




쿠버네티스 기반으로 분산 학습 오케스트레이션 구조 확립
사용자의 요청에 맞춰 GPU 자원을 할당해 개인 실험을 구성하기 위해서는 좋은 오케스트레이션 시스템을 기반 기술로 삼아야 했습니다. 쿠버네티스는 컨테이너 기반 오케스트레이션 시스템의 한 종류로 사실상 표준으로 사용되고 있습니다. NSML(Naver Smart Machine Learning)에서는 쿠버네티스를 기반으로 GPU 서버를 관리하고 사용자의 요청에 따라 적합한 컨테이너 환경을 제공하고자 했습니다.
그러나 쿠버네티스는 컨테이너화된 애플리케이션을 자동으로 배포하거나 확장, 관리하는 데 특화된 시스템입니다. 컨테이너들을 논리 단위로 그룹화하고 유연하게 확장하는 데는 유리하지만, ML 학습에 맞춰 컨테이너를 구성하고 결과를 시각화하기에는 어려운 점들이 있었습니다. 이 때문에 NSML은 ML 분산 학습에 맞춰 쿠버네티스의 리소스 체계를 재구성할 필요가 있었습니다.
NSML의 논리 체계와 쿠버네티스의 리소스 매칭
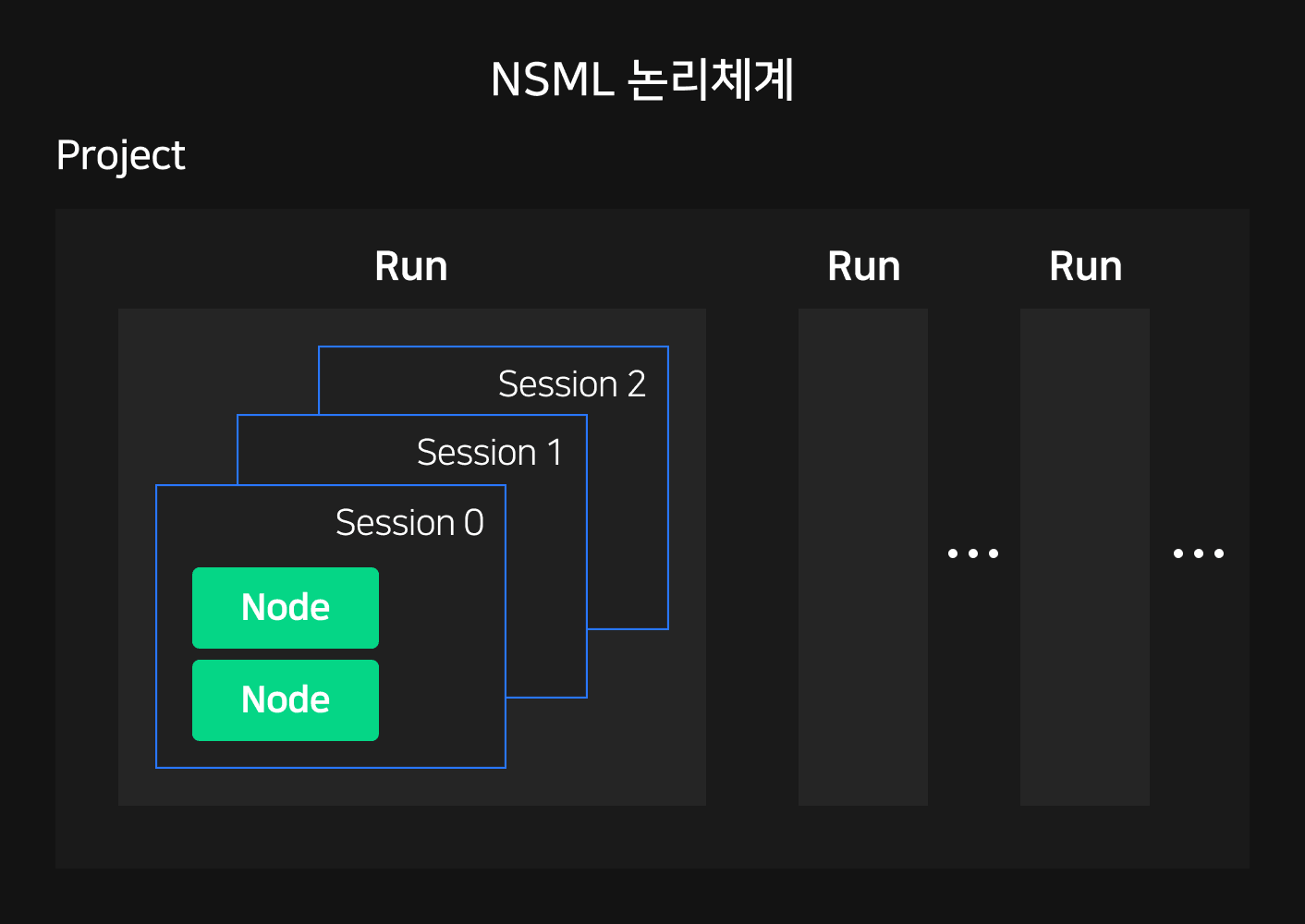
1편에서 소개한 것처럼 NSML에서는 프로젝트(Project)-실험(Run)-노드(Node)의 논리 체계(logical structure)를 구성해 학습 결과를 관리합니다. NSML에서 최소 기본 단위인 노드는 자유도가 높은 소규모 개인 실험을 커버합니다. 그 위로 여러 노드를 엮어 분산 학습을 가능하게 하는 실험이 존재하며, 가장 상단에는 공통의 실험 목적으로 이들을 한번에 관리하는 프로젝트가 위치합니다.
