

지난 6월 말 출시한 CLOVA MD 상품추천 솔루션은 네이버 스마트스토어 판매자가 자신의 스토어에 상품추천을 추가할 수 있는 솔루션입니다. CLOVA MD에서는 다음과 같은 세 가지 방식을 제공하고 있습니다.
- CLOVA 고객 맞춤 상품추천: 스토어에 방문하는 고객의 취향과 관심사에 맞는 상품을 추천합니다.
- CLOVA 함께 구매할 상품추천: 현재 보고 있는 상품과 함께 구매할 확률이 높은 상품을 추천합니다.
- CLOVA 비슷한 상품추천: 현재 보고 있는 상품과 유사한 상품을 추천합니다.
CLOVA MD는 커머스 솔루션 마켓에서 솔루션을 구독한 스토어에 한해 상품추천을 제공하며 해당 스토어 상품들로만 추천 상품을 구성합니다(현재 베타 기간으로 무료로 제공하고 있습니다).
저는 올해 초 AI Product 팀에 합류해서 CLOVA MD 상품추천 솔루션 개발에 참여했는데요. 이번 글에서는 추천 데이터 서빙 관점에서 CLOVA MD 상품추천 솔루션을 어떻게 만들었는지 살펴보면서 AI Product 팀에서는 어떤 일을 하는지, CLOps와 같은 사내 플랫폼을 어떻게 활용하고 있는지 소개하겠습니다.
전체 구조
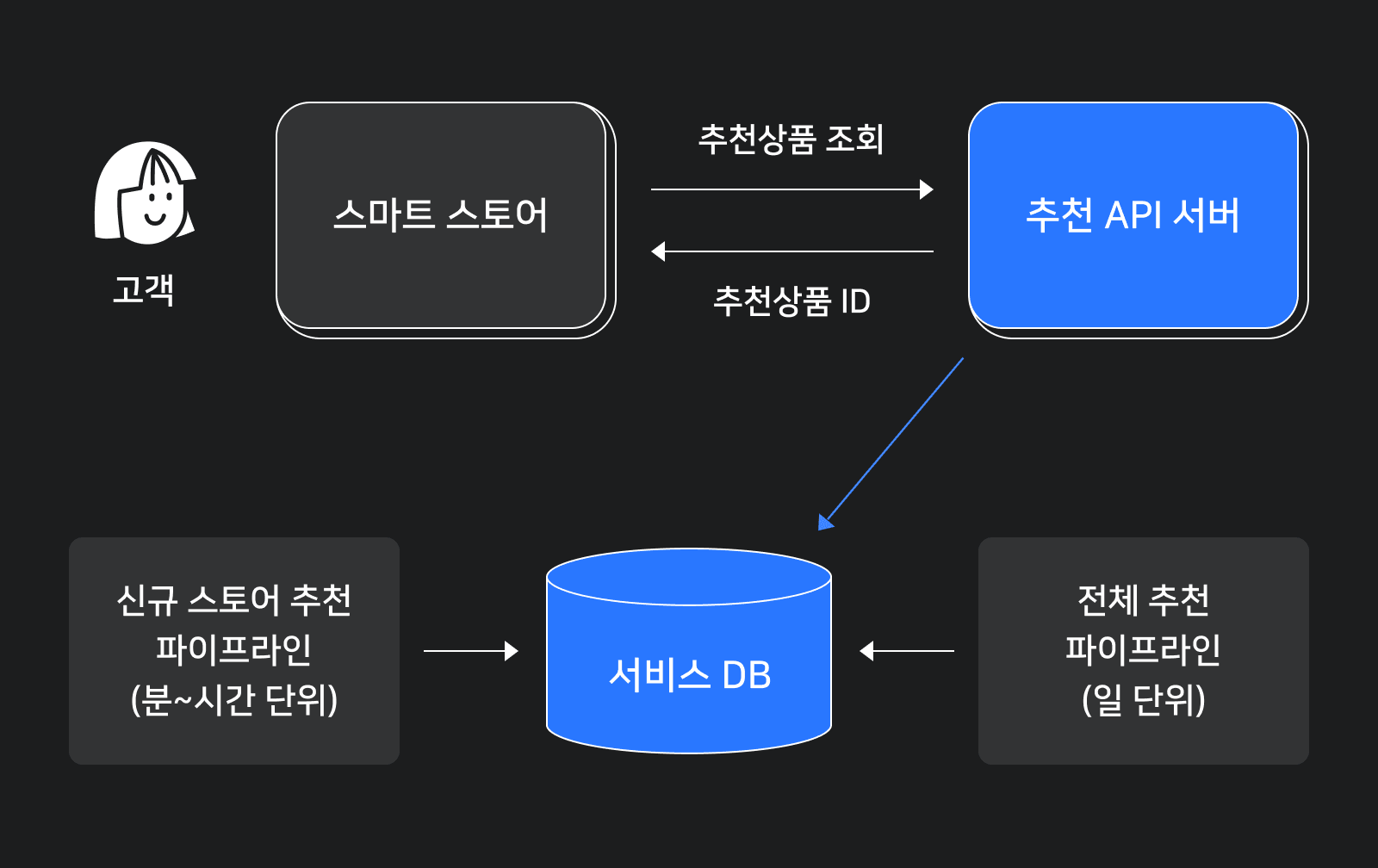
CLOVA MD의 추천은 입력으로 어떤 값이 들어올지 미리 알 수 있습니다(고객 또는 상품의 식별자). 또한 개설된 모든 스마트스토어에 추천을 제공하는 것이 아니라 솔루션을 구독한 스토어에만 추천을 제공하므로 규모가 매우 크지는 않습니다. 따라서 모든 예상 입력에 대해 미리 추천 결과를 생성해 두는 것이 가능하기에 오프라인 배치로 미리 만든 추천 데이터를 서비스 DB에 올려두고 서비스할 때는 단순 조회만으로 추천 결과를 반환하는 방식을 사용합니다.
