






Introduction: 분산 학습 내재화
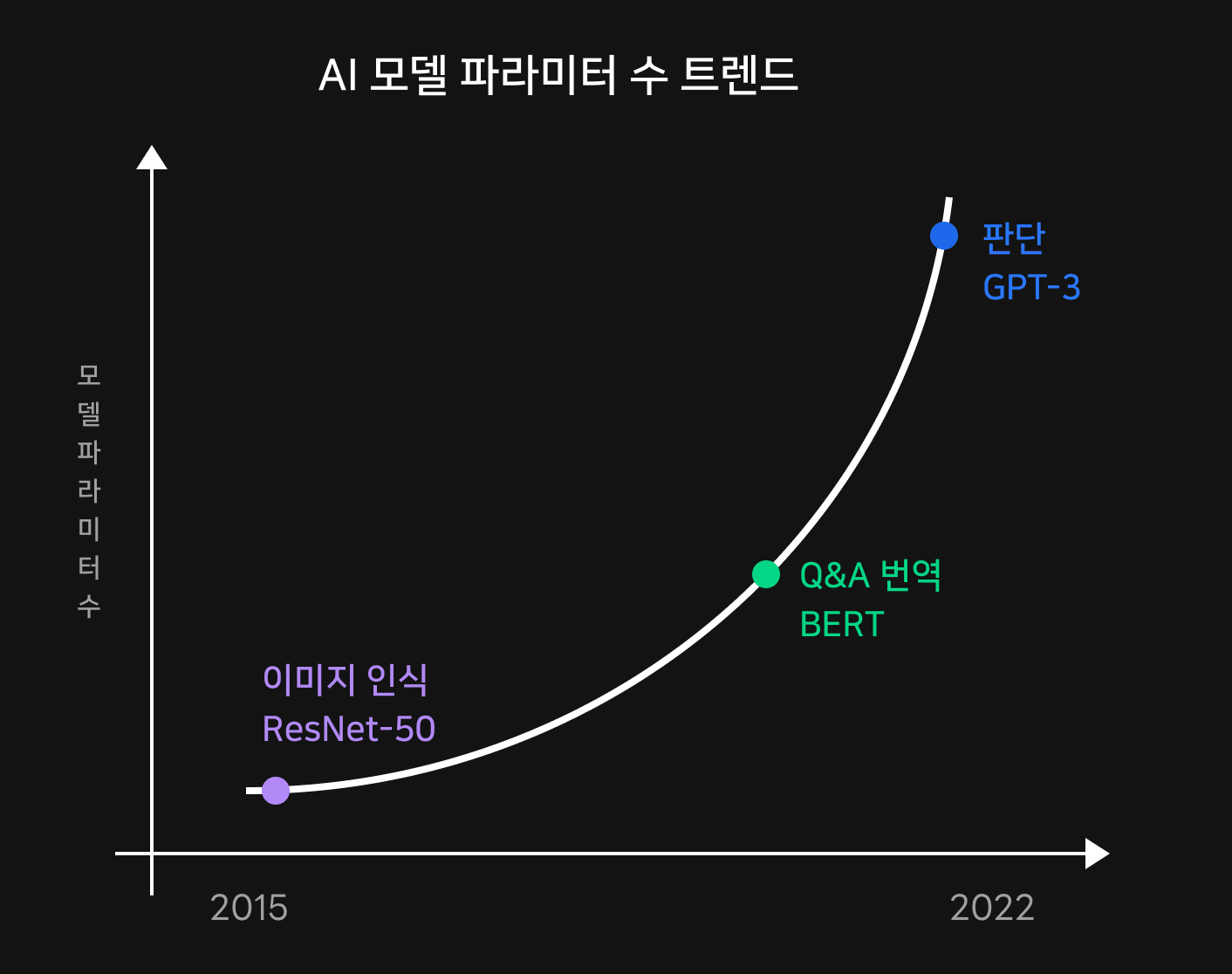
보다 다양한 문제에 대해 올바른 답을 찾아가기 위해 딥러닝 학습은 점점 더 고차원적이고 큰 데이터셋과 모델을 학습하는 방향으로 진화하고 있습니다. 일례로 2020년에 등장한 GPT-3의 파라미터 수는 185B 으로 2년전 BERT에 비해 18배나 많은 크기를 자랑합니다. 학회에서 다뤄지는 최신 연구 트렌드를 보면 모델의 복잡도가 가파르게 증가하는 것을 눈으로 쉽게 확인할 수 있습니다.