프로젝트 관리자가 프로젝트를 생성하고 연구자를 초대하면 연구자는 자신의 실험 계획을 생성해 학습을 진행할 수 있습니다. 연구자가 실험으로 서버 한 대 이상을 사용하는 분산 학습을 설정하면, 서버마다 노드를 하나씩 생성하고 각 노드는 SSH로 접근할 수 있도록 로컬 디버깅 환경을 제공합니다. 여러 번의 학습 후 멘탈 모델이 확립되면 세밀한 튜닝 작업을 실험으로 미리 예약해 진행할 수 있습니다.
이때 실험은 여러 세션(session)으로 반복할 수 있습니다. 여기서 세션이란 실험에 필요한 모든 노드가 배정된 상태를 유지하는 것을 말합니다. 실험 내 모든 노드가 학습을 마치거나 외압으로 중단되면 실험이 완료되며, 사용자의 요청으로 종료된 실험이 재등록되면 새로운 세션이 시작됩니다.
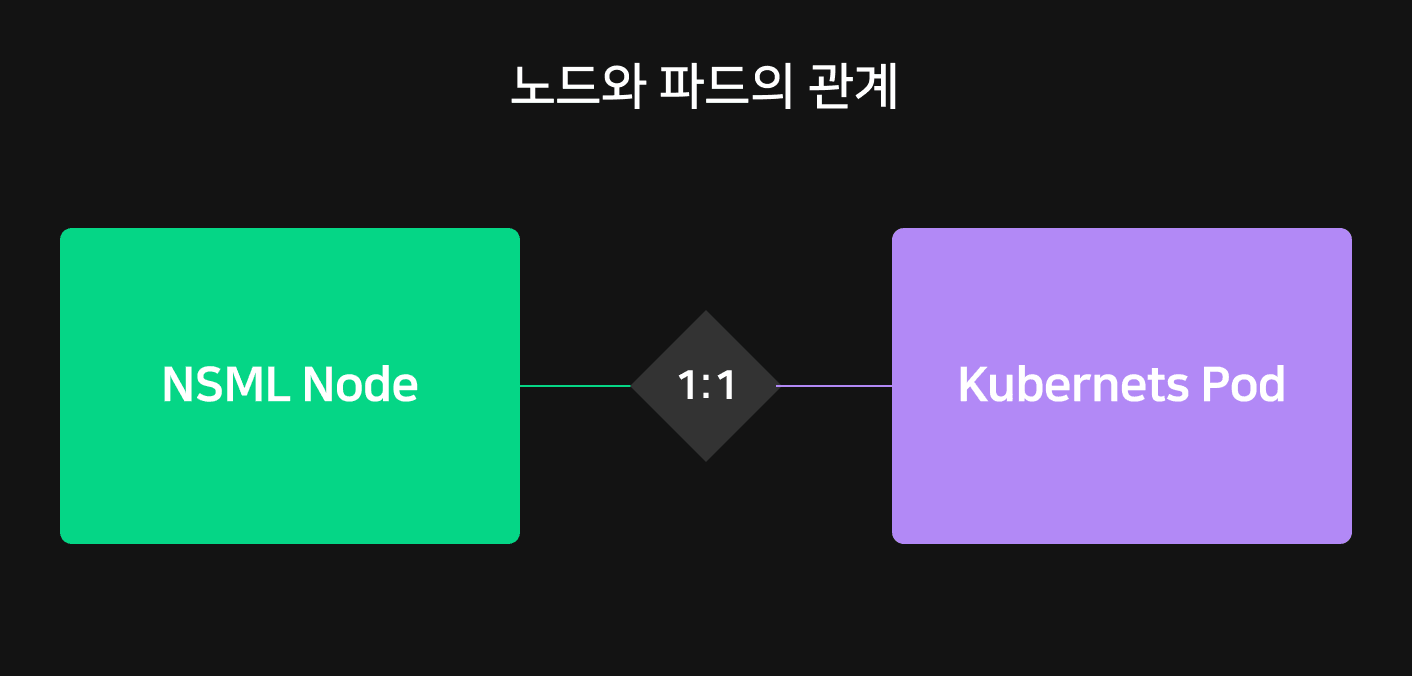
쿠버네티스 리소스 체계에서 가장 작은 컴퓨팅 단위는 파드(pod)입니다. 파드는 개별 생성 및 배포가 가능하지만 일반적으로 쿠버네티스 사용자가 파드만 따로 생성하는 경우는 거의 없습니다. 파드는 상대적으로 일시적인 환경을 위한 엔티티로 설계됐기 때문에 보통 디플로이먼트(Deployment)나 잡(Job), 스테이트풀셋(StatefulSets)과 같은 워크 로드 리소스를 사용해 파드를 생성합니다.
하지만 애플리케이션 배포가 아닌 ML 학습이 주 목적인 경우 모델이 학습하는 동안에만 살아있고 학습이 끝나면 정리되는 리소스가 필요합니다. NSML에서는 파드를 직접 생성하고 실험이 종료될 때 트리거하여 삭제합니다. 파드의 생명 주기를 직접 관리하기 때문에 NSML의 정책에 맞추어 노드를 통제할 수 있습니다.
