플로이먼트 파드가 시작되면 모델 파일을 다운로드하는 대신 캐시된 모델을 탑재하기만 하면 됩니다.
이런 방식으로 캐시된 모델을 사용하면 다음과 같은 이점을 얻을 수 있습니다.
- 여러 배포 복제본에서 공유할 수 있는 모델 파일의 단일 복사본을 이용해 수평 확장성 향상
- 로컬 모델 다운로드를 생략해 배포 시작 시간 단축
비동기 방식 모델 서빙 API
동기 방식(synchronous) API VS 비동기 방식(asynchronous) API
API는 요청에 대한 응답을 받는 방법에 따라 동기 방식과 비동기 방식으로 나눌 수 있습니다. 동기 방식은 서버에 요청한 뒤 응답이 올 때까지 기다린 후 다음 작업을 실행하는 방식입니다. 반면 비동기 방식에서는 서버에 요청한 뒤 응답과 상관없이 다음 작업을 실행하다가 콜백 함수나 폴링 형태로 응답을 별도로 확인합니다. 빠른 응답이 필요한 서비스에서는 주로 동기 방식 API를 이용해 사용자의 요청에 즉각 응답하고, 오랜 시간이 걸리는 작업에서는 비동기 방식 API를 이용해서 요청한 후 그 사이에 다른 작업을 진행하다가 처리가 완료되면 결과를 받아옵니다. CLOVA에는 두 가지 형태의 서비스가 모두 존재하는데 기존 CLOps에서는 동기 방식 API만 지원했기 때문에 비동기 방식 API를 지원할 수 있는 추론 시스템이 필요했습니다.
비동기 방식 추론 시스템
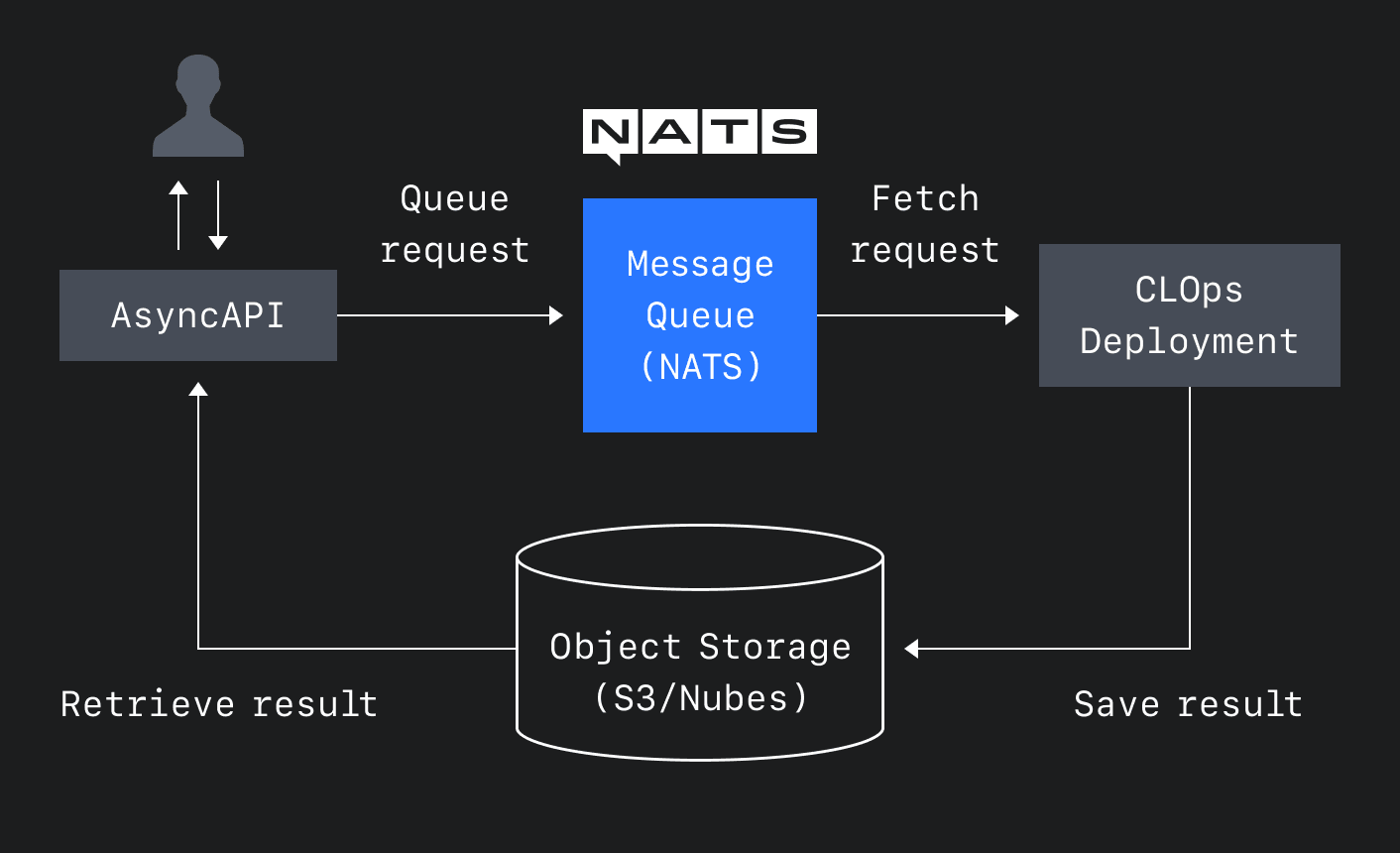
CLOps의 비동기 방식 추론 시스템은 아래와 같은 몇 가지 파트로 구성돼 있습니다.
- 큐에서 사용자의 요청을 가져오는 비동기 모델 디플로이먼트
- 메시지 큐 서버
- 결과를 저장할 수 있는 오브젝트 스토리지(object storage)
