


이번 글은 CLOps 시리즈의 세 번째 편으로 ML 서빙 플랫폼 CLOps의 컴퓨팅 리소스 관리를 담당하는 컴포넌트들에 대해 이야기하고자 합니다.
컴퓨팅 리소스는 CPU와 GPU, 메모리 등을 일컫는 말로 플랫폼에서 서비스에 할당합니다. 플랫폼에서 리소스를 스케줄링해 서비스에 할당하고 회수하는 작업을 리소스 관리라고 하며, 좋은 리소스 관리란 필요한 시간 동안 필요한 리소스만 서비스에 할당하는 것입니다. 서비스에 리소스를 너무 과도하게 할당하면 리소스 낭비가 발생하거나 다른 서비스가 리소스를 할당받지 못하는 상황이 발생할 수 있습니다.
이번 글에서는 컴퓨팅 리소스를 효율적으로 할당하고 회수하며 관리하기 위한 CLOps의 컴포넌트들을 자세히 알아보겠습니다.
스케줄링 측면에서 GPU 리소스를 관리할 때 발생하는 문제
최근 AI 모델이 점점 거대해지면서 연산량이 증가함에 따라 서빙 요청에 대한 추론 시간이 늘어나고 있습니다. 이런 특성 때문에 학습 단계뿐 아니라 서빙 단계에서도 GPU를 사용하는 모델 애플리케이션이 늘어나고 있고, 더 나아가 초거대 AI 모델의 경우에는 멀티 코어 GPU를 사용해 모델을 병렬화(model parallelism)해 모델 애플리케이션을 배포하기도 합니다. 이에 따라 효율적으로 모델 애플리케이션을 서빙하기 위한 GPU 리소스 관리가 중요해지고 있습니다.
쿠버네티스는 기본적으로 애플리케이션에 리소스를 할당하는 서비스 품질(Quality of Service, QoS)을 조절하기 위해 아래와 같은 세 가지 정책을 제공하고 있습니다.
Guaranteed: 할당된 리소스를 반드시 보장받을 수 있는 정책Burstable: 사용할 수 있는 여분의 리소스가 있다면 할당된 리소스를 넘어서 사용할 수 있는 정책BestEffort: 마지막으로 배치된 서버에 남아 있는 모든 자원을 최선으로 사용하는 정책