이와 같은 이유로 NSML에서는 실험의 최소 단위인 노드를 쿠버네티스의 가장 작은 생성 및 관리 단위인 파드와 1:1로 매핑했습니다.
NSML 노드와 쿠버네티스 연결
NSML 노드를 생성하기 위한 파드 명세에는 할당 자원의 사양, SSH를 포함한 기본 환경 구성, 스케줄러 관련 설정과 각종 볼륨 및 포트 할당 등의 내용이 들어갑니다. 스케줄러를 포함한 기타 설정들은 이후 심도 있게 다룰 내용이므로 여기서는 사용자의 요청에 맞는 자원 할당에 대해서 설명하겠습니다.
apiVersion: v1
kind: Pod
…
spec:
containers:
- name: node-foo-container
resources:
limits:
cpu: "15"
ephemeral-storage: 32Gi
memory: 384Gi
nvidia.com/gpu: "2"
rdma/hca_shared_devices_a: "1"
…
NSML에서는 사용자의 여러 요구 사항에 맞게 미리 설계한 다양한 자원 옵션을 제공합니다. 원하는 옵션을 선택하면 파드를 생성할 때 선택한 설정에 적합한 CPU와 메모리 크기 등을 쿠버네티스에 전달합니다. 이때 쿠버네티스에서 GPU를 인식하게 하기 위해서는 GPU 드라이버가 설치된 서버에서 관련 업체(여기서는 NVIDIA)의 장치 플러그인(device plugin)을 실행해야 합니다. 설정이 완료되면 GPU 자원은 nvidia.com/gpu와 같이 쿠버네티스에서 스케줄링 가능한 리소스로 공개됩니다.