- 사용자의 요청을 큐에 넣고 그 결과를 스토리지에서 받아오는 API 서버
비동기 CLOpsDeployment
각 CLOpsDeployment 내부에는 항상 익스큐터라고 하는 사이드카 컨테이너가 배포됩니다. 일반적으로 이 컨테이너는 HTTP 요청에 대한 프록시 역할을 하지만, 비동기 모드에서는 메시지 대기열에서 요청을 가져오기도 합니다. 즉, 모델 컨테이너에서는 메시지 대기열 세부 정보를 신경 쓸 필요 없이 정상적으로 HTTP 요청을 처리할 수 있습니다.
비동기 CLOpsDeployment 배포는 일반 배포 방법과 매우 유사합니다. 유일한 차이점은 비동기 구성에 추가한다는 것이며, 비동기 구성에 추가하면 자동으로 비동기 모드에서 시작합니다. 비동기로 구성할 때 꼭 추가해야 할 두 가지는 입력 요청이 대기할 메시지 큐와 결과를 저장할 오브젝트 스토리지입니다.
메시지 큐
CLOps의 비동기 추론 시스템에서는 빠르고 안전하게 운영하기 위해 NATS 클러스터를 기본 메시지 큐로 사용합니다. 글로벌 NATS 클러스터는 여러 프로젝트와 팀에서 공유하기 때문에 각 프로젝트는 특정 주제 이름에만 접근할 수 있게 제어됩니다. 다른 프로젝트의 메시지에 접근할 수 없기 때문에 개인 정보 보호 및 안정성을 확보할 수 있습니다.
NATS는 인증할 때 계정을 사용하며, 비동기 추론을 사용하는 각 CLOps 프로젝트에는 전용 NATS 계정이 있습니다. 각 계정에는 리소스 할당량이 설정되는데 이는 과도하게 리소스를 사용해서 다른 프로젝트에 영향을 주거나 클러스터가 불안정해지는 것을 방지하기 위해서입니다. NATS에 대한 인증은 일반적으로 CLOpsDeployment에 자동으로 탑재되는 시크릿으로 수행합니다.