판매자는 상품을 삭제하거나 정보를 변경할 수 있고, 추천 모델은 최신 데이터를 반영해 계속 업데이트됩니다. 이를 반영하기 위해 일 단위 주기로 전체 구독 중인 스토어를 대상으로 추천 결과를 생성합니다. 하지만 추천 결과를 이와 같이 일 단위 주기로만 생성하면 신규 구독한 스토어는 추천 데이터가 생성되기까지 며칠을 기다려야 할 수도 있습니다. 따라서 신규 구독한 스토어를 대상으로 훨씬 짧은 주기(분~시간 단위)로 실행되는 배치 작업을 추가로 운영해 추천 결과를 빠르게 적용할 수 있도록 했습니다.
추천 결과는 추천 API 서버를 통해 스마트스토어에 제공합니다. 추천 API에서는 추천 상품의 식별자만을 제공하며, 스마트스토어에서 식별자로 최신 상품 정보를 조회해 필요한 방식에 맞춰 노출합니다.
추천 파이프라인
AI Product 팀 엔지니어는 모델링 팀의 모델러와 협업해서 서비스를 개발합니다. 모델 학습 및 추론 파이프라인은 프로젝트에 따라서 전체를 모델러가 만들고 관리하는 경우가 있고, 모델러가 작성한 모델 코드를 이용해서 AI Product 팀에서 개발하는 경우도 있습니다.
CLOVA MD 파이프라인은 모델러가 개발 및 관리하면서, 결과물 전달 형태와 방식은 AI Product 팀과 함께 정의하는 방식으로 운영하고 있습니다. 직접 파이프라인 개발을 담당하지 않더라도 파이프라인에 대해 전반적으로 파악하고 있어야 전체적인 시스템의 작동 방식을 이해할 수 있는데요. 이 글에서도 이해를 돕기 위해 추천 파이프라인을 전체적으로 한 번 살펴보겠습니다.