또한 1편에서 설명한 IB(InfiniBand)와 GPUDirect RDMA 통신을 위한 HCA(Host Channel Adapter)를 쿠버네티스 파드에 제공하기 위해서는 IB 개발사인 Mellanox에서 제공하는 k8s-rdma-shared-plugin 을 설치해야합니다. 데몬셋을 설치하고 나면 파드를 생성할 때 자원 스펙에 rdma/hca_shared_devices_a를 설정하여 IB 기반 RDMA 통신이 가능해집니다.
NSML 실험과 쿠버네티스 연결
분산 학습을 커버하는 실험은 하나 이상의 노드로 구성되며, 각 노드는 쿠버네티스 파드로 생성됩니다. 이때 실험은 분산 학습에서 노드를 동시 배치하기 위한 NSML의 논리 단위입니다. 앞서 설명했듯이 디플로이먼트나 스테이트풀셋과 같이 파드를 기반으로 하는 쿠버네티스의 기본 오브젝트들은 ML 학습이 아닌 애플리케이션 배포에 특화돼 있어서 실험을 표현하기에는 적절하지 않습니다.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: podgroups.scheduling.sigs.k8s.io
spec:
conversion:
strategy: None
group: scheduling.sigs.k8s.io
names:
kind: PodGroup
…
NSML에서는 쿠버네티스의 커스텀 리소스(custom resource, cr)을 이용해 실험을 표현하고 여러 노드를 하나의 그룹으로 묶어 관리합니다. CRD(custom resource definition)를 통해 커스텀 리소스를 등록하면, 파드와 같은 쿠버네티스 빌트인 리소스와 마찬가지로 쿠버네티스 API를 통해 생성하거나 수정, 삭제할 수 있습니다.
실험은 PodGroup이라는 CR로 형성됩니다. PodGroup은 NSML scheduler에 적용된 coscheduling plugin이 여러 파드를 한번에 배치할 수 있도록 파드의 묶음을 정의한 리소스입니다. 이는 향후 NSML 스케줄러가 분산 학습 내 여러 노드들을 한 번에 배치할 수 있도록 하는 기반이 됩니다. 보다 상세한 과정은 다음 스케줄러 편에서 다룰 예정입니다.
분산 학습을 위한 네트워크 정책 설정
분산 학습은 여러 호스트에서 병렬로 학습을 진행하므로 각 호스트에 파라미터를 전달하거나 호스트별 연산 결과를 동기화할 수 있어야 합니다. 이를 위해서 같은 실험 내 모든 노드들은 서로 자유롭게 통신할 수 있어야 합니다.
쿠버네티스는 기본적으로 파드 간 모든 통신을 격리하지 않습니다. 이 때문에 같은 클러스터에서 생성된 모든 노드들은 서로 어떤 실험에 속해 있든지 통신이 가능합니다. 그러나 이는 타인의 실험에 속한 노드에도 접근할 수 있다는 뜻이기 때문에 의도치 않은 간섭이 발생할 수 있습니다. 이를 방지하기 위해서는 분산 학습을 진행하는 노드 외에 다른 노드가 분산 학습 노드 그룹에 접근할 수 없게 막아야 합니다.