결과 스토리지
CLOpsDeployment가 비동기 추론을 완료하면 결과가 오브젝트 스토리지에 저장됩니다. 저장할 대상 스토리지는 배포 사양에서 구성하며, 기본적으로 사내 스토리지 플랫폼인 Nubes를 사용합니다. 이를 통해 스토리지 관리 부하를 줄이면서 스토리지를 안정적으로 제공할 수 있습니다.
비동기 API 서버
메시지를 대기열에 넣고 요청하는 클라이언트에서 직접 결과를 가져오는 것은 번거로울 수 있기 때문에 CLOps에서는 더 쉽게 요청할 수 있도록 비동기 API 서버 디플로이먼트를 지원합니다. 비동기 API 서버에는 새로운 추론 요청을 대기열에 넣거나, 추론 결과를 가져오거나, 배포 상태를 확인할 수 있는 HTTP 및 gRPC API가 마련돼 있습니다.
비동기 API 서버는 프로젝트 내에서 각 비동기 CLOpsDeployment를 자동으로 감지하고 서로 통신할 수 있게 해주기 때문에 하나의 프로젝트는 하나의 비동기 API 서버를 이용합니다. 이 서버에서 서로 다른 여러 CLOpsDeployment와 통신할 수 있습니다. 따라서 클라이언트는 추론 요청을 대기열에 넣을 때 비동기 API 서버에서 제공하는 엔드포인트를 통해 어떤 CLOpsDeployment를 사용할 것인지 지정해야 합니다.
비동기 API 서버를 통해서 클라이언트는 비동기 API를 사용해 추론 결과를 쉽게 찾아 디코딩하고 반환할 수 있으며, REST API를 이용해 요청 처리 전반을 제어할 수 있습니다.
적용 사례
CLOVA 노트 애플리케이션의 요약 기능은 CLOps의 비동기 방식 API를 이용해서 서비스하고 있는 가장 대표적인 사례입니다. CLOVA 노트에 기록된 텍스트는 초거대 AI인 HyperCLOVA를 이용해서 요약합니다. 노트에 기록된 텍스트가 HyperCLOVA의 입력이고, 요약된 문장이 출력입니다. 보통 30분에서 한 시간 정도 기록한 노트는 문자열 길이가 짧게는 수천에서 많게는 수만에 이르는데요. 이 문장들은 HyperCLOVA가 처리할 수 있는 일정한 길이로 묶여서 한꺼번에 배치(batch)로 처리합니다. 즉 HyperCLOVA가 노트 한 개를 요약할 때 실제로는 수십에서 수백 개의 요청을 처리해야 하는 셈인데요. 이는 수십 초 가까이 걸리는 작업이기 때문에 비동기 방식 API를 사용하기에 알맞은 케이스였습니다.
CLOps에서는 요약 요청이 비동기로 수행될 수 있도록 Asynchronous CLOpsDeployment 스펙을 지정한 뒤 CLOps에서 기본으로 제공하는 NATS 메시지 큐에 요청을 넣고, 추론 결과로 나온 응답은 설정 작업을 최소화하기 위해 사내 스토리지에 저장했습니다. 마지막으로 비동기 API 서버를 이용해 사용자에게 REST API를 제공해서 사용성을 높일 수 있었습니다.
모델 운영 관리
모니터링
이제 모니터링하기 위한 지표를 어떻게 수집해서 어떻게 사용자에게 제공하고 있는지 알아보겠습니다.
수집하는 지표 종류
CLOps는 여러 지표 정보를 하나의 저장소에 저장하고, 운영하면서 이를 모니터링 대시보드에서 활용합니다. 대시보드에서는 현재 운영하고 있는 프로젝트 개수, 서빙 중인 모델 개수, 정상 상태가 아닌 파드 등 여러 가지 정보를 확인할 수 있습니다. 모니터링하면서 수집하는 정보는 아래와 같습니다.
