
Introduction
The natural language processing (NLP) community was surprised to learn that zero/few-shot in-context learning ability also emerges in a large-scale language model such as GPT-3 (Brown et al., NeurIPS, 2020) despite no duplication between downstream task data and the pre-training corpus. Last year, we at the HyperCLOVA team introduced HyperCLOVA (Kim et al., EMNLP, 2021), a large-scale Korean AI platform based on GPT-3. We have since shared our research results and applied the capabilities of HyperCLOVA to various service products.
GPT-3 has garnered attention through its ability of in-context learning. In-context learning is done by feeding a few training examples and/or task descriptions with a new input to a large-scale language model (LM) for it to produce a target of this input, without requiring any parameter updates. In-context learning can further be categorized by the number of examples used. A few training examples are used in the in-context few-shot learning setting, whereas no training examples are used in a zero-shot setting.
There still remain many questions regarding in-context learning for language models despite the successful reports on their capabilities. For example, the relationship between the choice of a pre-training corpus and downstream in-context learning task accuracy is unknown. However, pre-training corpora are a significant factor for language model performance, and research on pre-training corpora is important from the perspective of conserving data collection costs. In this article, we will be looking into the results of our ablation study on how the performance of in-context learning changes depending on the corpus used.
Pre-training corpus
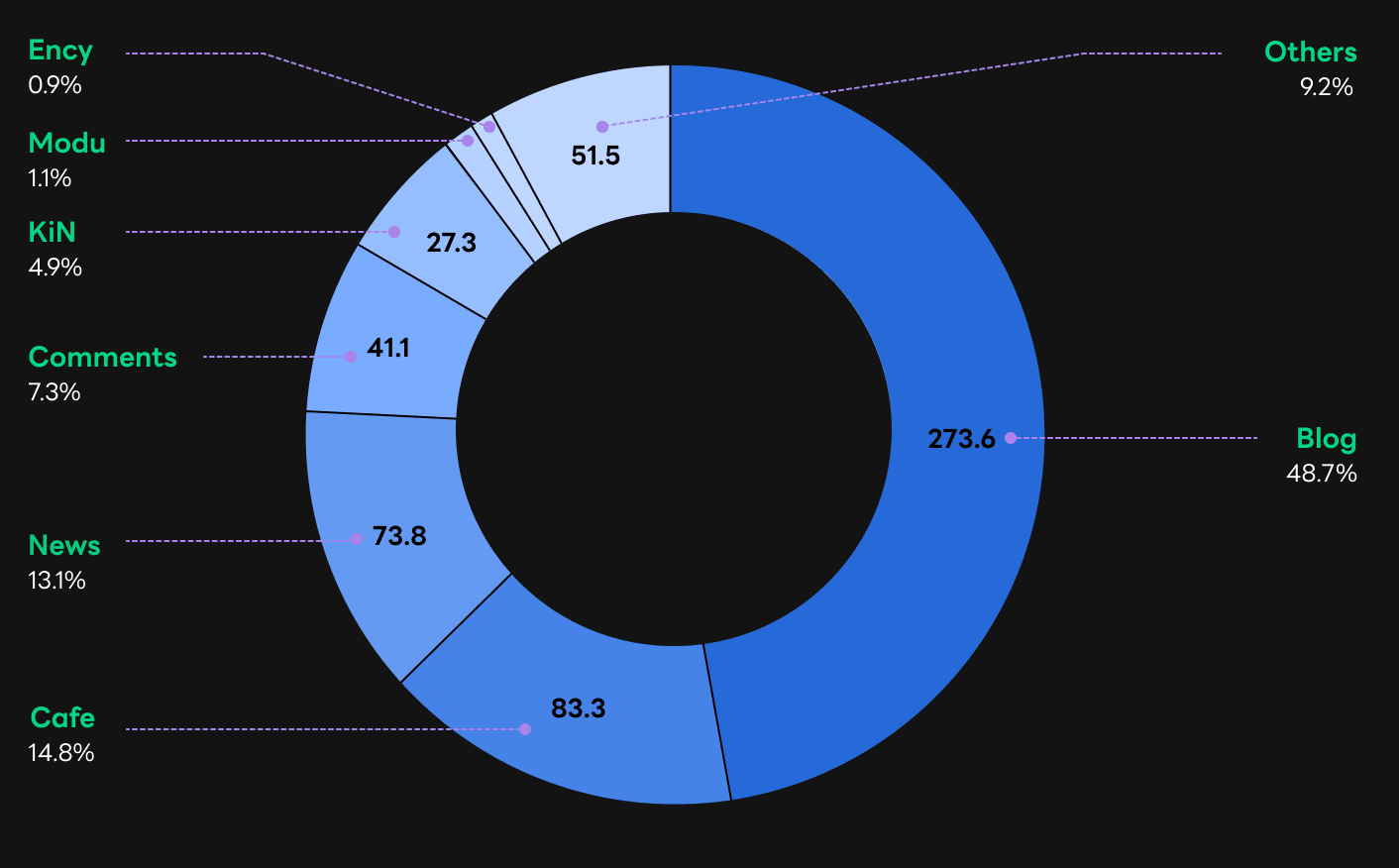