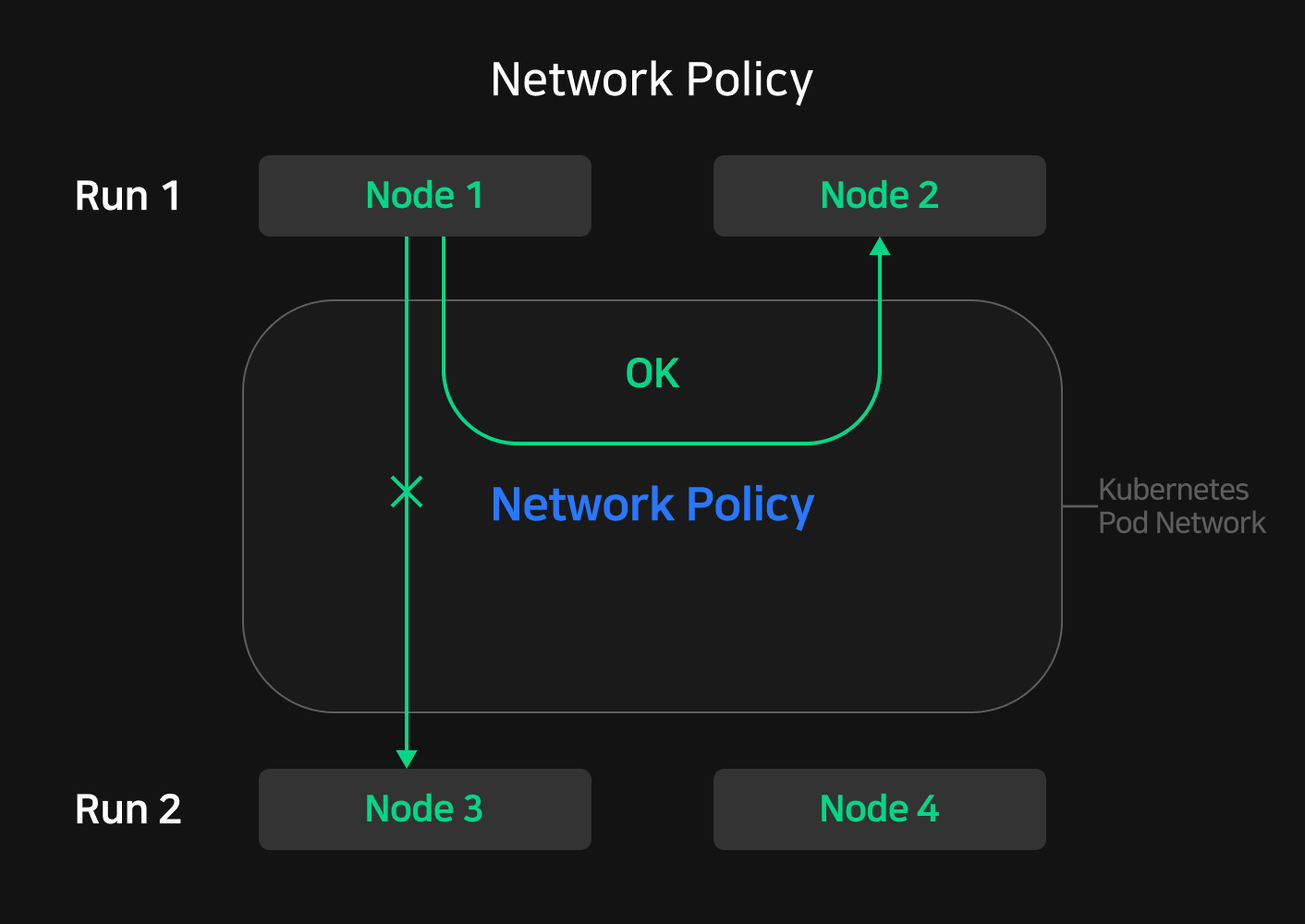
쿠버네티스의 NetworkPolicy를 이용하면 파드의 트래픽 흐름을 제어해 화이트 리스트 방식으로 특정 노드에 대해서만 접근을 허용할 수 있습니다. NetworkPolicy에는 ingress와 egress 필터가 있고 각각 인바운드와 아웃바운드 연결을 제어합니다. NSML에서는 같은 실험 내 노드 간에만 통신할 수 있고 외부의 다른 노드는 실험 내부 노드에 접근할 수 없도록 각 실험마다 ingress 필터를 적용한 NetworkPolicy를 사용하고 있습니다.
동일 실험 내 노드와 외부 노드와의 통신은 적절히 제한했지만 아직 불편한 점이 남아있습니다. 분산 학습을 구성하는 노드가 다른 노드를 지칭하기 위해서는 쿠버네티스가 부여한 파드의 IP를 확인하거나 네임스페이스, 파드 이름 등으로 구성된 긴 FQDN(Fully Qualified Domain Name)을 알고 있어야 합니다. 이런 불편함을 해소해 사용자가 노드를 쉽게 지칭할 수 있도록 실험 내 노드마다 적절한 엔드포인트를 제공하는 것이 필요했습니다.
분산 학습 내 노드들이 같은 서브 도메인에 속하게 만들면 긴 FQDN 없이도 사용자가 각 노드를 쉽게 지칭할 수 있습니다. 쿠버네티스 헤드리스 서비스(headless service)를 만들고, 같은 실험 내 노드를 나타내는 파드 스펙의 dnsConfig에 만들어 준 서브 도메인을 검색 도메인으로 추가합니다. 추가 이후에는 같은 실험에 속한 파드들은 같은 서브 도메인에 속하게 되므로 파드의 호스트명만으로도 쉽게 통신할 수 있습니다.