데이터 취득
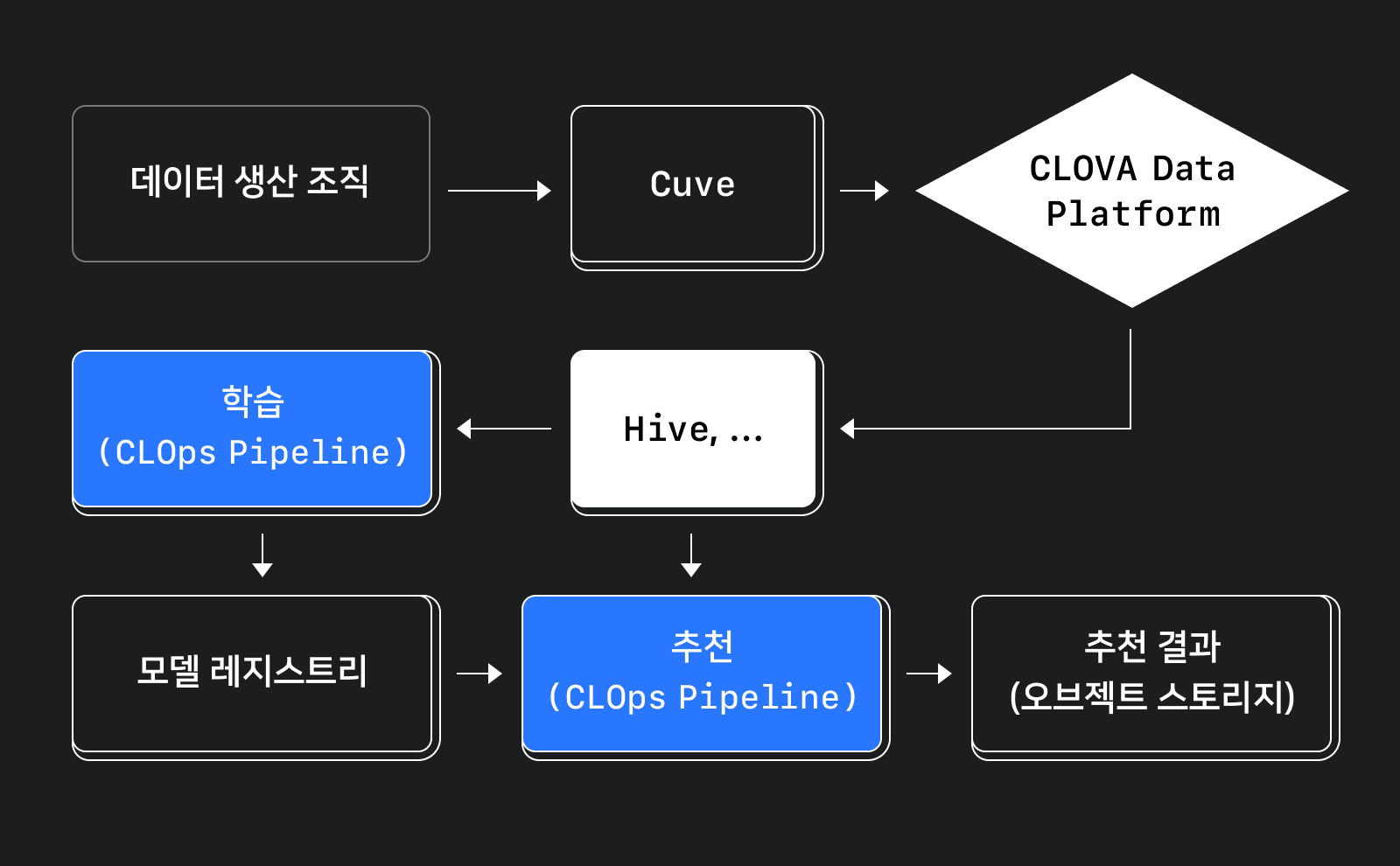
학습하고 추천하기 위해서는 가장 먼저 대상 상품과 관련 로그 등을 데이터 생산 조직에서 받아와야 합니다. 이때 일반적으로 가장 먼저 고려하는 방식은 사내 문서 저장 및 유통 시스템인 Cuve를 이용하는 방식입니다. 통일된 인터페이스로 접근할 수 있다는 장점이 있고, 전사 데이터 카탈로그와 연동돼 있어서 데이터를 사용할 때 거쳐야 하는 절차가 강제돼 좀 더 안전하게 데이터를 활용할 수 있습니다. Cuve에서 얻은 문서는 클로바 내부 데이터 플랫폼을 거쳐 Hive와 Kafka 등 좀 더 편리하게 사용할 수 있는 저장소에 쌓입니다.