- 노드 단위 정보
- node-exporter: 클러스터 노드 정보
- dcgm-exporter: GPU 관련 정보
- 클러스터 단위 정보
- kube-state-metrics: 쿠버네티스 상태 정보
- CLOps-exporter: CLOps에서 리소스 상태를 확인하기 위해 정의한 익스포터
- 애플리케이션 단위 정보
- executor: 배포된 서빙 모델 정보(요청 개수 등)
Prometheus에서 VictoriaMetrics로 전환
초기에는 Prometheus로 운영하는 데 문제가 없었지만 클러스터 노드와 서빙하는 모델 수가 증가하면서 수집하는 지표의 종류와 양이 많아져 저장소 용량 부족과 SPOF, 특정 쿼리를 실행할 때 메모리가 부족해지는 등 여러 가지 문제가 발생했습니다. Prometheus 구조에서는 스케일 아웃/업과 고가용성(high availability) 확보, SPOF 같은 문제를 해결하는 게 쉽지 않았습니다.
이에 중앙 지표 저장소를 Prometheus에서 VictoriaMetrics로 변경했습니다. Prometheus와 VictoriaMetrics의 비교는 Deview 2021에서 발표됐던 앞으로 10년을 책임질, 네이버 검색 모니터링 시스템 구축기 발표 영상에서 확인하실 수 있으니 참고하시기 바랍니다.
사용자 지표 제공
사용자가 프로젝트에서 생성된 지표 정보를 확인할 수 있도록 프로젝트별로 Prometheus와 Grafana를 제공합니다. 이때 프로젝트별로 제공한 Prometheus에서 해당 프로젝트의 지표 정보만 수집하도록 Prometheus의 Federation 기능을 이용해 모든 정보가 수집된 저장소에서 필요한 지표만 수집하도록 구성했습니다.
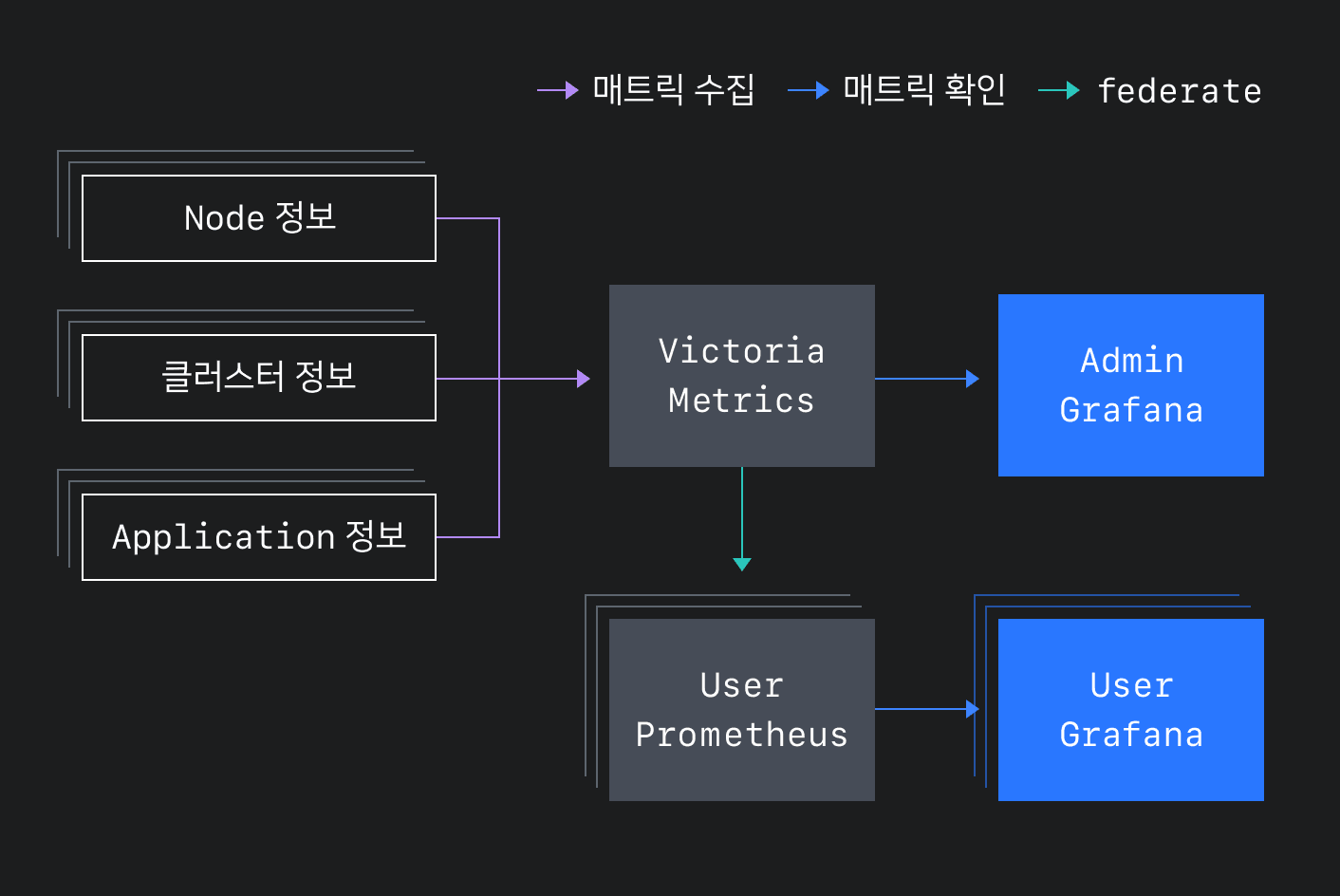