쿠버네티스 파드의 휘발성 극복
NSML 노드와 1:1로 연결되는 쿠버네티스 파드는 디플로이먼트나 스테이트풀셋, 데몬셋과 같이 배포에 특화된 다른 쿠버네티스 오브젝트와는 다르게 휘발성이 높습니다. 다른 애플리케이션과는 달리 학습을 목적으로 실행되는 파드는 이런 휘발성을 이용해 학습 사이클에 맞춰 파드를 생성하고 종료할 수 있습니다.
이때 학습 결과와 학습 환경에 대한 정보는 그대로 남겨 다음 학습에 사용할 필요가 있습니다. 분산 학습에서는 여러 노드가 동일한 데이터셋을 참조할 수 있어야 하고, 서로의 결과물을 쉽게 공유할 수 있어야 할 뿐 아니라, 학습이 종료된 이후에는 결과 지표와 실험 환경 구성에 대한 정보를 바탕으로 다음 실험을 원활하게 지속할 수 있어야 하기 때문입니다. NSML에서는 이런 측면을 고려해 학습 데이터와 결과를 공유할 수 있는 스토리지와, 학습 환경 구성을 저장해 다시 이용할 수 있는 이미지 저장 기능을 마련해 놓았습니다.
학습 데이터셋 공유를 위한 스토리지 제공
파드는 종료 후에 학습 결과를 보존하지 않으므로 의도치 않게 학습이 종료되는 경우를 대비해 별도의 스토리지를 마련했습니다. NSML에서는 여러 노드 간 데이터를 공유할 수 있으면서, 용도에 맞게 다양한 형태의 스토리지를 마련했습니다.
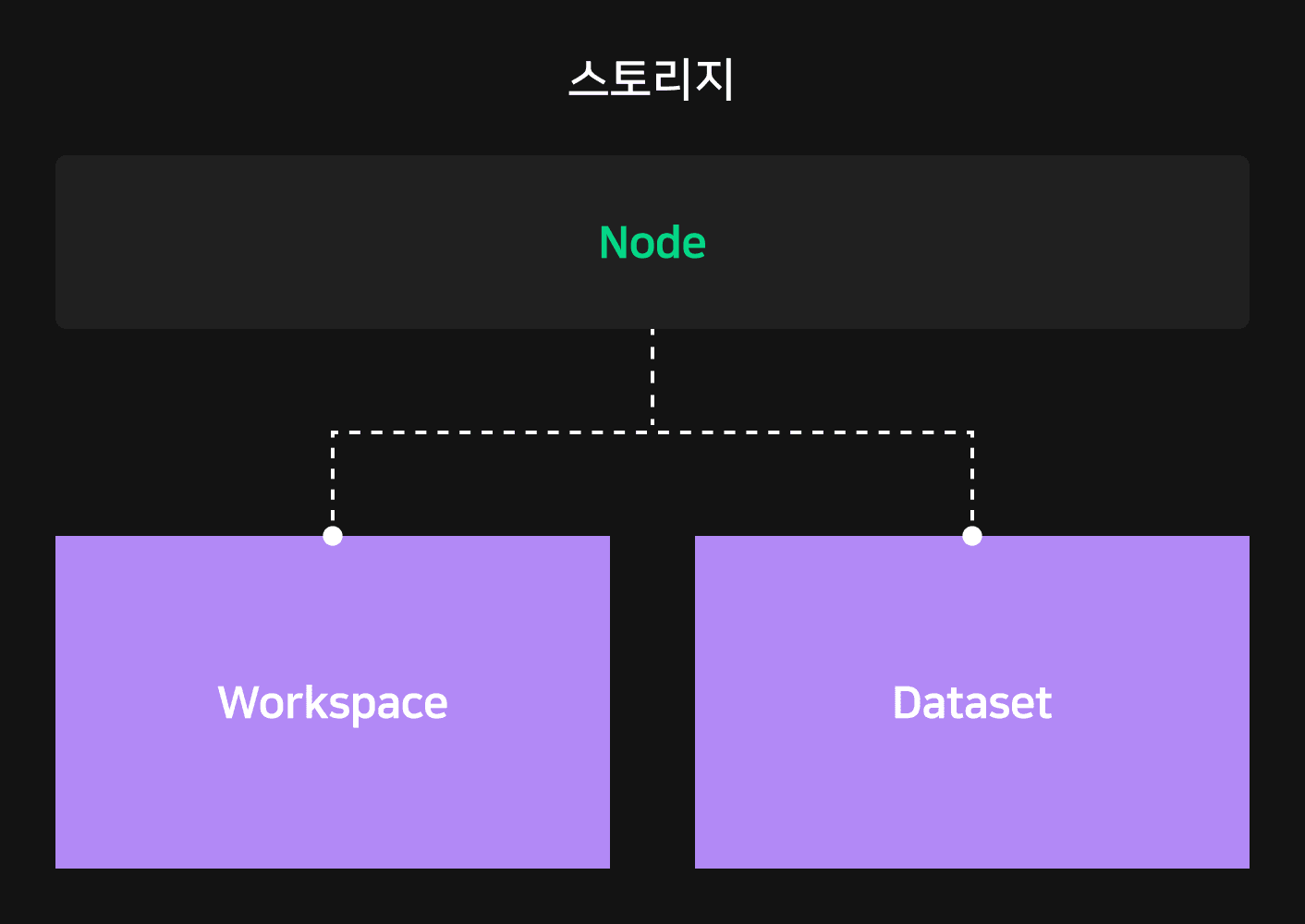