There are seven sub-corpora in the HyperCLOVA corpus: Blog, Cafe, News, Comments, KiN, Modu, and Ency. Blog, Cafe, and News are taken from blogs, community websites, and the online news articles hosted on NAVER, a Korean web portal service. Comments is the comment threads related to the three sub-corpora mentioned above. KiN comes from a Korean online community Q&A service similar to Quora. Ency is a collection of encyclopedic texts including the Korean section of Wikipedia. Modu consists of five public datasets constructed by the National Institute of Korean Language.
Unlike other corpus used in GPT-3 training, such as Common Crawl, the HyperCLOVA corpus consists of a well-separated sub-corpus with a balanced ratio. So, it is advantageous for analyzing differences by domain type of the sub-corpus.
We evaluate the in-context learning performance of each corpus-specific model on five Korean downstream tasks. The five tasks consist of binary sentiment classification, machine reading comprehension, Korean to English translation, English to Korean translation, and topic classification.
Discovery 1: In-context learning performance heavily depends on the corpus domain source
It is noticeable that in-context learning ability emerges differently depending on pre-training corpus sources. For example, the Blog model demonstrates in-context few-shot learning performance comparable to the ALL model, the model using the entire HyperCLOVA corpus. However, each of the Cafe and News models hardly show any in-context few-shot learning ability. At first glance, the difference between Blog (blog) and Cafe (online community) corpus does not seem to be large. However, it is surprising how much different the abilities of Blog and Cafe actually are.
In addition, as shown in the below figures, the size of pre-training corpus does not necessarily predict the emergence of in-context learning. Also, perplexity, evaluated with the validation set of seven sub-corpus, and in-context learning are not always correlated: e.g., low perplexity does not always imply high in-context learning performance. For example, Cafe's corpus size and validation perplexity are second best, but the performance of Cafe is lower than Modu.