CLOVA MD에서도 상품 정보와 사용자 클릭 로그 등을 Cuve에서 받아오고 있습니다. 데이터를 받아올 때는 데이터가 실시간으로 발행되는지 주기적으로 발행되는지 파악해야 하며, 전체 스냅샷이 제공되는지 변경분만 제공되는지 혹은 변경 내역까지 제공되는지도 꼭 고려해야 할 사항입니다.
학습
필요한 데이터를 확보했다면 머신 러닝 모델을 학습할 수 있습니다. 모델 학습은 클로바의 MLOps 플랫폼인 CLOps에서 제공하는 파이프라인에서 진행됩니다. CLOps 파이프라인으로 Argo Workflows, Kubeflow Pipelines와 같은 오픈 소스 워크플로 엔진을 손쉽게 구축할 수 있습니다. CLOps 인증 시스템과 통합돼 있어 편리하게 관리할 수 있고, CLOps 장비 풀을 활용할 수 있습니다.
학습 작업을 스케줄에 맞춰 주기적으로 실행하고 세부 작업의 DAG(Directed Acyclic Graph) 의존성을 고려해 병렬로 실행하는 등 파이프라인 기능을 사용해 모델 학습을 수행합니다. 학습 결과는 CLOps 모델 레지스트리에 저장해서 이후 추천 결과 생성 과정에서 사용합니다.
추천 결과 생성
모델 학습 결과로 나온 머신 러닝 모델을 사용해 추천 결과를 미리 생성하는 과정입니다. 학습과 마찬가지로 주기적인 작업 실행과 병렬 실행 등이 필요하므로 CLOps 파이프라인을 사용합니다. 추천 결과는 스토어별 추천 결과 파일로 생성되며 사내 오브젝트 스토리지에 업로드됩니다.
추천 데이터 서빙
추천 파이프라인에서 생성된 추천 결과는 최종적으로 고객에게 추천을 제공하기 위해서 온라인 서비스가 가능한 DB에 저장한 뒤 API로 서비스합니다.
DBMS
추천 결과를 저장하기 위한 DBMS로는 MongoDB를 사용합니다. 추천 데이터는 조인(join)이 필요하지 않은 비교적 단순한 키-값 쌍이므로 MongoDB에 저장하기에 적합하다고 판단했으며, 아울러 다음과 같은 점도 함께 고려했습니다.
- 팀 내 다른 프로젝트에서도 사용하고 있고, 사내 DBA의 지원을 받을 수 있습니다.
- 샤딩을 통한 수평 확장이 가능해서 추후 추천 결과 규모가 늘어나더라도 대응할 수 있습니다.
- 공식 Java 드라이버가 Reactive Streams를 지원하며 Spring Data MongoDB도 Reactive 드라이버를 지원합니다.