먼저 프로그램을 기동하기 위한 코드와 로깅, 체크 포인트, 메타데이터를 임시 저장하기 위한 목적으로 워크스페이스(workspace)를 제공합니다. 워크스페이스는 Ceph File System을 이용해 구성했으며 여러 노드가 공유할 수 있는 형태의 스토리지입니다. 학습 데이터를 기록하는 목적이 아니므로 읽기와 쓰기의 대역폭을 늘리기보다는 프로젝트마다 충분한 용량을 제공하는 데 초점을 뒀습니다.
워크스페이스와는 다르게 학습 데이터셋을 저장하고 공유하는 게 목적인 데이터셋(dataset)도 제공합니다. 데이터셋은 수정될 일이 별로 없으면서 검색 속도가 빨라야 하는 초대용량 데이터를 저장하기 위해 Ceph Object Storage로 구성했습니다. 워크스페이스와 마찬가지로 여러 노드가 공유하면서 많은 노드가 접근해 데이터셋을 읽을 수 있도록 충분한 I/O 병렬성을 보장하는 데 중점을 뒀습니다.
분산 학습 내 동일 환경을 구성할 수 있는 이미지 저장 기능 제공
ML 연구자들은 서로의 논문을 비교하거나 공동 연구를 진행하는 경우가 많습니다. 또한 자신의 이전 실험 환경을 복원해 다시 학습해야 하는 경우도 있습니다. 이와 같이 공동으로 연구하거나 과거에 실행한 학습을 재현하기 위해서는 동일한 실험 환경을 보장하는 것이 매우 중요합니다.