이런 트렌드를 놓치지 않고 좋은 성능의 모델을 서비스에 활용하기 위해서는 더 크고 복잡한 모델을 학습할 수 있어야 합니다. 문제는 모델과 데이터셋이 점점 커지면서 더이상 GPU 8장이 붙은 서버 한 대로는 학습을 진행조차 못하는 상황이 도래했다는 것입니다. 이를 극복하기 위해 한 대 이상의 서버를 활용하여 학습하는 '멀티노드 분산 학습'이 등장하게 되었습니다.
분산 학습은 모델과 데이터를 병렬화하여 대규모 학습을 가능케 하고 그 속도를 향상시킵니다. 병렬화하는 대상에 따라 대표적으로 데이터를 분산하는 데이터병렬화와 모델을 분산하는 모델병렬화로 나누어집니다. 좀 더 나아가면 마이크로배치로 데이터를 나눠서 모델병렬화의 GPU 유후 시간을 줄인 파이프라인병렬화나 여러 기법을 조합한 3D 병렬화, 그리고 모델의 내부 상태마저 파티션해서 학습하는 ZeRO(Zero Redundancy Optimizer)까지 여러 다양한 형태의 병렬화 방식이 존재합니다.
좋은 분산 학습 플랫폼을 위한 고민
NSML(Naver Smart Machine Learning)은 사용자의 요청에 맞춰 학습 환경을 구성하고 결과를 종합하여 연구자들이 "모델 개발에 전념하며 인사이트를 이끌어낼 수 있도록" 도와주는 ML 플랫폼입니다. NSML은 이러한 트렌드에 발맞춰 분산 학습에 최적화된 서비스를 제공하면서도 연구자들에게 필요한 학습 플랫폼이 되고자 했습니다. 이를 위해 아래 큰 두가지 고민을 품게 되었습니다.
첫째,
대규모 학습을 뒷받침할 수 있는 튼튼한 인프라 구성과 그 자원을 사용자들에게 공정하게 배분할 수 있는 스케줄링을 도입한다.
분산 학습은 단순히 많은 GPU를 보유한다고 해서 이뤄지지 않습니다. 분산 학습이 제 역할을 톡톡히 해내기 위해서는 GPU에서 학습한 결과들을 유기적으로 합산하고 다시 분배하는 집단 통신이 원활히 이뤄질 수 있어야 합니다. NSML에서는 통신 병목을 해결할 좋은 인프라 구조를 설계하고, 적절한 자원 할당으로 유휴자원을 최대한 줄일 수 있는 효율적인 스케줄링 방법에 대해 깊이 고민하였습니다.
둘째,
대규모 학습을 계획해 투고할 수 있으면서도 실험 결과를 쉽게 디버깅할 수 있는 디자인을 설계한다.
NSML은 연구자들의 모델링에 적합한 ML 플랫폼을 만드는 것에서부터 시작되었습니다. 연구자들의 일반적인 학습 흐름을 비추어 볼 때, 사용자는 초기에 소규모 개인 실험으로 멘탈모델을 확립하고, 이후부터는 대규모 반복 실험으로 좋은 파라미터를 찾는 튜닝 작업을 수행합니다. 문제는 개인 실험에서는 디버깅이 쉽고 자유도가 높은 환경이 필요한 반면, 대규모 학습에서는 자유도보다 반복 및 튜닝을 위해 대규모 학습을 계획할 수 있는 워크플로우가 필요합니다. 이 두 단계를 자연스럽게 연결할 수 있는 방법을 찾아내는 것이 필요했으며, 더 나아가 분산 학습 결과를 하나로 모아 인사이트를 이끌어낼 수 있는 시각화 구성도 갖추어야 했습니다.