이와 같은 리소스 서비스 품질 정책을 이용하면 쿠버네티스 클러스터에서 컴퓨팅 리소스를 효율적으로 사용할 수 있습니다. 쿠버네티스는 선택한 서비스 품질 정책을 기반으로 할당 가능한 노드를 선정하고, 애플리케이션을 안정적으로 운영하기 위해 다수의 노드로 분산해 배포할 수 있도록 스케줄링하는 정책을 기본으로 사용하고 있습니다.
하지만 이와 같은 쿠버네티스의 기본적인 리소스 서비스 품질 정책과 스케줄링 정책을 그대로 사용하면, CPU와 메모리만 사용하는 애플리케이션과는 달리 GPU를 사용하는 애플리케이션의 리소스는 효율적으로 사용하는 데 한계가 있습니다. GPU 리소스를 사용할 때는 guaranteed 정책만 사용할 수 있기 때문입니다.
또한 CLOps에서는 잠재적인 보안 문제로 GPU 코어에 대한 애플리케이션간 공유를 허락하지 않고 있어서 CPU처럼 노드 가용량보다 더 많은 리소스를 애플리케이션에게 할당하기가 어렵습니다.
이 두 가지 제약 사항은 GPU 리소스의 단편화를 유발하며, 아래 그림 1과 같이 리소스가 충분히 있음에도 모델 애플리케이션을 스케줄링하지 못해 리소스를 효율적으로 관리하지 못하는 문제를 야기합니다.
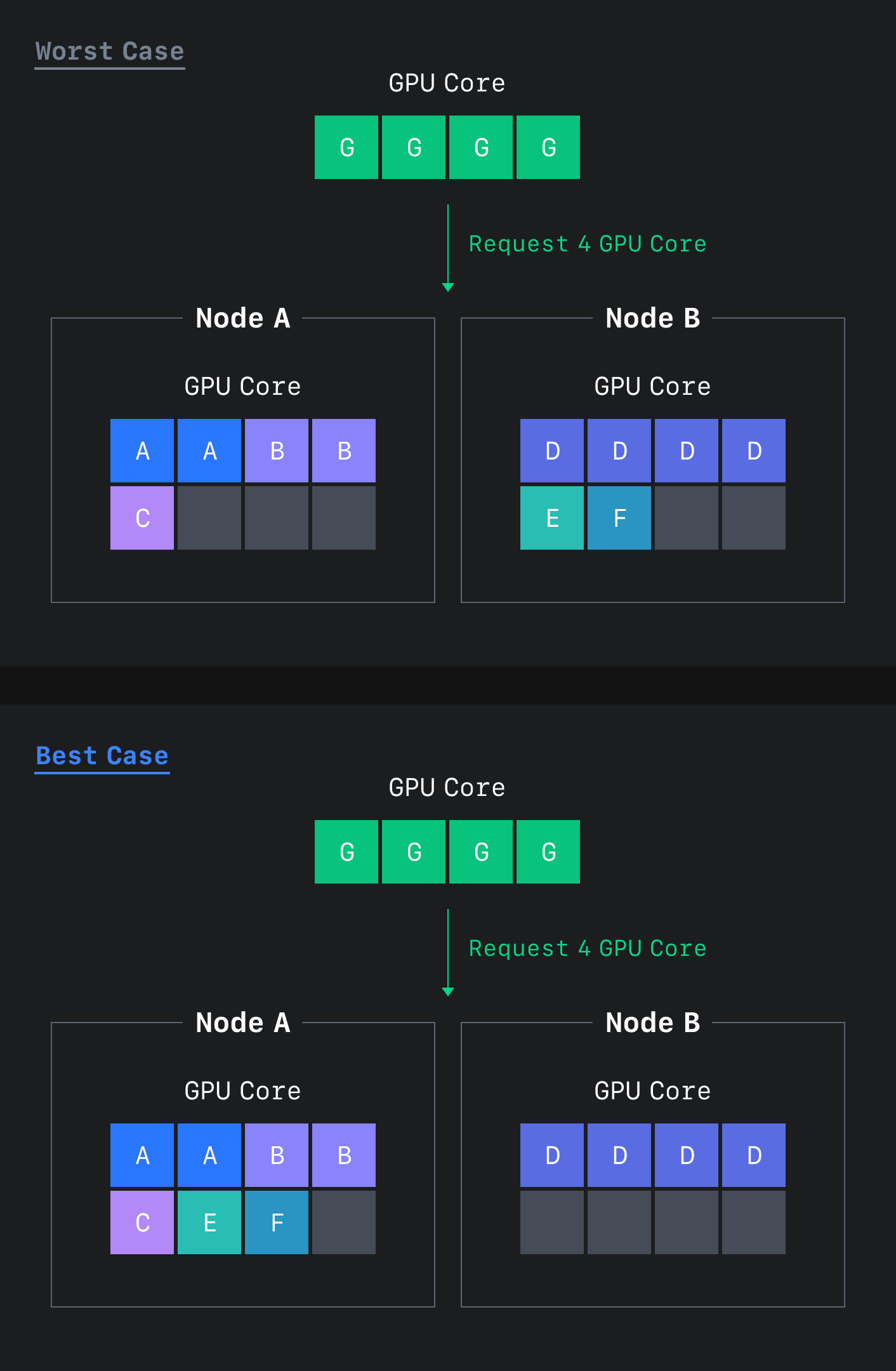
또한 관리 측면에서 프로젝트별로 사용 가능한 컴퓨팅 리소스를 할당하고 관리하기 위해서 미리 정의한 컴퓨팅 타입(A100, V100과 같은 GPU 종류와 몇 개의 GPU를 사용할 것인지를 미리 지정)을 기반으로 애플리케이션 리소스를 할당하고 회수할 수 있는 관리 기능이 필요합니다. 하지만 쿠버네티스는 컴퓨팅 리소스를 클러스터 단위로만 관리하기 때문에 프로젝트별 멀티 테넌트(multi-tenent)를 제공할 수 없다는 문제도 있었습니다.
효율적인 GPU 리소스 스케줄링 정책 적용
GPU 리소스 단편화는 다양한 개수의 GPU 코어를 사용하는 케이스에서 자주 발생하는 현상으로, 앞서 설명한 것처럼 할당 가능한 최대 리소스가 작고 최소 단위가 1코어 단위이기 때문에 발생하는 문제입니다. 이 문제를 해결하기 위해 빈 패킹(bin-packing) 이라는 스케줄링 정책을 시도했습니다. 빈 패킹은 GPU 리소스를 제공할 때 버킷에 차곡차곡 쌓는 것처럼 A 노드에 더 이상 리소스를 할당할 수 없을 때까지 스케줄링한 뒤 다음 버킷인 B 노드에 다시 차곡차곡 쌓아나가는 방식입니다.