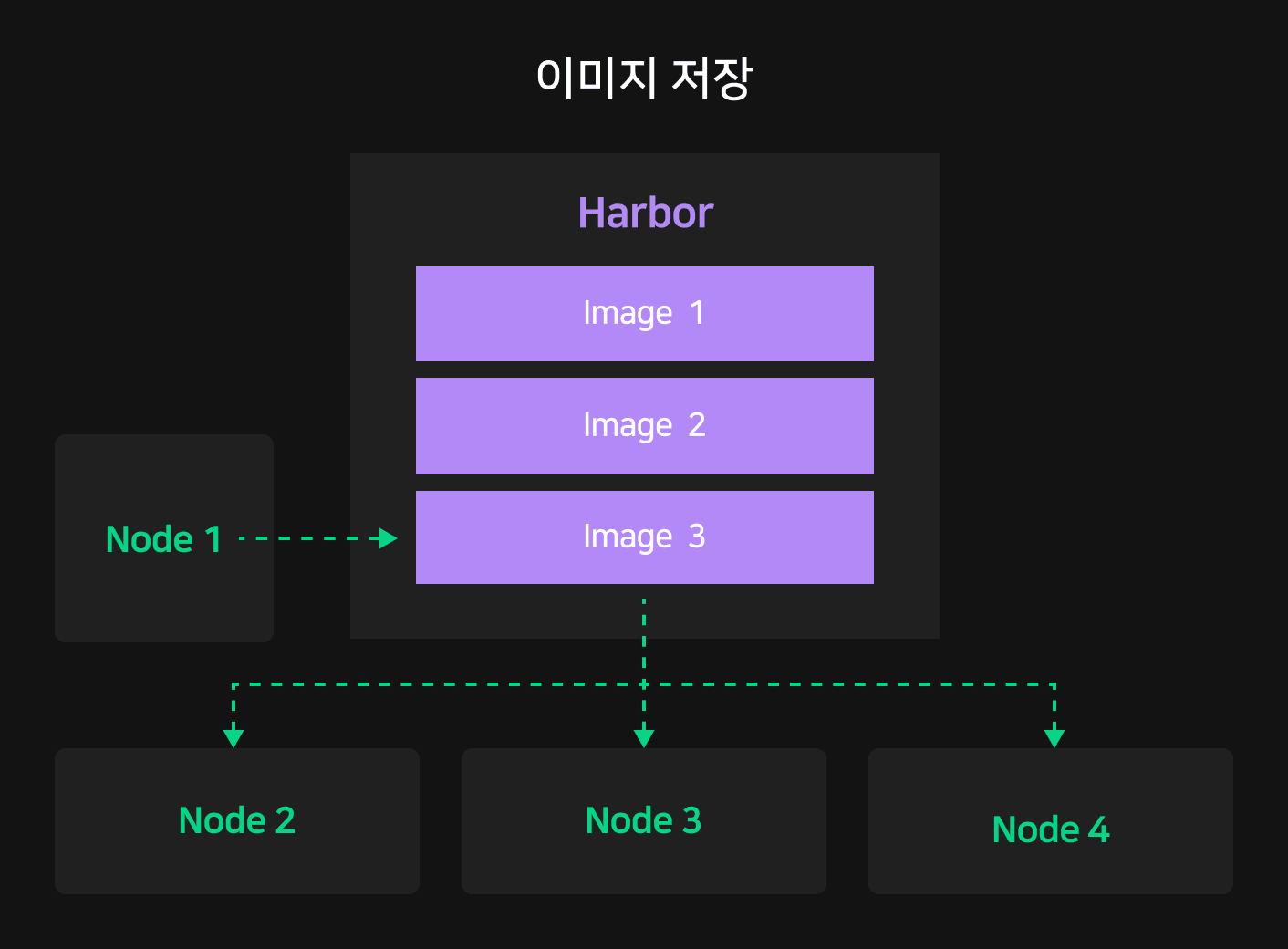
NSML에서는 스토리지 외에 자신의 모델링 환경을 복제해 커스터마이징할 수 있는 이미지 저장(save image) 기능을 제공합니다. 이미지 저장 기능을 이용하면 사용자는 쉽게 분산 학습 실험 내 노드마다 동일한 환경을 구성할 수 있고, 언제든지 이전 실험 환경을 복원해 다시 학습할 수 있습니다.
사용자가 이미지 저장을 요청하면 NSML은 노드가 실행되고 있는 호스트에 DooD(Docker out of Docker)로 새로운 파드를 실행합니다. 파드는 동작 중인 노드의 현재 상태를 커밋하여 사용자가 구성한 환경을 그대로 저장합니다. 저장한 이미지는 Harbor로 전송되며 사용자가 요청하면 언제든지 만들어진 이미지로 새롭게 노드를 생성할 수 있습니다.
이번 글에서는 NSML이 쿠버네티스의 CRD나 NetworkPolicy와 같은 여러 오브젝트를 어떻게 활용하여 ML 분산 학습 플랫폼을 구성했는지 확인해 봤습니다. 이어지는 글에서는 NSML이 자원의 파편화를 막고 공정한 자원을 분배하기 위해 어떤 고민을 바탕으로 NSML 스케줄러를 개발했는지 알아보겠습니다.