NSML의 요소 설명
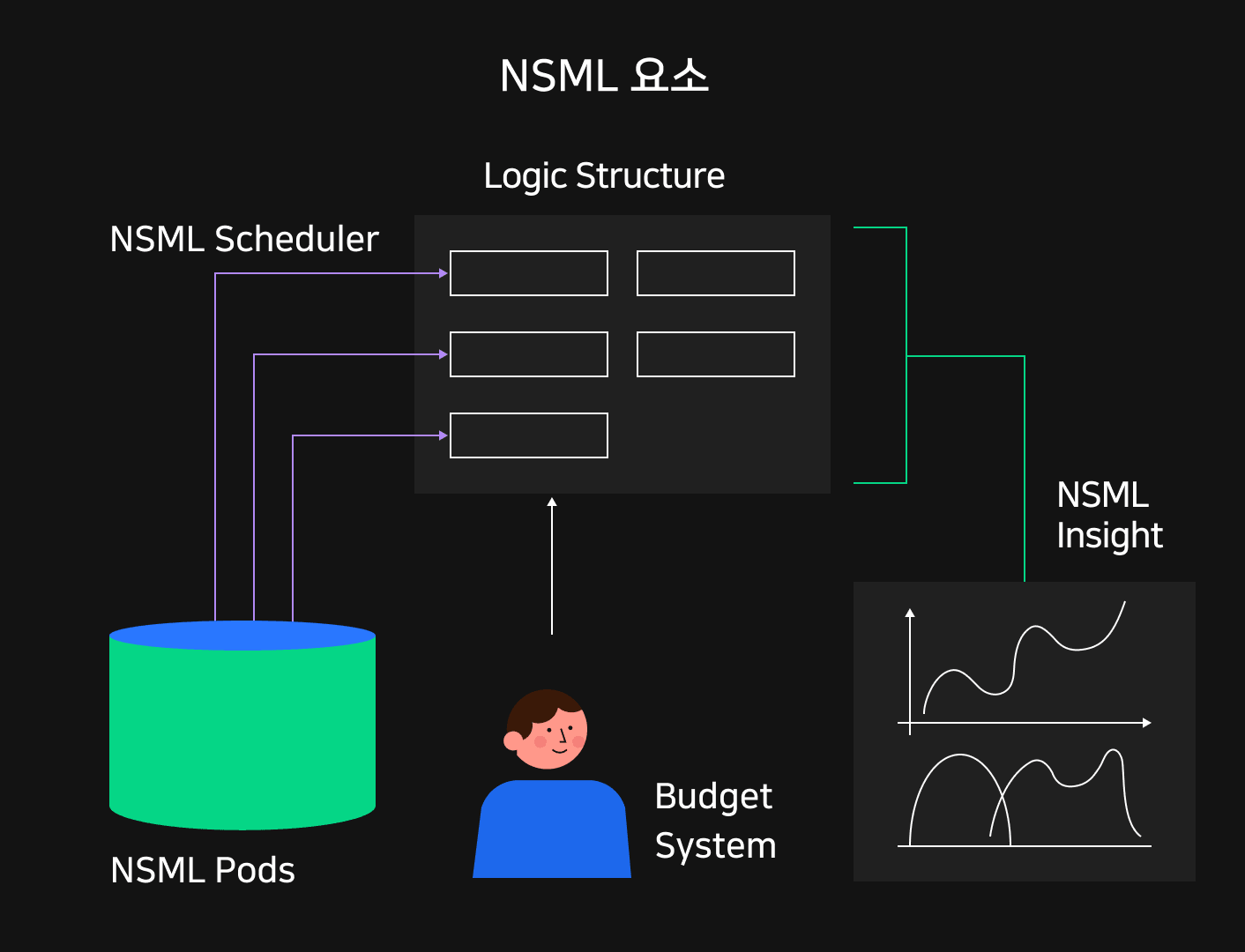
이러한 고민들을 바탕으로 설계된 NSML은 다음과 같은 핵심 요소들을 가지고 있습니다. 아래 주제들을 기억해두시면 앞으로 전해드릴 NSML의 이야기들을 들으실 때 더 깊이 와 닿을 것입니다.
NSML Pods : 분산 학습을 위한 인프라 구성
NSML Pods은 최대 GPU 128장 규모의 모델학습까지 커버할 수 있도록 최적화되었습니다. NSML Pod 내 GPU들은 멀티노드 통신에 특화된 고속 네트워크 IB(InfiniBand)로 묶여 있어 빠른 상호통신이 가능합니다. Pod 마다 고성능 DDN 스토리지가 존재하여 GPU와 직접통신이 가능하도록 구성하였습니다.
NSML 논리적 구성요소 : 여러 학습 유형을 커버하기 위한 디자인
NSML팀이 파악한 연구자들의 학습 유형은 크게 두가지로 나뉩니다. 첫째는 디버깅과 자유도가 필요한 소규모 개인 학습이며 둘째는 튜닝과 반복작업을 투고할 수 있는 대규모 학습입니다. 이를 모두 포함할 수 있도록 NSML에서는 공통의 학습 목적인 프로젝트를 기반으로 프로젝트(Project)-실험(Run)-노드(Node)라는 3층 위계를 두어 학습결과를 관리합니다. 노드는 가장 작은 단위로 SSH 접속이 가능해 직접 로컬에서 디버깅할 수 있습니다. 사용자는 단일 노드를 가진 소규모 실험을 만들어 자유롭게 모델을 수정할 수 있습니다. 이후 멘탈모델이 확립되면 반복적인 튜닝작업을 실험을 계획해 학습을 예약할 수 있습니다.