DB 설계
고객 맞춤 상품추천 DB
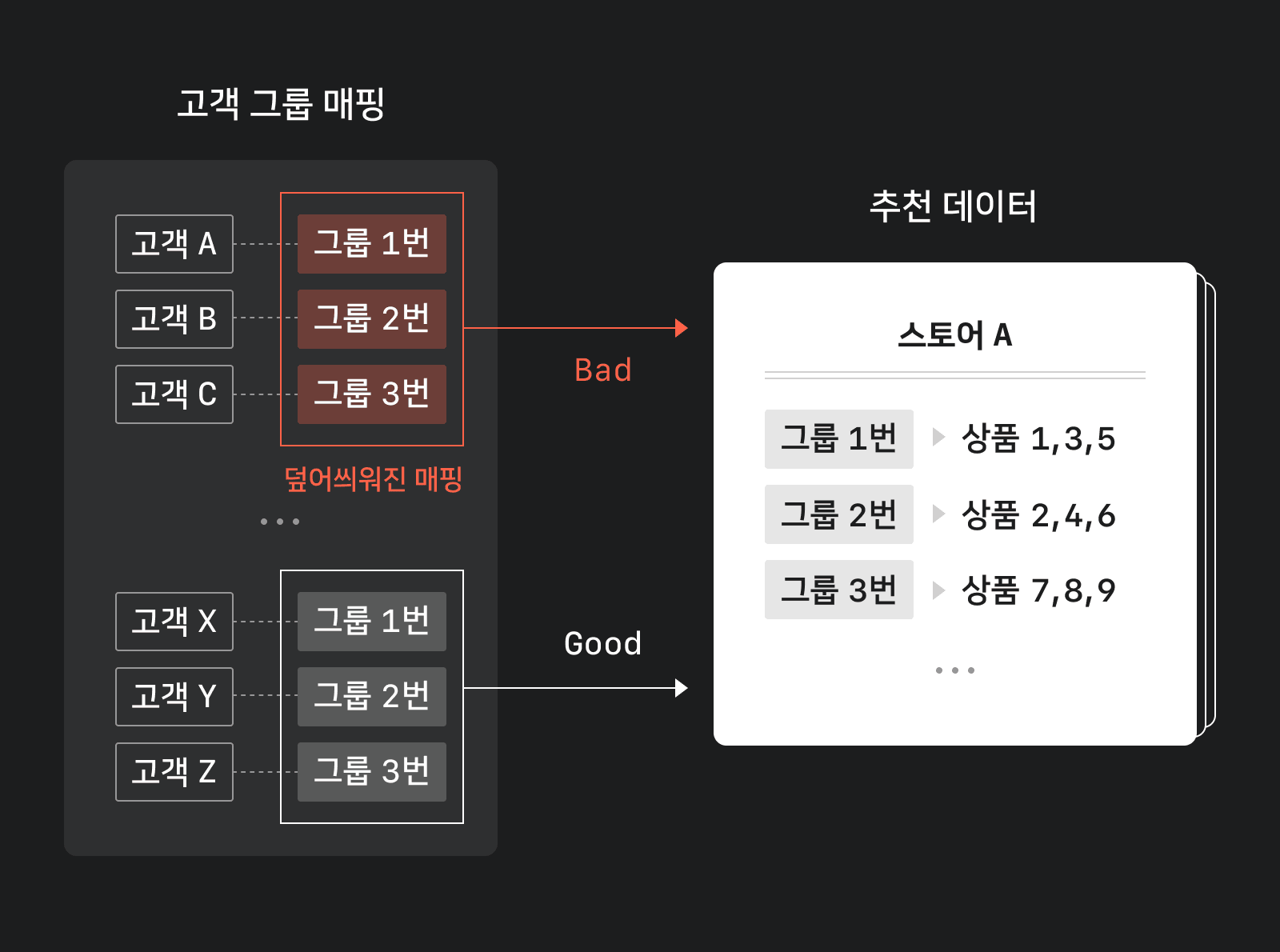
고객 맞춤 상품추천에서는 고객을 몇 개의 그룹으로 나눈 뒤 각 그룹마다 스토어별로 추천 상품을 정합니다. 고객 그룹은 스토어별로 다르지 않습니다. 모든 스토어가 공유합니다. 예를 들어 고객 A, B, C가 고객 그룹 1번이 됐다면 각 스토어마다 고객 그룹 1번에게 추천할 상품 목록을 정하는 방식입니다.
고객 그룹 매핑 데이터는 고객 식별자를 키로 하고 고객 그룹 번호를 값으로 합니다. 여기서 문제는 고객 그룹 매핑 데이터를 업데이트할 때인데요. 똑같은 고객 그룹 1번이라도 월요일에 생성한 고객 그룹 1번과 수요일에 생성한 고객 그룹 1번은 서로 다릅니다. 따라서 단순히 새로운 데이터로 기존 고객 그룹 매핑을 덮어쓴다면 스토어별 추천 상품이 새 고객 그룹에 맞게 업데이트되기 전까지는 엉뚱한 상품이 추천될 수 있습니다.