빈 패킹 방식을 적용할 때 가장 중요한 두 가지를 꼽으면 다음과 같습니다.
- 단순히 GPU 리소스를 사용하는 애플리케이션을 순서대로 차곡차곡 쌓는 것이 아니라 최대한 같은 코어 수를 사용하는 애플리케이션끼리 버킷을 나눠 쌓습니다.
- 같은 코어에 배치하기 어려울 때에는 최대한 작은 코어를 사용하는 버킷에 스케줄링합니다.
이는 수시로 배포되고 밀려나는 상황에서도 최대한 배포 가능한 리소스를 확보하면서, GPU 8 코어를 사용하는 모델과 같이 많은 코어를 사용하는 모델 애플리케이션을 스케줄링할 수 있는 노드를 확보하기 위해서 꼭 필요한 정책입니다. 아래 그림 2는 위와 같은 알고리즘으로 스케줄링한 모습을 나타냅니다.
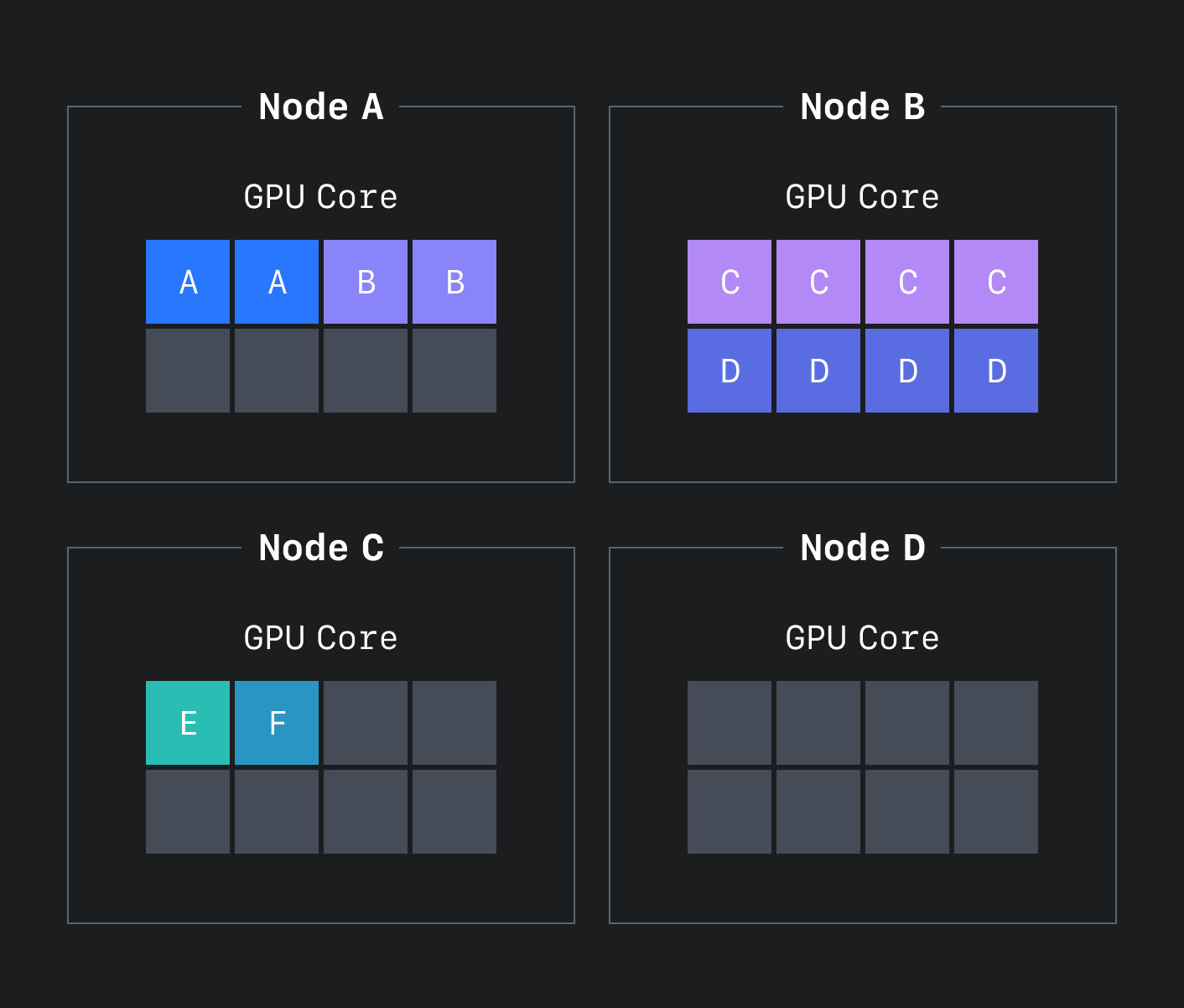
CLOps는 이와 같은 빈 패킹 방식을 적용해서 GPU 리소스의 단편화를 줄이고 조금 더 효율적으로 스케줄링할 수 있었습니다. 하지만 이 방식은 그림 3과 같이 안정적인 배포를 위해 모델 애플리케이션의 복제본(replica)이 필요한 상황에서 원본과 복제본을 같은 노드에 배치하는 바람에 고가용성(high availability, HA)을 유지할 수 없다는 문제가 있었습니다.
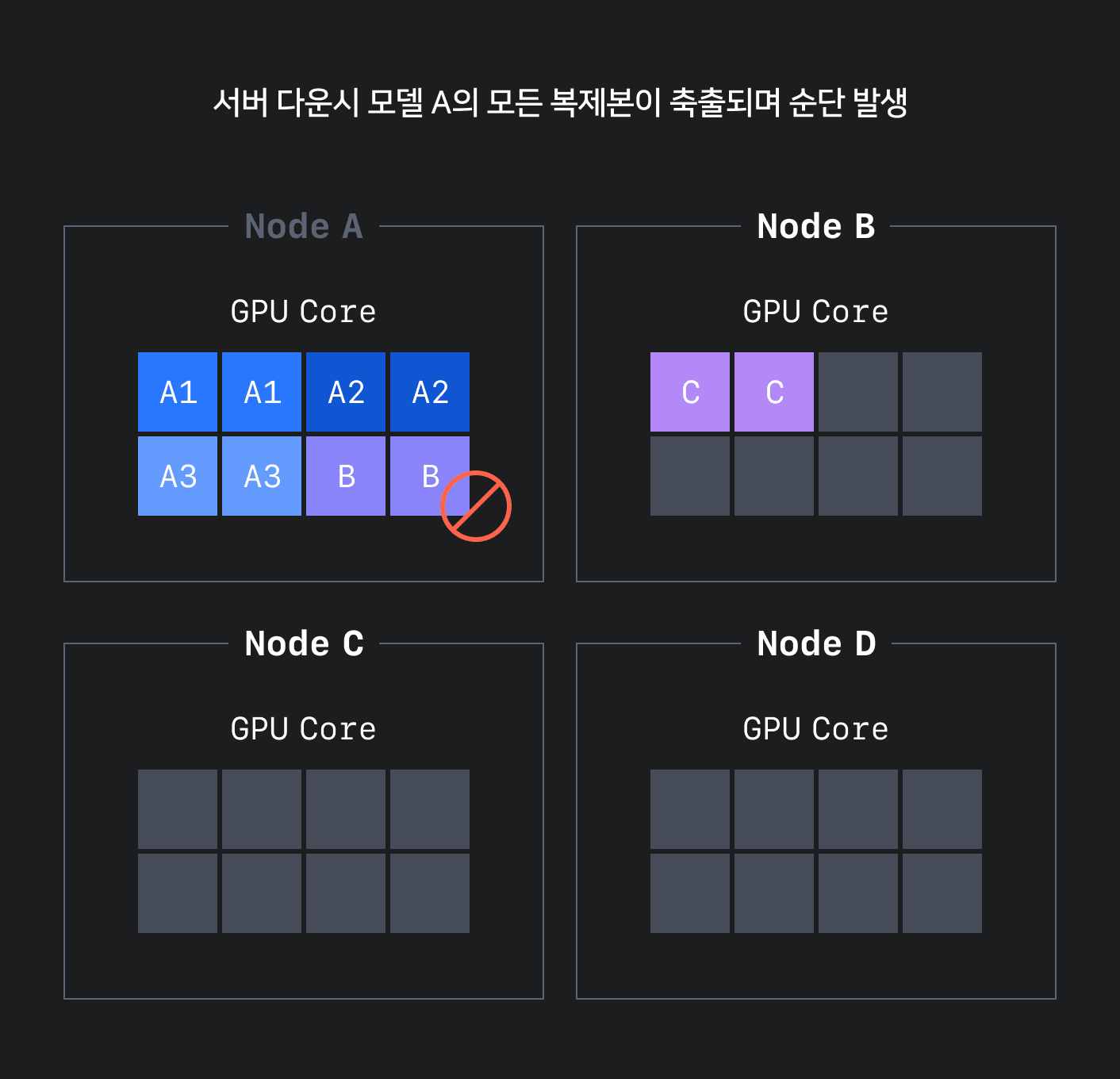
이를 해결하기 위해 분산 빈 패킹(distributed bin-packing) 방식을 적용했습니다. 분산 빈 패킹 방식은 고가용성을 확보하기 위해 기존 빈 패킹 방식에 최소 분산 수를 보장하는 로직을 추가해 적어도 최소 분산 수만큼은 분산해서 빈 패킹을 쌓는 방식입니다. 이를 통해 아래 그림 4와 같이 고가용성을 유지하면서 단편화를 줄일 수 있는 정책을 수립했습니다.