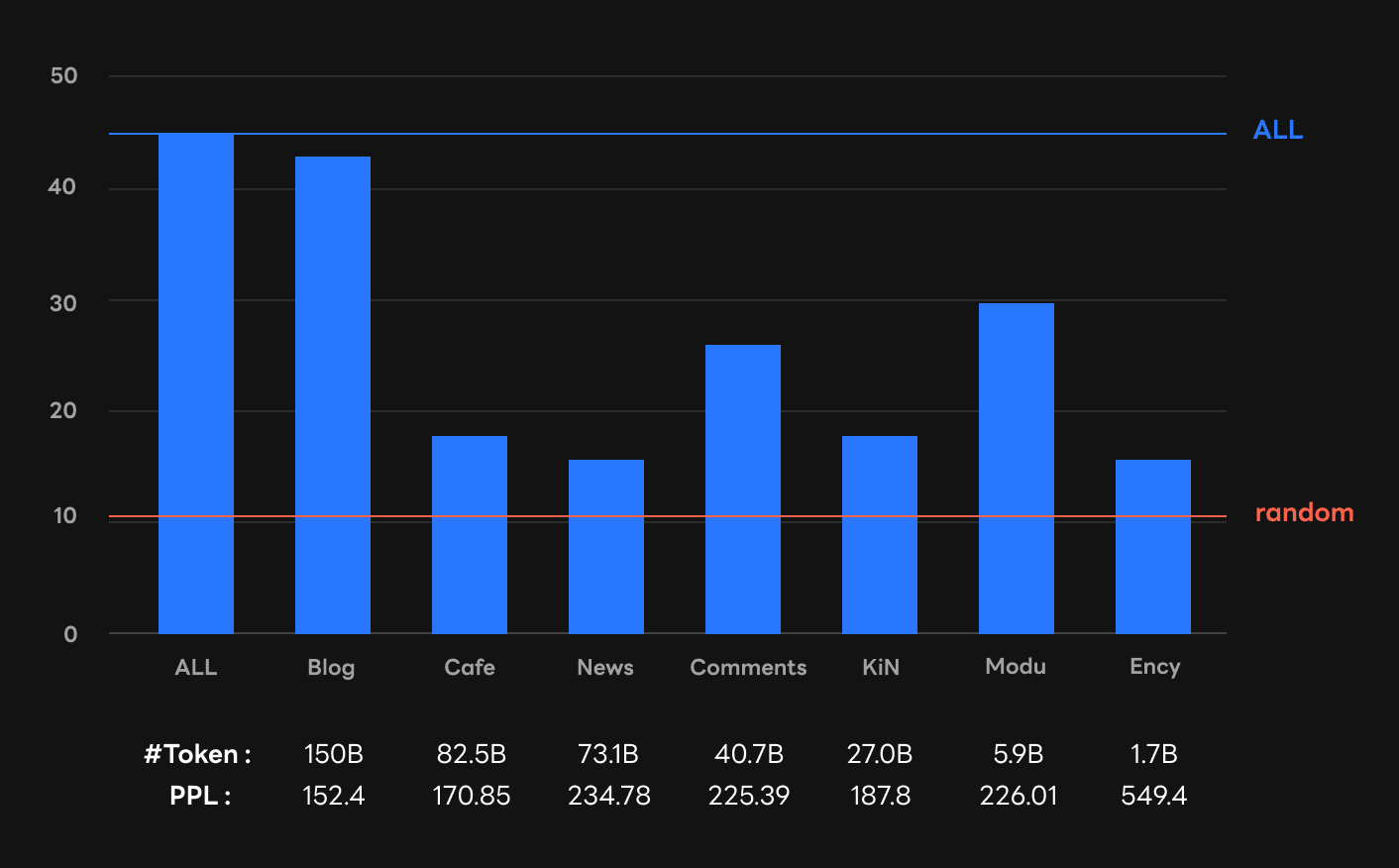
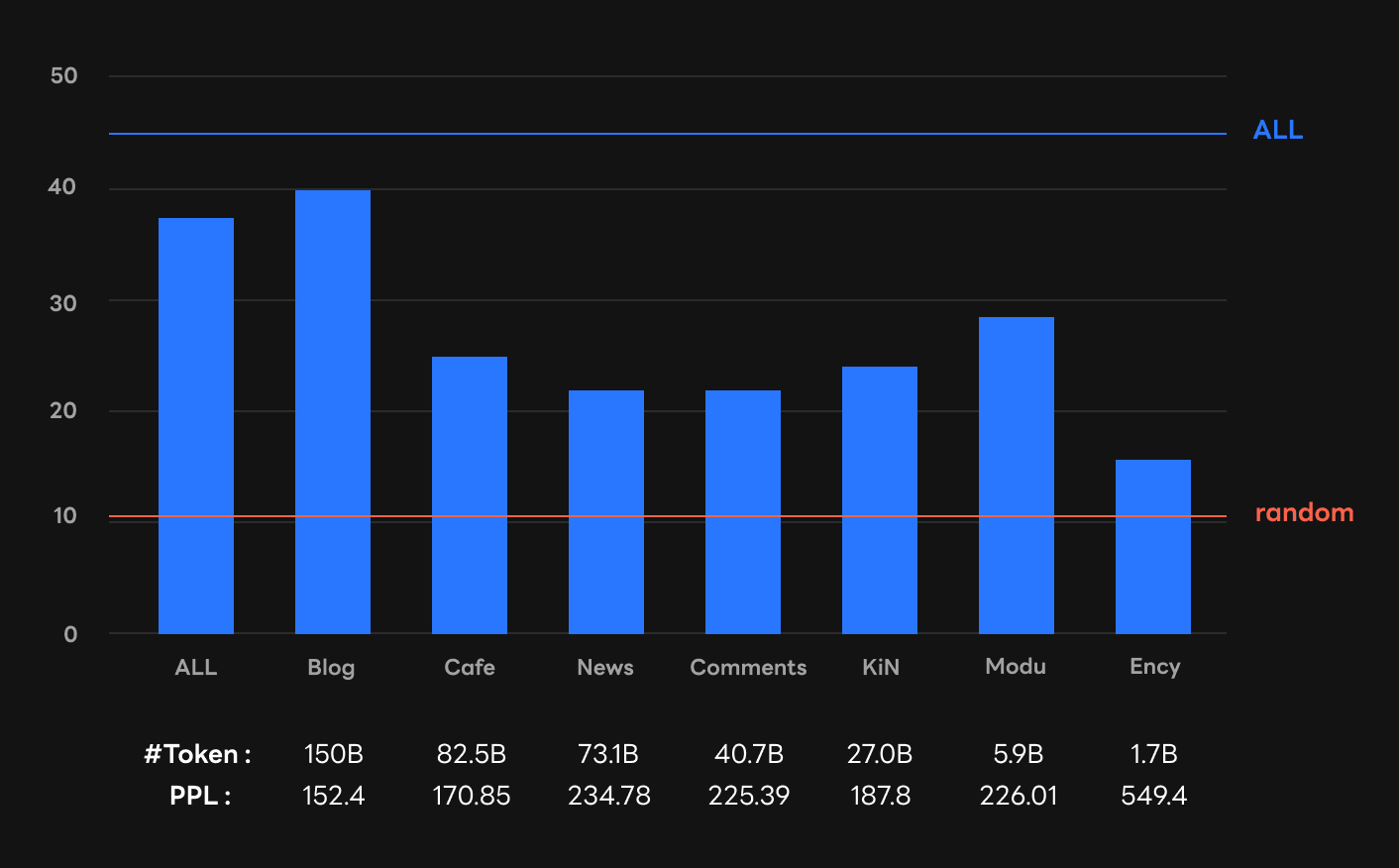
Gopher (Rae et al., arXiv, 2022), a GPT-3 model of Deepmind, determines the ratio between sub-corpora based on the perplexity of the validation corpus. They implicitly claim that this ratio results in better downstream task performance, but do not offer any explicit evidence for this. On the other hand, we are in a position to doubt the strong correlation between perplexity and in-context learning, especially in the few-shot setting.
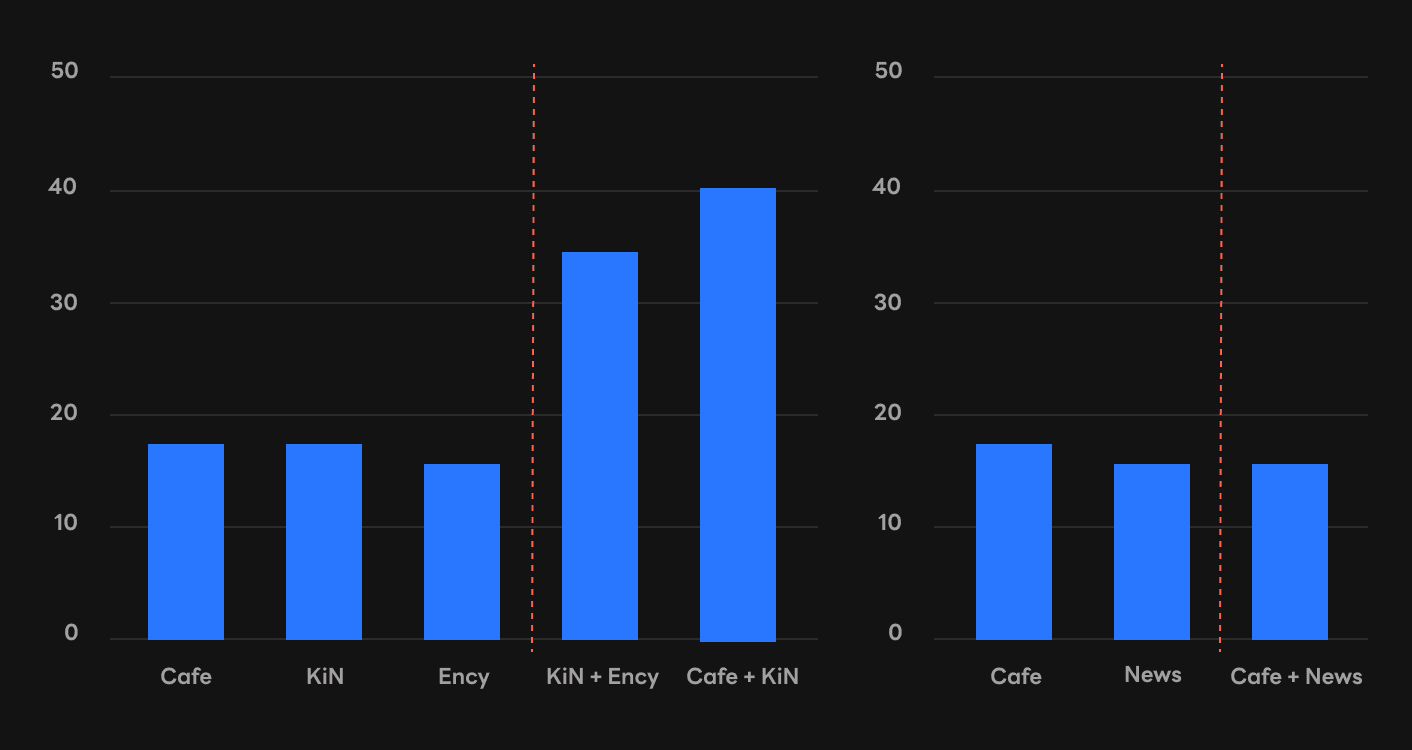
Discovery 2: In-context learning ability can emerge when multiple corpora are combined