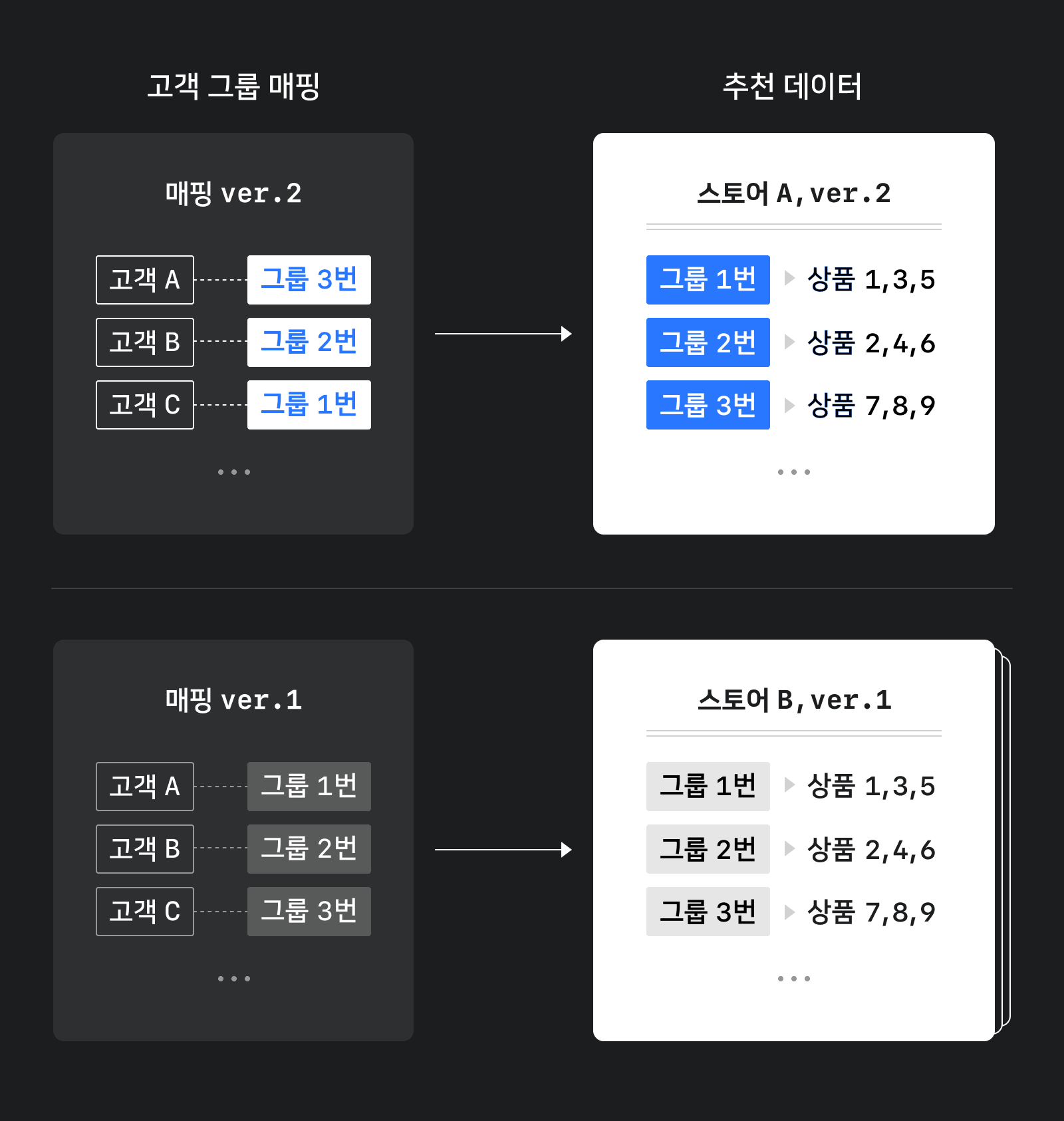
이를 해결하기 위해 고객 그룹 버전 개념을 도입했습니다. 고객 그룹 매핑마다 버전을 할당한 뒤 새로운 버전의 데이터를 기존 데이터에 덮어쓰지 않고 별도로 저장합니다. 그리고 스토어별 상품추천 데이터에는 고객 그룹 번호와 함께 참조하는 고객 그룹 버전을 기록합니다.