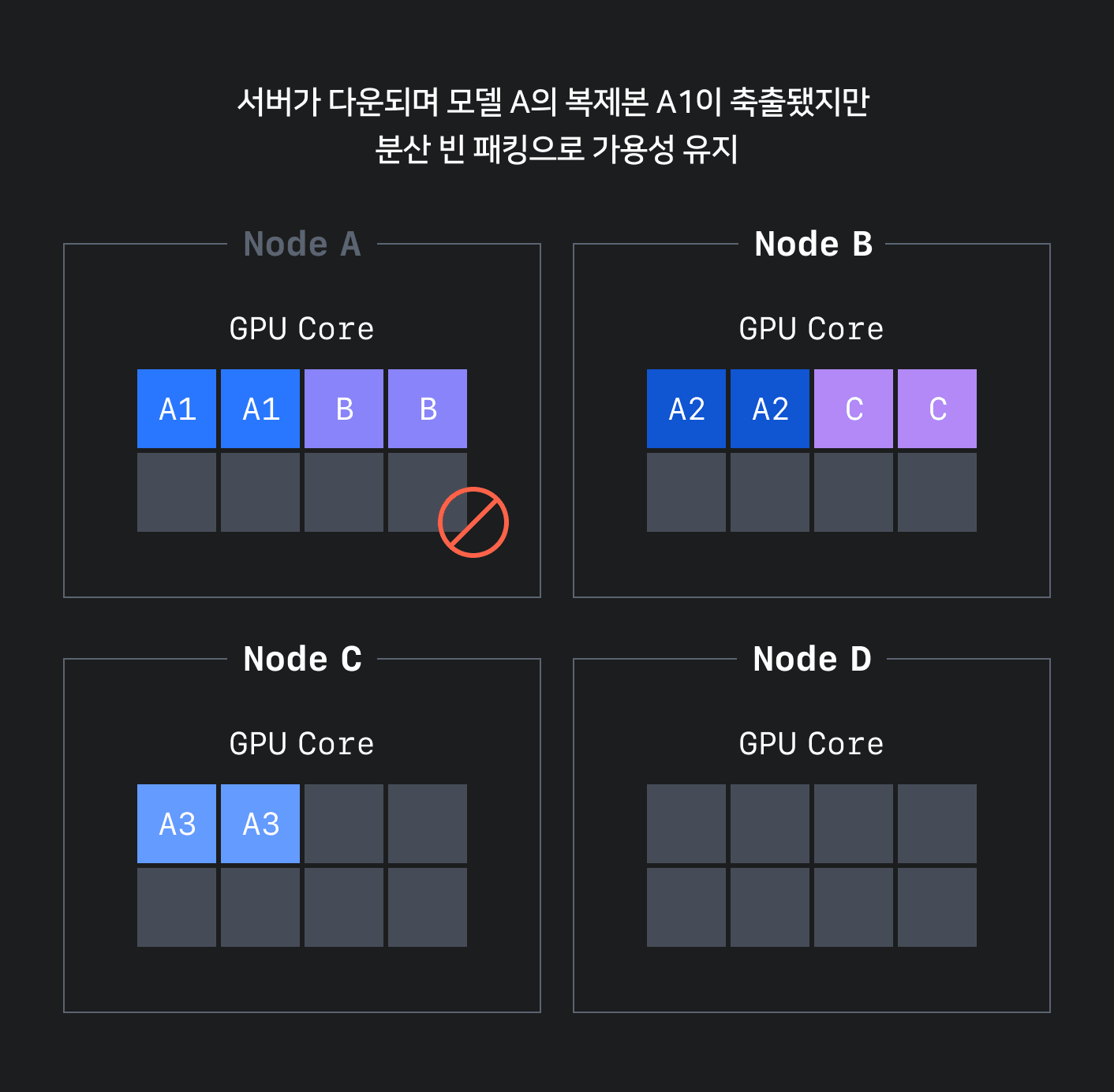
효율적으로 스케줄링하기 위한 커스텀 스케줄러와 오토라벨러 적용
지금까지 쿠버네티스에서 발생할 수 있는 GPU 리소스 관리의 문제와 이를 개선하기 위한 스케줄링 정책에 대해서 설명했습니다. 그렇다면 이를 실제로 어떻게 적용할 수 있을까요? CLOps에서는 이를 적용하기 위해 Scheduler와 Feature Autolabeler를 설계했습니다.
Scheduler - Scheduling Framework로 커스터마이징한 스케줄링 로직 적용
CLOps는 GPU 리소스 단편화 문제를 개선하고 멀티 테넌트를 제공하기 위해 Machine, AvailableMachine CRD(custom resource definition)와 Scheduling Framework를 이용했습니다. 아래 그림 5는 CLOps의 Machine과 AvailableMachine CRD의 관계를 나타냅니다.