NSML 스케줄러 : 효율적 자원 활용을 위한 스케줄링
학습은 언제나 한정된 자원에서 이뤄지므로 사용자의 요청에 맞추어 자원을 원활히 분배해야 합니다. 이를 위해 NSML 스케줄러는 의도치 않은 유휴자원을 최대한 줄여 자원의 활용률을 높였습니다. 또한 여러 규모의 실험들이 원활히 배치될 수 있도록 자원의 파편화를 방지합니다. 특히 분산 학습을 고려해서 같은 실험 내 노드들이 한번에 배치될 수 있도록 효율적인 스케줄링을 설계했습니다.
NSML Insight : 인사이트 도출을 위한 학습 시각화
사용자가 실험 결과를 지표(metric)로 기록하면 NSML은 이를 인식하여 표나 그래프의 형태로 자동 시각화합니다. 분산 학습 내 노드들이 출력하는 결과는 하나로 모아져 인사이트를 이끌어낼 수 있도록 재구성됩니다. 이 때, GPU를 포함한 자원 사용량도 같이 표현되므로 개개인마다 GPU 활용률과 전력소모량을 파악해 효율적인 학습이 되었는지 진단해볼 수 있습니다.
NSML 예산체계 : 공정한 자원 배분을 위한 예산 체계
NSML에서는 모든 사용자가 최소한 자신의 소규모 개인실험을 자유롭게 돌릴 수 있도록 보장받습니다. 동시에 프로젝트 관리자가 대규모 실험자원을 구성원들에게 적절히 분배할 수 있도록 예산체계를 구성했습니다. 특히 모두가 대규모 자원을 최대한 공평하게 분배받을 수 있도록 실험 제한 시간과 자동 재등록을 도입했습니다.
NSML Pods 의 역할
다양한 규모의 분산 학습에 대한 지원
연구를 원활히 수행하기 위해서는 딥러닝 학습을 위한 충분한 성능의 인프라가 구성되어 있어야 합니다.
CLOVA 에서는 초대규모 언어모델인 HyperCLOVA를 학습하기 위해 이미 20개의 DGX A100 시스템 그룹으로 모듈화된 NVIDIA DGX SuperPOD을 사용하고 있습니다. SuperPOD은 초대규모 학습에 특화된 하드웨어 구성이지만 그보다는 작은 CLOVA 내 실험 대부분을 지원하는데는 사실 지나치게 큰 사양입니다. 보다 일반적인 환경을 지원하기 위해 NSML은 대다수의 연구 수요에 맞추어 자체 딥러닝 클러스터를 구축해야 했습니다.
NSML Pods는 수십대의 A100 호스트로 이루어진 NSML Pod(연구용 클러스터)의 묶음입니다. 각 Pod은 최대 128장의 GPU를 동시 학습할 수 있는 인프라 구성으로 대규모부터 다수의 중소규모까지 다양한 규모의 분산 학습 실험을 지원할 수 있습니다.
네트워크 병목 현상 해결
모델과 데이터가 작은 경우 단일 GPU로도 충분히 학습이 가능합니다. 이 경우 한 GPU 내에서 모든 연산을 처리하기 때문에 통신 비용을 걱정할 필요가 없습니다. 그러나 한 장 이상의 GPU를 필요로 하는 멀티 GPU 학습의 경우 GPU 간 학습 결과를 공유할 필요가 있습니다.
게다가 분산 학습은 병렬적으로 연산이 이뤄지기 때문에 각 서버의 서로 다른 학습 결과들을 합산하는 과정이 꼭 필요합니다. 실제로 분산 학습에서는 GPU가 연산에 활용되는 시간보다 GPU로 데이터를 로드하고 각 GPU로부터 결과를 합산하는 시간이 총 학습시간을 저하하는 경우가 많습니다. 따라서 수백장의 GPU를 사용하는 것 만큼이나 GPU간 그리고 GPU 서버 간 네트워크 병목을 해소하는 것이 필요합니다.
컴퓨터와 주변장치가 데이터를 주고받을 때 일반적으로 PCIe(PCI Express)라는 대표적인 인터페이스를 사용합니다. 일반적으로 PCIe를 기반으로 멀티 GPU학습을 진행하는 경우 데이터는 GPU간 발생하는 모든 I/O마다 CPU를 거쳐 동기화됩니다. 이 때문에 수많은 데이터들은 GPU에서 CPU의 RAM, Cache, Page 등 많은 흐름을 거쳐 각 단계마다 병목이 발생할 우려가 있습니다.