We discovered that in-context few-shot learning ability can emerge by combining two corpora, even if each of both corpora cannot provide in-context few-shot learning ability. For example, the KiN+Ency model succeeds in generating in-context learning ability in most tasks, while each of KiN and Ency fails in most tasks. Likewise, the Cafe+KiN model succeeds in generating in-context few-shot learning ability, while each of Cafe and KiN fails in most tasks.
Unlike these positive cases, a counterexample also exists. Not only Cafe and KiN but also the Cafe+KiN model fails to make in-context few-shot learning in most tasks.
Discovery 3: Pre-training with a corpus related to a downstream task does not always guarantee the competitive in-context few-shot learning performance
KLUE-YNAT is one of five downstream tasks used in our research; it is used for news headline classification by topic. We can infer that the in-context learning performance of KLUE-YNAT would increase when the News corpus is trained.
The experimental results are quite interesting, as shown in the graph below. Training the News corpus consistently increases in-context zero-shot learning in KLUE-YNAT. The models with trained corpora including the News corpus even perform better than the model trained using the entire HyperCLOVA corpus.
However, the News corpus does not enhance the in-context few-shot learning of KLUE-YNAT. The performance of KLUE-YNAT is inferior when only trained with the News corpus. Even when training the News corpus with other corpora, the performance for KLUE-YNAT somehow decreased compared to the case without the News corpus.