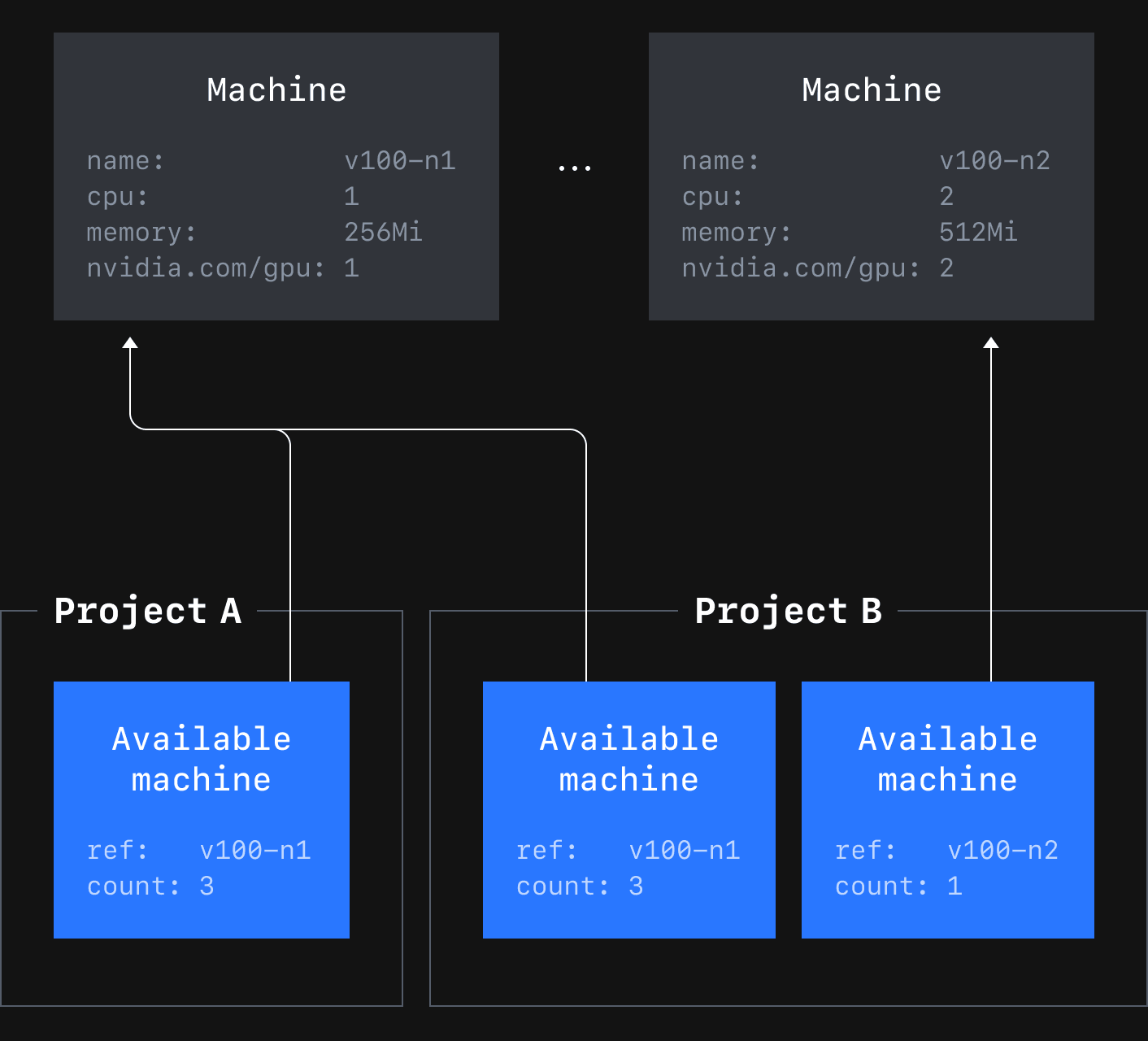
Machine은 미리 정의된 컴퓨팅 리소스를 담고 있습니다. 이를 참조하는 AvailableMahine은 프로젝트별로 어떤 Machine이 리소스를 얼마나 사용할 수 있으며, 현재 얼마나 사용하고 있는지를 담고 있습니다.
Scheduling Framework는 쿠버네티스에서 기본적으로 제공하는 스케줄링 정책 외에 커스터마이징한 스케줄링 로직을 구현해서 추가할 수 있도록 쿠버네티스 1.18 버전부터 지원하고 있는 프레임워크입니다. Scheduling Framework에서는 크게 다음과 같은 단계에서 커스터마이징한 로직을 추가할 수 있도록 지원하고 있습니다.
- 파드(Pod)가 스케줄링 대상인지 걸러내는 필터(filter) 단계
- 어떤 노드에 스케줄링할지 결정하는 점수화(score) 단계
- 가장 점수가 높은 노드에 파드를 스케줄링해 주는 예약(reserve) 단계
- 노드와 파드에 배포하는 바인드(bind) 단계
아래 그림 6은 Scheduler 컴포넌트가 모델 애플리케이션을 스케줄링하는 과정을 표현한 그림입니다.
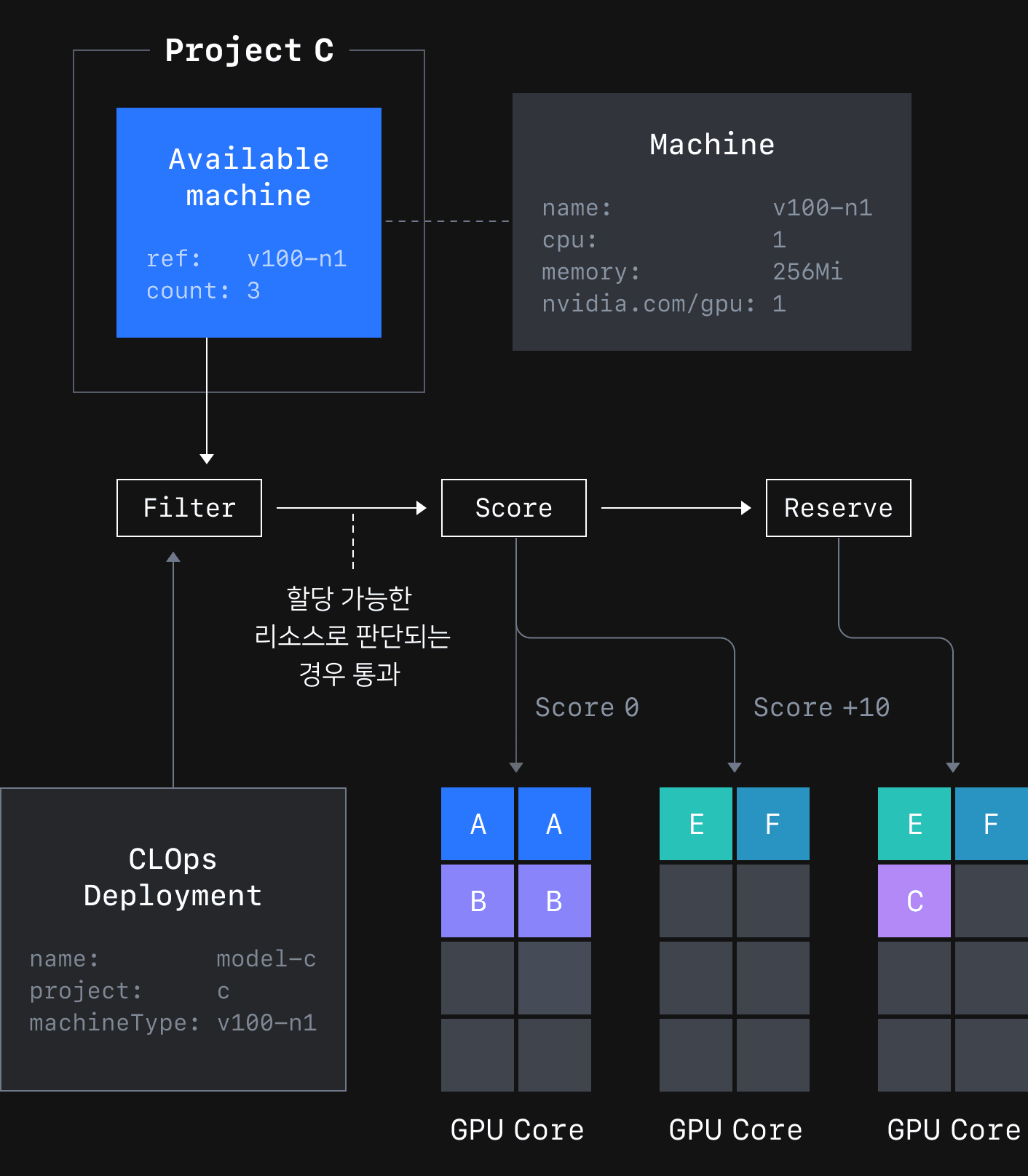
Scheduler 컴포넌트는 필터 단계에서 모델 애플리케이션이 어떤 Machine을 사용할 것인지 확인하고 AvailableMachine을 통해 프로젝트에 사용 가능한 리소스가 있는지 확인합니다. 