또한 CPU 성능이 충분하지 못하면 GPU에 데이터를 입출력하는데 어려움을 겪게 됩니다. 예를 들어 보통 GPU는 x16 lane을 지원해 CPU와 양방향 소통이 가능하지만, CPU에서 지원하는 PCI lane 수가 부족하면 연결된 일부 GPU는 x8로 동작하게 됩니다. 이처럼 데이터 통신에서 많은 비효율이 발생하기 때문에 CPU 즉, 시스템 메모리를 거치지 않고 GPU와 GPU 간 직접 통신이 가능할 필요가 있습니다.
RDMA 통신이란
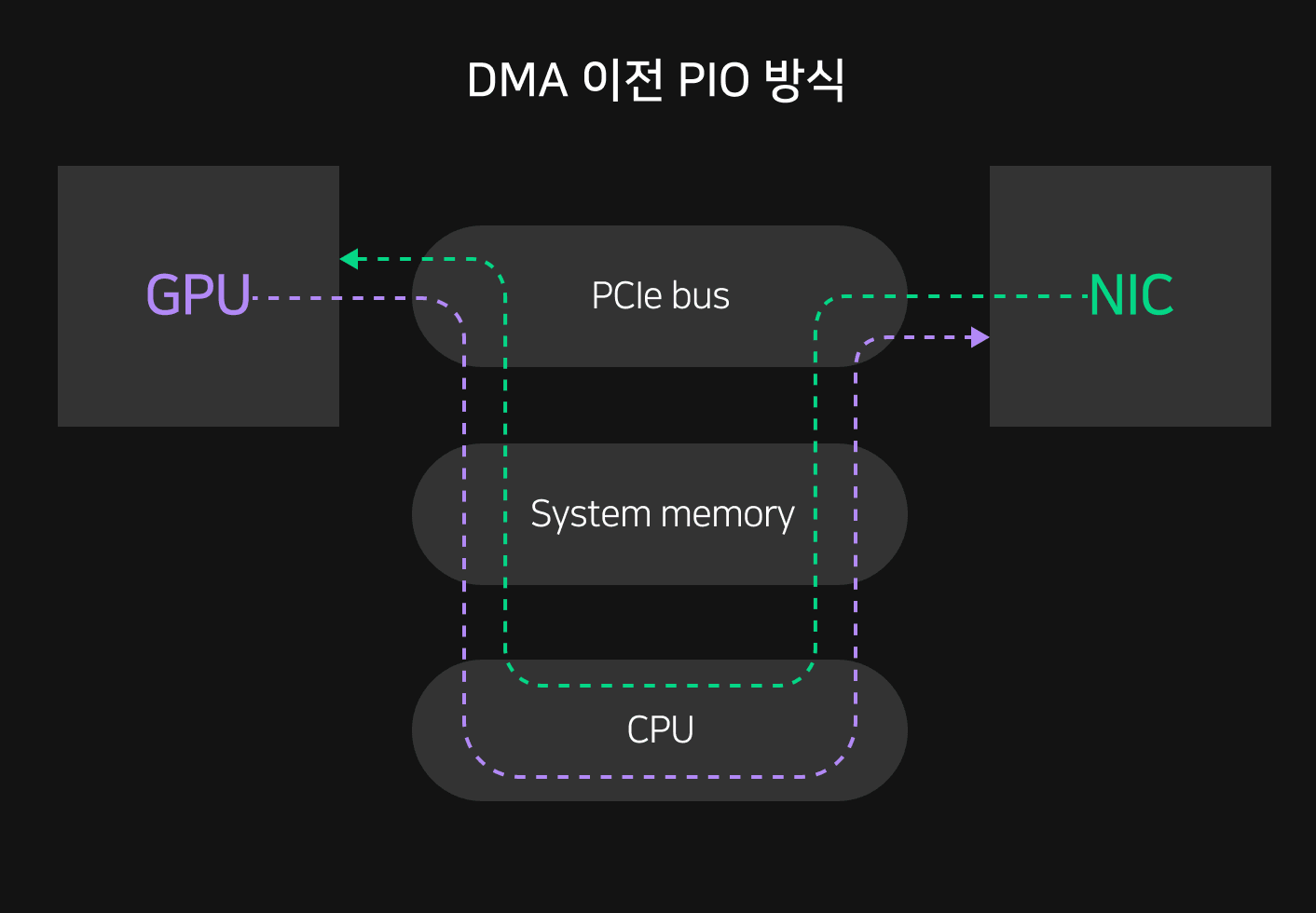
기존의 PIO(Programmed Input/Output) 방식에서는 장치 사이의 데이터 전송을 위해 중앙처리장치인 CPU를 거쳐야만 합니다. 그러나 DMA(Direct Memory Access, 직접 메모리 접근)을 이용하면 중앙처리장치를 거치지 않고, GPU와 입출력 카드가 직접 통신이 가능합니다. DMA는 서버 내부의 버스가 지원하는 기능으로 대개는 메모리의 일정 부분이 DMA 영역으로 사용되어 데이터가 직접 전송되는 동안 CPU가 다른 작업을 수행할 수 있습니다. 즉, DMA를 이용하면 CPU가 가운데서 데이터를 전송하며 입출력 장치의 흐름을 직접 제어할 필요가 없기 때문에 데이터 송수신에 부하가 줄어 시스템 성능을 개선할 수 있습니다.