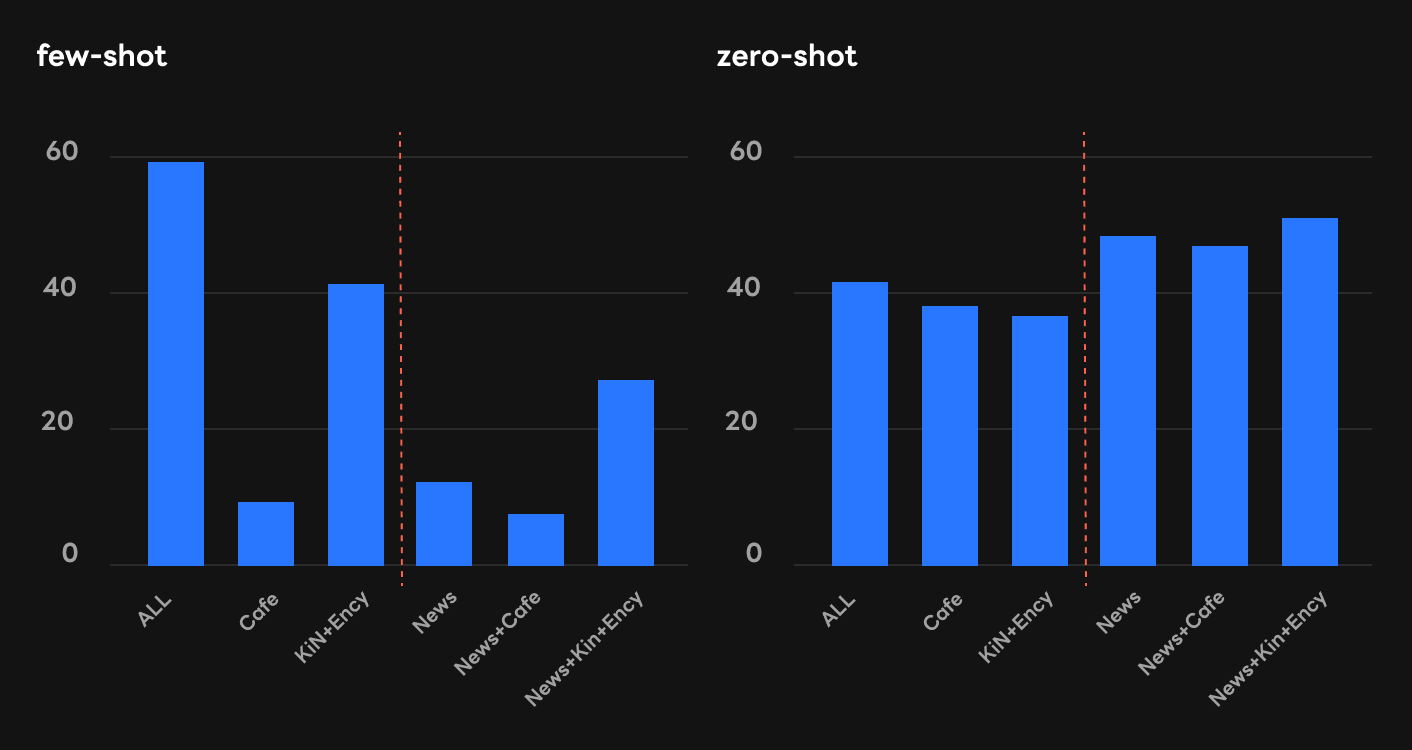
Previous studies, like DAPT (Gururangan et al., ACL, 2020), argue that pre-training with a corpus similar to the downstream task improves the downstream performance. However, these observations are often limited to cases where a pre-trained language model is fine-tuned for the downstream task. Our study shows that a pre-training corpus related to a downstream task does not always guarantee the competitive in-context few-shot learning performance of the downstream task; the trends shown in in-context learning may be quite different from the cases of fine-tuning.
Conclusion
In our research, we've investigated the effects of the source and the size of the training corpus on in-context learning ability, using the HyperCLOVA corpus. Our discoveries conclude that corpus sources play a crucial role in whether or not in-context learning ability will emerge in a large-scale language model. Our study will be presented at the NAACL22 conference as a regular presentation. If you are interested in more discoveries we found, you can read about them in our arXiv paper [arXiv].
Our research is by no means the final say on this topic. For example, our understanding of the causes behind the various interesting discoveries described above are admittedly limited. In addition, our research results were only obtained from the Korean corpus, and further studies on other languages are required. However, analytical research on in-context learning has been conducted, and the corresponding understanding has been deepening (Min et al., arXiv, 2022). We hope our findings contribute to making better in-context learners along with other research.