이와 같이 Prometheus와 Grafana를 프로젝트별로 제공하는 한편, Prometheus 지표 수집 과정에 필터링을 추가해서 사용자가 자신의 프로젝트에 해당하는 지표 정보만 볼 수 있도록 격리했습니다.
헬스 체크
모델을 성공적으로 배포했지만 의도치 않은 장애가 발생해서 서비스 도중 응답 장애가 발생할 수 있습니다. 따라서 모델을 배포한 후 모델의 엔드포인트가 안정적으로 서비스되고 있는지 확인할 필요가 있는데요. 이를 위해서는 주기적으로 서비스 중인 엔드포인트에 요청을 보내 정상적인 응답이 오는지 확인하고, 정상적인 응답이 오지 않는다면 즉시 알려주는 시스템이 필요합니다.
CLOps 헬스 체크는 모델 헬스 체크 및 이상 감지를 쉽게 수행할 수 있도록 도와주는 시스템입니다. 앞서 말씀드렸듯 CLOps에서는 프로젝트별로 Grafana를 제공하고 있고, Grafana에서는 조건을 설정해서 알람을 발생시킬 수 있습니다. 이때 알람을 사용자에게 전달하려면 알람을 전달받는 사용자 정보가 필요하고, 사용자가 설정한 각 알람 채널에 맞게 알람을 가공할 필요가 있는데요. Grafana를 생성하면서 알람을 가공해 사용자에게 전달하는 Alert Sidecar를 함께 생성해 이를 해결했습니다. 그럼 CLOps 헬스 체크가 어떻게 작동하는지 살펴보겠습니다.
CLOps 헬스 체크 과정
다음은 CLOps 헬스 체크 과정을 나타낸 그림입니다.

-
헬스 체크 요청 명세서 가져오기 사용자가 헬스 체크 요청(method, path, body)과 헬스 체크 주기 등의 내용을 담은 헬스 체크 명세서를 프로젝트 공간에 생성하면, CLOps 헬스 체커가 이를 프로젝트 공간에서 가져옵니다.
-
헬스 체크 수행 CLOps 헬스 체커는 헬스 체크 명세서에 맞게 헬스 체크를 수행한 뒤 언제, 어떤 응답 결과를 받았는지 지표를 생성합니다.