한 서버 내 메모리 접근 방식을 다룬 것이 DMA라면 서버 간 직접 데이터를 전송하는 기술로 RDMA(Remote Direct Memory Access, 원격 직접 메모리 접근)가 존재합니다. RDMA는 원격 서버의 OS를 통하지 않고 메모리까지 직접 데이터를 주고받는 네트워크 기술입니다. DMA처럼 CPU 거치지 않으므로 낮은 CPU 사용률만큼 빠른 처리 속도와 짧은 네트워크 지연시간을 구현할 수 있습니다.
고속 통신 채널 IB 도입
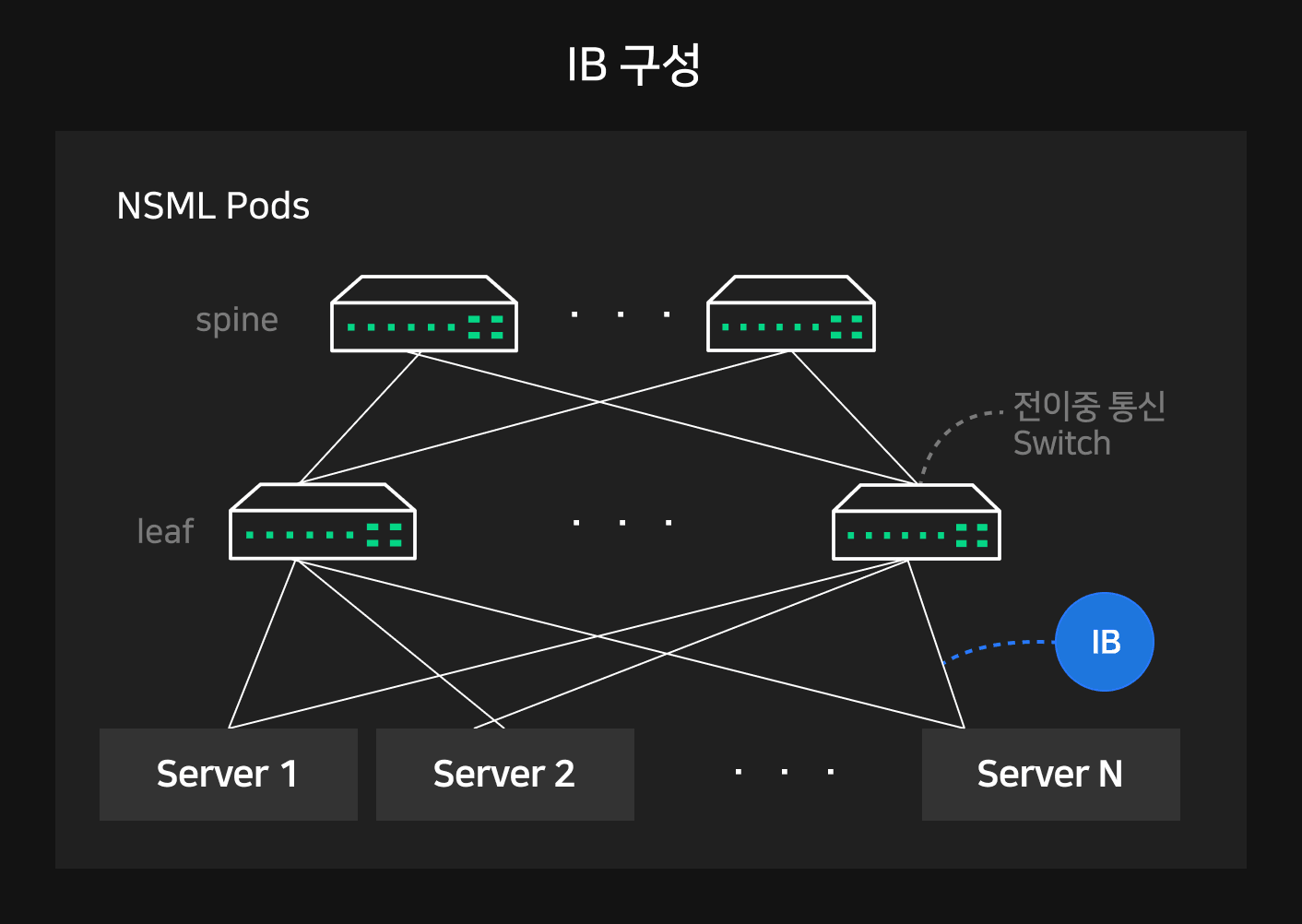
이러한 RDMA 기반의 고성능 네트워크로는 대표적으로 Mellanox의 IB(InfiniBand, 인피니밴드)가 있으며, 이 밖에도 RoCE(RDMA over Converged Ethernet), iWARP(Internet Wide Area RDMA Protocol) 등이 존재합니다. NSML은 이 중 IB를 이용해 딥러닝 클러스터를 구축하였습니다.