이렇게 하면 새 버전의 고객 그룹 매핑 데이터를 DB에 저장하는 동안에는 기존 고객 그룹 매핑이 그대로 유지되므로 추천에 영향이 없습니다. 고객 그룹 매핑 데이터 저장이 끝난 후 스토어별 상품추천 데이터를 새 고객 그룹에 맞춰 덮어쓰면 점진적으로 새로운 고객 그룹 매핑 데이터를 사용하도록 업데이트합니다.
함께 구매할 상품 추천과 비슷한 상품추천 DB
함께 구매할 상품추천과 비슷한 상품추천에서는 입력 상품에 대한 추천 상품 목록을 정합니다. 따라서 상품 식별자를 키로, 추천 상품 목록을 값으로 저장합니다. 추천을 업데이트할 때는 모든 상품의 추천이 한 번에 바뀌지 않아도 되므로 점진적으로 기존 값들을 덮어쓰는 방식으로 DB에 저장합니다.
추천 서버 구현
추천 서버는 Spring Boot 프레임워크 기반이고 Kotlin으로 작성했습니다. API 서버와 배치, 두 종류의 컴포넌트로 구성됩니다.
API 서버는 추천 결과 DB에서 추천 상품을 조회해 스마트스토어에 제공합니다. Spring WebFlux 기반이며, Spring Data MongoDB의 리액티브 API를 사용해서 MongoDB에 접근합니다. 리액티브 방식으로 코드를 작성하면 코드 흐름을 파악하기 어렵다는 문제를 해결하기 위해 Kotlin 코루틴을 사용해서 개발했습니다.
배치는 지속적으로 실행되면서 주기적으로 수행해야 하는 여러 가지 작업을 처리합니다. 가장 큰 역할은 새로 생성된 추천 결과를 서비스 DB에 반영하는 일입니다. 추천 결과가 저장되는 오브젝트 저장소를 주기적으로 폴링(polling)하면서 새로운 파일이 발견되면 로컬 디스크에 다운로드해 DB에 반영합니다. 처리를 완료하면 DB에 해당 파일이 처리 완료됐다고 표시해서 중복 처리되는 것을 방지합니다. API 서버와 코드를 공유하며 주기적으로 작업을 실행하기 위해 Spring 스케줄러를 사용했습니다.
판매자를 위한 관리 메뉴
판매자를 위해 스마트스토어의 판매자용 사이트인 스마트스토어센터에서 CLOVA MD 상품추천 솔루션을 관리할 수 있는 메뉴를 제공하고 있습니다. 이 메뉴는 AI Product 팀에서 담당해 프런트 엔드까지 개발했으며, 솔루션 구독 상태를 확인하거나 스토어에 어떤 추천 상품이 노출되고 있는지 미리 확인하는 기능 등을 제공합니다.
로그 수집 및 분석
추천을 얼마나 잘 제공하고 있는지 성능을 확인하고 개선하기 위해서는 로그를 수집하고 데이터를 분석해야 합니다. 이를 위해 전사 로그 수집 시스템과 클로바 자체 로그 수집 시스템을 이용해 사용자 행동 관련 로그를 수집하고 있습니다. 이렇게 수집한 로그를 분석해 지속적으로 확인해야 할 지표를 집계해서 Hive 또는 Druid에 저장한 뒤 Superset으로 대시보드를 만들어 시각화하고 있습니다.
마치며
CLOVA MD 상품추천 솔루션은 베타 오픈 후 지속적으로 구독자가 증가하며 점점 더 많은 스토어에서 사용하고 있습니다. 앞으로 기능 및 추천 성능을 개선해 베타 기간을 종료하고 정식으로 출시할 예정입니다.
AI Product 팀에서는 이 밖에도 네이버 선물샵 등 여러 커머스 영역에서 추천을 제공하고 있으며, 추천 외에도 AI 기술을 활용한 자동 고객 응대, 마케팅 메시지 발송, 수요 예측 등 다양한 커머스 관련 솔루션을 개발하고 있으니 많은 관심 부탁드립니다.