-
헬스 체크 지표 수집 지표가 생성되면 Grafana 헬스 체크 대시보드에서 헬스 체크가 언제 수행됐고 어떤 응답 결과를 받았는지 확인할 수 있습니다.
-
상태 알람 트리거 만약 헬스 체크 요청이 200번대 응답 코드를 받지 못했다면 상태 이상으로 판단하고 Grafana에서 Alert Sidecar에 Alert Webhook을 보냅니다.
-
상태 알람 발송 Alert Sidecar는 사용자의 지표 알람 설정에 따라 메일과 메신저 등의 채널로 보고합니다. 이를 통해 사용자는 빠르게 헬스 체크 이상을 파악할 수 있습니다.
ML 파이프라인
간단한 데이터 파이프라인에서 복잡한 ML 파이프라인에 이르기까지 파이프라인은 데이터 과학의 모든 곳에서 사용하고 있습니다. CLOps는 YAML로 간단하게 파이프라인을 배포할 수 있는 Argo workflows와 다양한 ML 파이프라인 관련 기능을 제공하는 Kubeflow pipelines을 파이프라인 도구로 제공합니다.
Argo workflows
Argo workflows는 쿠버네티스 CRD로 구현된 컨테이너 네이티브 워크플로우 엔진입니다. 워크플로우의 각 작업은 컨테이너 내에서 정의하고 DAG(Directed Acyclic Graph)로 작업간 종속성을 설정합니다. 쿠버네티스 CR을 이용해 손쉽게 워크플로우를 작성하고 배포할 수 있어서 ML 파이프라인 외에도 데이터 ETL이나 CI/CD 자동화 등 다양한 분야에서 사용하고 있습니다.
Kubeflow pipelines
Kubeflow Pipelines는 확장 가능한 ML 워크플로우를 구축하고 배포하기 위한 컨테이너 기반 플랫폼으로 아래와 같이 ML 파이프라인에 특화된 다양한 기능을 제공합니다.
- 자주 사용하는 작업을 재사용할 수 있도록 모듈화하는 기능
- 실행한 작업 결과를 캐시에 저장하고 이후 완전히 동일한 작업은 캐시를 활용해서 전체 실행 시간을 단축하는 기능
- ML 파이프라인에서 생성된 데이터 셋과 모델, 지표 등의 버전을 관리하고 추적하는 기능
- 실행 결과를 쉽게 확인할 수 있는 다양한 시각화 기능
- ML 워크플로우를 작성하고 실행할 수 있는 Python SDK 제공
CLOps에 통합
CLOps에 두 가지 ML 파이프라인 도구를 적용하기 위해서는 CLOps의 다른 컴포넌트처럼 CLOps 인증 시스템을 통해서 멀티 테넌시를 제공해야 합니다. 이는 각 프로젝트에서 생성한 파이프라인 도구를 프로젝트의 네임스페이스에 배포하는 것으로 쉽게 구현할 수 있지만, 그렇게 하면 사용자가 파이프라인 도구의 컴포넌트를 수정하거나 삭제할 수 있게 된다는 문제가 발생합니다. 이 문제를 해결하기 위해 파이프라인 도구는 프로젝트에 대응하는 별도 네임스페이스에 배포하고, 파이프라인 작업만 사용자가 접속할 수 있는 프로젝트의 네임스페이스에 배포하도록 아래와 같이 구현했습니다.