NSML Pod의 모든 서버들은 고속 네트워크 카드 HCA(Host Channel Adapter)가 설치되어 있습니다. 서버 내 GPU 통신은 NVLink로, Pod 내 서버 간 GPU 통신은 모두 IB로 구성되어 있습니다.
IB는 원격 노드에서 바로 데이터를 읽어오는 RDMA READ 나 메모리 주소를 지정해 데이터를 기록하는 RDMA WRITE 기능을 사용할 수 있습니다. 특히 NVIDIA에서 제공하는 Kepler 아키텍쳐(2012)와 CUDA 5.0부터 사용가능한 GPUDirect RDMA 기술을 기반으로 InfiniBand HCA 에서 GPU까지 바로 데이터 송수신이 가능합니다.
이에 더해 서버 간 높은 트래픽을 감당하기 위해서 leaf-spine의 이중 스위치 레이어로 네트워크를 구성했습니다. Pod 내 모든 서버의 HCA에 uplink 와 downlink를 두어 1:1 전이중 통신이 가능하며, 다른 서버의 GPU와 1:1로 연결될 때 최대 800Gbps 대역폭으로 통신할 수 있습니다.
다중 읽기 병목 현상 해결
우리는 앞서 분산 학습을 포함한 멀티 GPU 학습에서 GPU 연산 결과를 공유하는 것이 필요했고, RDMA 기반의 IB 구성을 통해 GPU 서버 간 네트워크 병목을 해소할 수 있음을 확인했습니다. 그러나 아직 문제가 하나 더 남아있습니다. 딥러닝 학습에서는 GPU 연산 이전에 스토리지로부터 데이터를 로드하거나 학습 중간중간 결과물을 체크포인트로 저장해야 합니다. 이러한 I/O 과정에 병목이 걸리면 학습 전체 과정에 GPU 활용률이 낮아지고 학습 시간을 침해하는 결과를 일으키게 됩니다.
보통 대규모 학습 데이터는 저장을 위해 초기에 큰 순차 쓰기(sequential write)가 발생하고, 이 후 학습과정에서는 주기적인 램덤 읽기(random read)가 일어납니다. 특히 분산 학습에서는 여러 GPU들이 같은 데이터에 동시 접근하기 때문에 GPU와 가장 잦게 접촉하는 스토리지는 충분한 동시 랜덤 읽기 성능을 갖추어야 합니다.