사용 가능한 리소스가 있을 경우 점수화 단계에서 같은 Machine을 사용하는 모델 애플리케이션의 유무와 복제본의 개수와 같은 요소를 파악해 모든 노드의 점수를 산정합니다. 마지막으로 예약 단계에서 AvailableMachine의 상태 정보에 사용 정보를 업데이트합니다.
Feature Autolabeler - 클러스터 노드 라벨링 자동화
그렇다면 Scheduler에 따라 바인드되는 노드는 어떻게 구분할까요? 쿠버네티스는 애플리케이션을 배포해야 할 노드를 선택하기 위한 방법으로 노드 라벨을 이용합니다. 하지만 클러스터의 크기가 수백 대가 넘어가면 라벨을 세분화해서 관리하는 것이 어려워지고 상태에 따라 가변적으로 라벨을 달기 힘들어지면서, 결국 리소스 상황에 따라서 유연하게 사용 용도를 변경하고자 할 때 허들이 되곤 합니다.
이와 같은 문제를 해결하기 위해 아래 그림 7과 같이 노드의 생성과 변경, 삭제에 따라 이벤트를 처리하는 Feature Autolabeler라는 컴포넌트를 설계했습니다.
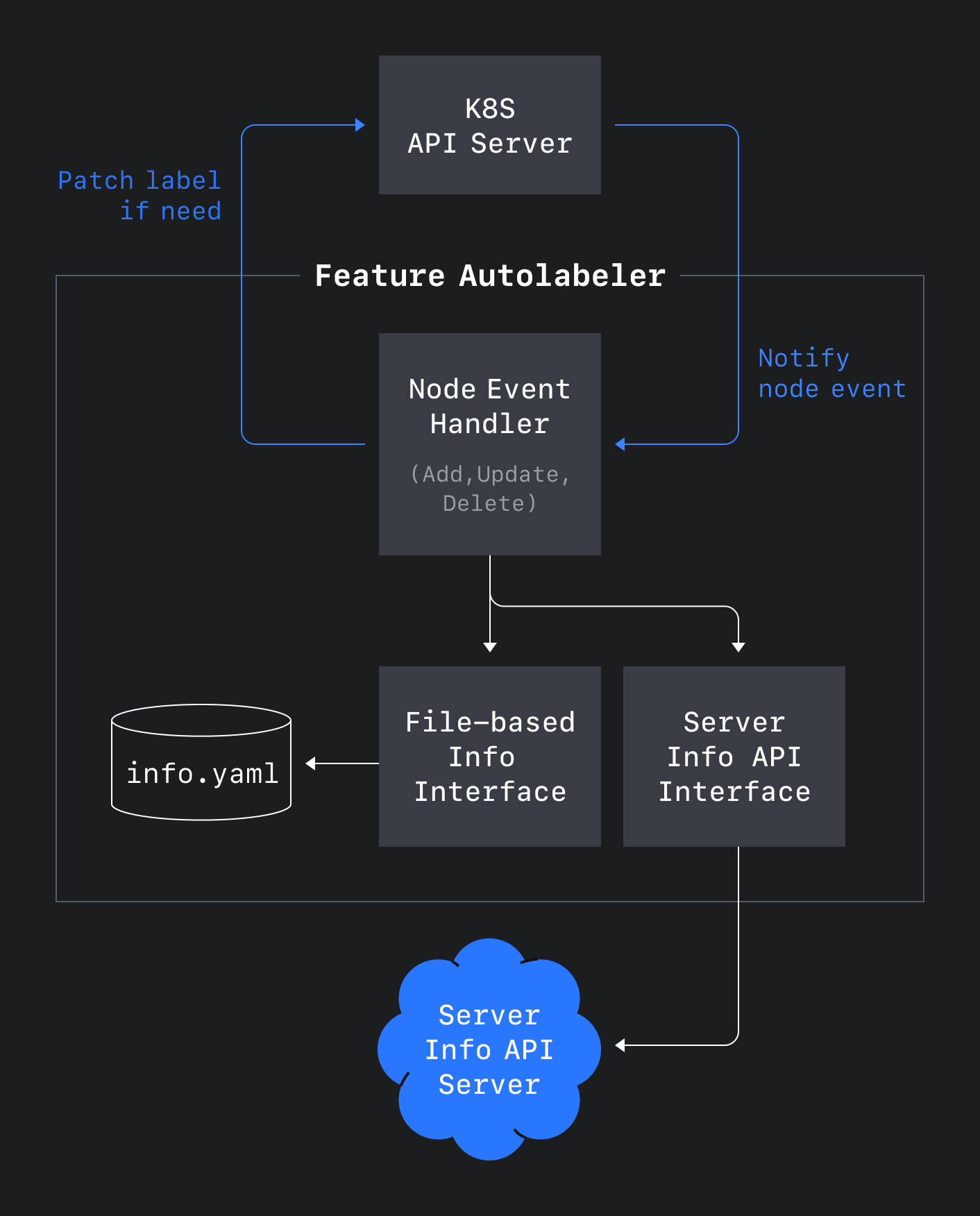
이 컴포넌트를 이용해 노드 조인이나 제외 혹은 스케일업에 따른 변경이 발생해도 사내 서버 정보 API 또는 파일 정보를 기반으로 라벨링이 되도록 자동화할 수 있었습니다. 자동화한 덕분에 사용 가능한 노드를 세분화해 라벨링할 수 있게 되면서 Machine 리소스를 다양하게 정의하고 제공할 수 있었으며, 이를 통해 컴퓨팅 리소스를 효율적으로 관리할 수 있었습니다.