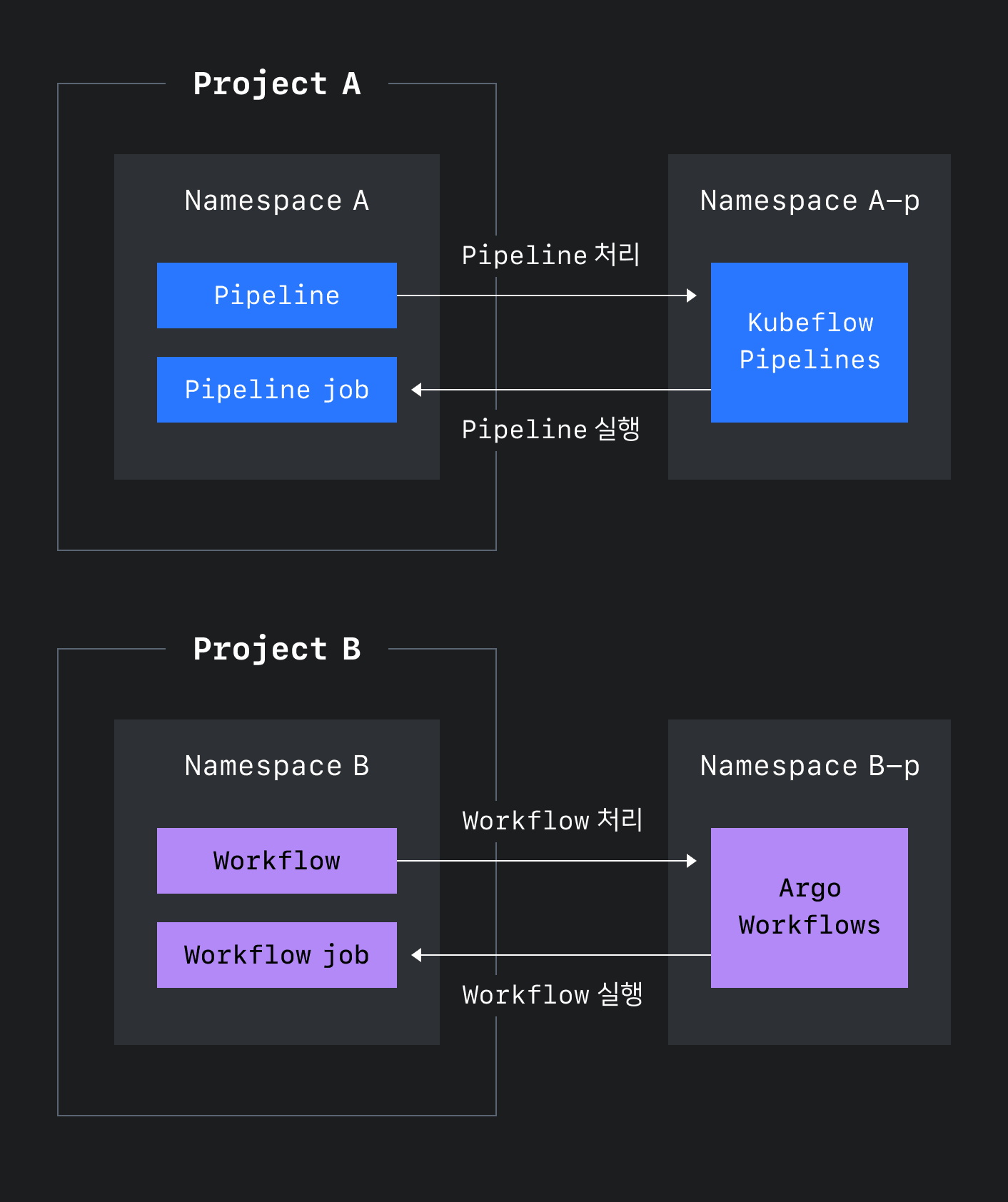
기본 Kubeflow pipelines은 Kubeflow의 Istio와 OIDC Authservice로 제공하는 멀티 테넌시에 의존하고 있기 때문에 스탠드 얼론(stand alone) 설치 스크립트를 수정해 배포하고 있습니다.
사용자는 CLOps를 어떻게 사용할까?
이번 글에서는 CLOps에서 모델을 어떻게 저장하고 사용하는지와 비동기 모델을 어떻게 서빙하는지 살펴봤습니다. 또한 운영에 필요한 모니터링과 헬스 체크, 파이프라인 구성은 어떻게 하고 있는지도 살펴봤습니다. 이어지는 글에서는 사용자가 CLOps를 어떻게 사용하게 되는지 공유하겠습니다.