고속 스토리지 DDN 도입
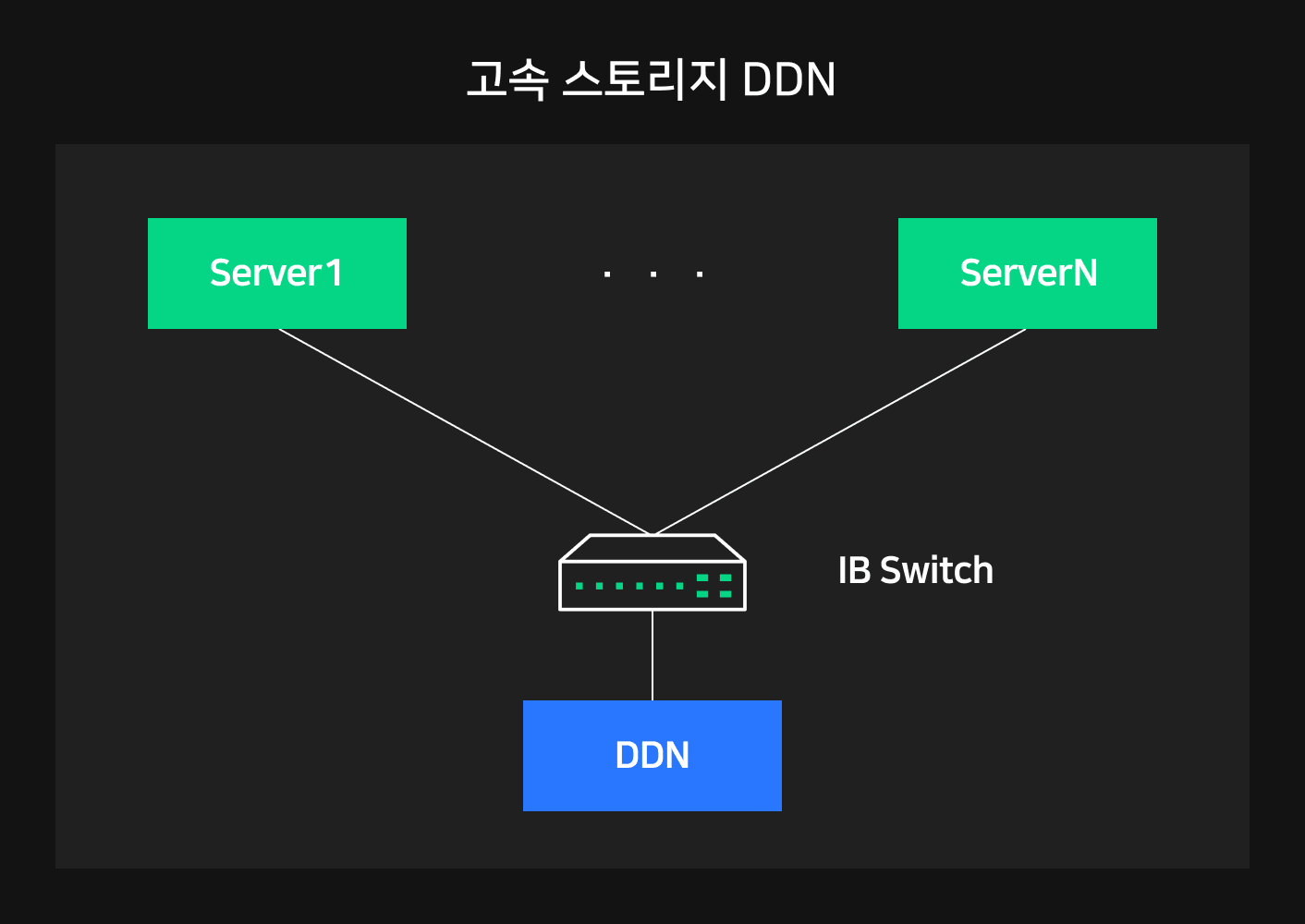
이를 해결하기 위해 NSML은 DDN(DataDirect Network) 고속 스토리지를 도입했습니다. DDN은 Lustre 파일 시스템을 기반으로 A100 Pod 구성에 최적화되어 있으며, NVIDIA 파트너 솔루션으로 전세계 최대 SuperPOD 환경에서 이미 검증된 스토리지 플랫폼입니다. 병렬 파일 시스템으로 동시 접근을 허용해 확장이 쉽고, 다양한 사용자 요구사항과 워크로드를 처리할 수 있도록 IOPS와 대역폭에서 가장 좋은 성능을 보여주고 있습니다.
NSML은 NSML Pod 마다 하나의 DDN 스토리지를 두고 있습니다. 그리고 DDN 스토리지는 NSML Pod 내 모든 호스트와 IB로 연결되어 있습니다. 따라서 여러 노드가 동시에 DDN 스토리지에 접근할 때 최대 800Gbps 대역폭으로 통신이 가능합니다. 또한 IB 구성을 기반으로 한 GPUDirect Storage 기술을 통해 GPU 메모리와 원격 스토리지가 직접 데이터를 송수신할 수 있습니다.
이러한 특성을 활용하여 NSML에서는 학습 데이터셋을 캐시하는 용도로 DDN 스토리지를 이용합니다. DDN은 우선 여러 노드에 공유될 수 있으며 충분한 I/O 병렬성을 보장하고 있습니다. 그리고 GPU와 직접통신이 가능해 DDN의 데이터를 GPU로 빠르게 송신할 수 있습니다. 따라서 DDN에 데이터를 캐시하면 배치 크기만큼 학습 데이터를 반복적으로 읽는 구간에서 학습 효율을 크게 높일 수 있습니다.
1편에서는 NSML이 어떻게 시작되었으며 무슨 구성 요소들을 갖추고 있는지 그리고 그 중 NSML Pods은 어떠한 문제들을 해결하기 위해 구성되었는지 이해해 보았습니다. 다음 편에서는 NSML의 논리적 구성요소와 대표적인 오케스트레이션 도구인 Kubernetes에서 이를 어떻게 구현했는지 설명해보도록 하겠습니다.