오토스케일링(autoscaling) 도입 배경
CLOps에서 관리하는 모델 애플리케이션의 경우 대부분 특정 시간대에만 활발하게 요청이 발생하는 특성이 있습니다. 이는 대부분의 서비스에서도 발견할 수 있는 특성으로 해당 시간대의 많은 요청을 처리하기 위해서는 애플리케이션이 많은 리소스를 할당받아 사용해야 합니다. 그런데 이때 요청이 많이 발생하는 시간대가 아닌 경우에도 동일한 리소스를 할당받아 사용하면 낭비가 될 수 있습니다. 특히 CPU나 메모리와는 다르게 비싼 GPU 장비를 사용하는 모델 애플리케이션의 경우 더 큰 낭비가 될 수 있습니다. 또한 어떤 경우에는 급작스럽게 요청이 증가하면서 기존 리소스로는 모든 요청을 처리하기 어려운 상황이 발생할 수도 있습니다. 이때 오토스케일링이 없다면 안정적으로 서비스를 제공하기 위해서 사용자가 직접 애플리케이션을 모니터링하면서 애플리케이션의 처리 능력에 따라 추가 리소스를 할당해야 하는 불편함이 있습니다.
이런 문제를 해결하기 위해 많은 플랫폼에서 오토스케일링 서비스를 제공합니다. 오토스케일링이란 관측 조건에 따라 리소스를 자동으로 스케일 업/다운(scale up/down)하는 것을 말합니다. 컴퓨팅 리소스의 경우 아래 그림 8과 같이 서비스에 할당된 리소스의 크기를 변경하는 것은 수직 스케일링(vertical scaling), 동일한 리소스를 가진 서비스를 생성하거나 삭제하는 것은 수평 스케일링(horizontal scaling)이라고 부릅니다.

쿠버네티스에서는 VPA(Vertical Pod AutoScaler)를 통해 수직, HPA(Horizontal Pod AutoScaler)를 통해 수평 오토스케일링을 지원합니다. VPA는 파드의 리소스를, HPA는 디플로이먼트(deployment)와 같은 리소스의 복제본 수(replicas)를 정의된 조건에 따라 조절해서 스케일링을 수행합니다.
CLOps에서는 HPA를 이용해 오토스케일링을 제공하려고 했으나 다음과 같은 문제가 있었습니다. 먼저 HPA에서 지원하는 메트릭(metric)이 CPU와 메모리로 한정돼 있다는 점입니다. 부적절한 메트릭에 기반해 오토스케일링을 설정하면 자원이 필요하지 않은 순간에 자원을 더 할당받아 낭비가 발생할 수 있습니다. 이때 커스텀 메트릭 서버를 개발해 추가 메트릭을 제공할 수 있으나 직접 개발해야 한다는 불편함이 있습니다. 두 번째로 오직 하나의 커스텀 메트릭 서버만 구동할 수 있다는 점입니다. 필요에 따라 여러 메트릭 서버를 개발하더라도 실제로는 하나만 구동할 수 있어서, 여러 애플리케이션의 다양한 메트릭 요구를 동시에 수용할 수 없다는 문제가 있습니다. 마지막으로 복제본 수를 0으로 만드는 제로 스케일링(zero scaling)을 지원하지 않는다는 점입니다. 제로 스케일링은 모든 리소스를 반납하게 만드는 것으로, 만약 애플리케이션의 시작 시간이 길지 않다면 애플리케이션으로 들어오는 요청이 없을 때 제로 스케일링을 통해 리소스를 절약할 수 있습니다.
오픈 소스를 활용해 유연하게 자원을 활용할 수 있는 오토스케일링 제공
CLOps에서는 아래 그림 9와 같이 HPA의 문제를 해결한 오픈소스인 KEDA를 이용해 오토스케일링 서비스를 제공하기로 결정했습니다.
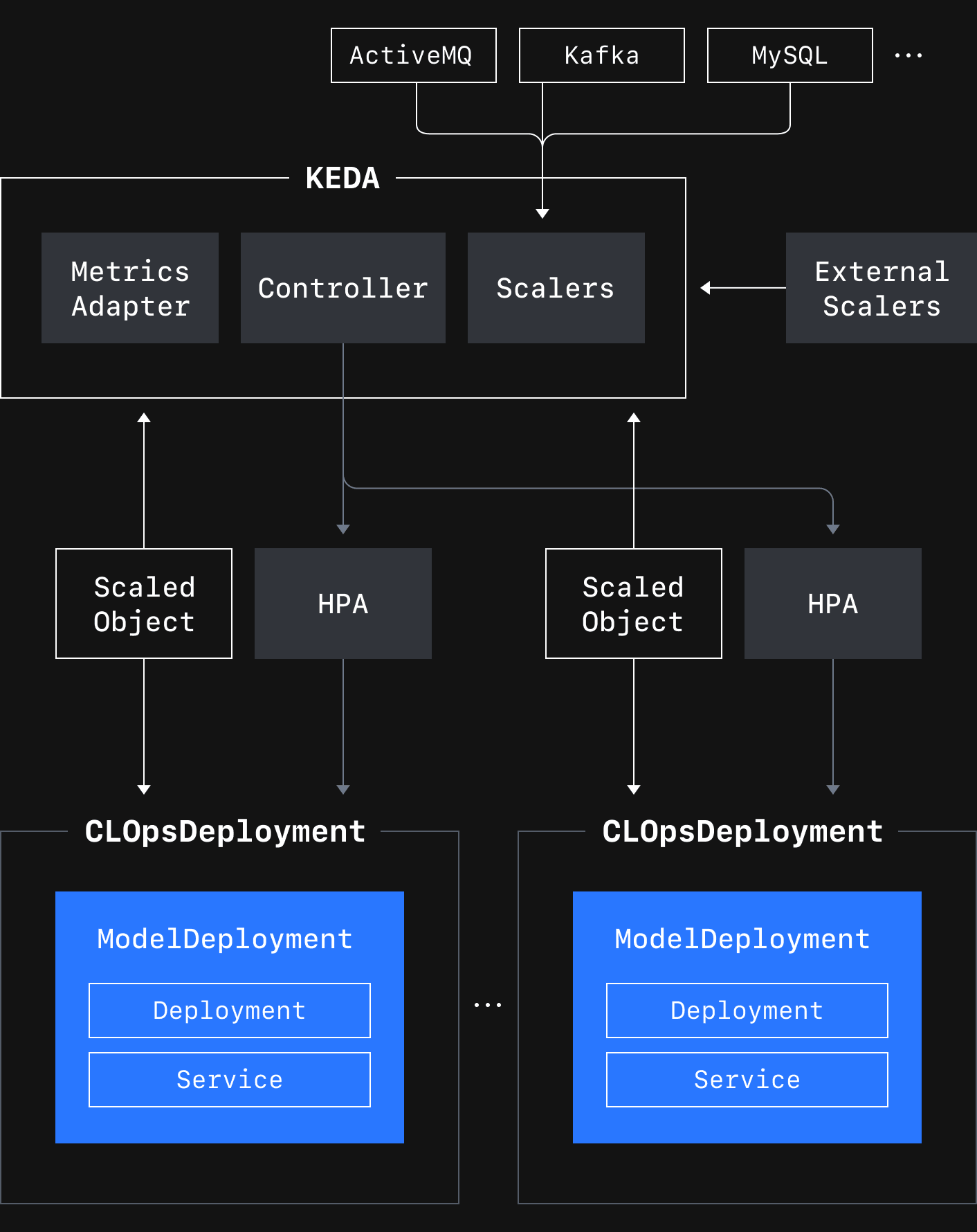
KEDA는 Scalers를 통해 Kafka와 같은 외부 컴포넌트에서 메트릭을 가져와 Metrics Adapter를 통해 HPA로 전달합니다. Controller는 복제본의 수를 0에서 1 또는 그 반대로 변경하는 제로 스케일링을 수행하거나 오토스케일링 대상과 조건을 정의하는 ScaledObject CR(custom resource)을 조정(reconcile)하는 로직을 수행합니다. 이를 기반으로 사용자가 CLOpsDeployment에 오토스케일링 스펙을 정의하면 CLOps 오퍼레이터가 해당 스펙에 맞는 ScaledObject를 생성하여 KEDA가 오토스케일링을 수행할 수 있도록 합니다.
CLOps에서 KEDA를 선택한 이유는 첫 번째로 CLOpsDeployment CRD에 대해 별도의 수정 없이 오토스케일링을 지원할 수 있다는 점입니다. KEDA가 사용하는 HPA는 scale 서브리소스가 구현된 모든 CRD에 대해 스케일링이 가능하기 때문입니다. 무엇보다도 사용자 애플리케이션을 수정할 필요가 없다는 게 큰 장점입니다. 두 번째로 다양한 메트릭을 지원한다는 점입니다. KEDA 2.8 버전 기준으로 56개의 Scaler를 지원해 애플리케이션의 다양한 메트릭 요구를 수용할 수 있고, 필요한 이벤트 소스에 대한 Scaler가 없는 경우 별도로 External Scaler를 개발해 해결할 수 있습니다. 세 번째로 다양한 Scaler가 직접 이벤트 소스에서 데이터를 가져와 HPA에 전달하는 방식으로 기존 HPA에서 하나의 커스텀 메트릭 서버만 구동할 수 있는 문제를 해결한 점입니다. 마지막으로 제로 스케일링을 지원한다는 점입니다. HPA가 하나 이상의 복제본 수를 조절한다면, KEDA는 복제본의 수가 하나인 상황에서 특정 시간 동안 이벤트가 발생하지 않는 경우 복제본의 수를 0으로 만듭니다. 반대로 이벤트가 발생하면 즉시 복제본의 수를 1로 변경해 HPA를 통해 복제본의 수가 조절되도록 합니다.
모델 애플리케이션의 요청 특징에 따른 프리셋 정의 및 제공
CLOps에서는 사용자가 오토스케일링을 쉽게 설정할 수 있도록 사전에 정의한 프리셋들을 제공하고 있으며, 그중 요청 수에 기반한 프리셋을 사용자에게 추천하고 있습니다. 일반적인 HTTP 서버의 경우 요청마다 처리 시간이 달라 HTTP 처리량에 기반해 스케일링하는 것은 적절하지 않습니다. 하지만 모델 애플리케이션 경우 요청을 처리할 때 사전에 학습된 모델에 기반해 동일한 연산을 수행합니다. 따라서 요청마다 처리 시간에 대한 변화 폭이 적어 복잡한 메트릭을 사용할 필요 없이 단순히 HTTP 처리량에 기반한 스케일링이 좋은 성능을 보이고 있습니다.
모델 배포와 운영은 어떻게 이루어질까요?
이번 글에서는 CLOps에서 리소스 관리와 관련해 발생했던 여러 문제와 이를 어떻게 해결해 나갔는지 소개했습니다. 리소스 관리는 모든 플랫폼에서 필수적인 부분으로 애플리케이션의 성능 및 비용과 관련된 중요한 부분입니다. CLOps에서는 이를 위해 커스텀 스케줄러를 개발하고 오픈 소스를 활용해 오토스케일링을 제공했습니다. 이어지는 글에서는 모델을 어떻게 저장하고 클러스터에 배포하고 있는지 공유하겠습니다.



