
서론: 어떤 말뭉치가 언어 모델의 능력을 끌어올릴까?
GPT-3[Brown et al., NeurIPS, 2020] 이후 하이퍼스케일 언어 모델(Hyperscale Language Model)의 시대가 도래했습니다. 네이버에서도 2021년에 한국어 GPT-3 언어 모델 HyperCLOVA[Kim et al., EMNLP, 2021]를 선보였고[link], 현재 다양한 서비스에 HyperCLOVA의 언어 능력을 적용해 나가고 있습니다.
GPT-3와 같은 하이퍼스케일 언어 모델이 주목받게 된 이유는 인컨텍스트 러닝(in-context learning) 능력 덕분입니다. 인컨텍스트 러닝은 언어 모델이 지시문, 예제 등 입력 문서(context, prompt)의 의미를 파악해 요약, 번역, 대화 등 구체적인 과제(downstream task)를 해결하는 패러다임을 가리킵니다. 파인 튜닝(fine-tuning)[1] 등과는 달리 모델을 업데이트하지 않습니다.
인컨텍스트 러닝은 예제(example) 수에 따라 제로샷(zero-shot) 러닝, 원샷(one-shot) 러닝, 퓨샷(few-shot) 러닝으로 부릅니다. 각각 예제가 0개, 1개, 2개 이상인 경우에 해당합니다. 아래 그림은 예제 수가 하나인 원샷 러닝의 예시입니다. 만일 제로샷 러닝이라면 지시문(아래의 영어를 한국어로 번역합니다) 뒤에 예제가 없고, 퓨샷 러닝이라면 지시문 뒤에 예제가 여러 개 있는 형태입니다.

기존 연구에서는 학습 데이터 관련 인컨텍스트 러닝의 발현 지점에 대한 탐구가 부족했습니다. 예컨대 블로그 말뭉치만 학습하면 인컨텍스트 러닝이 일어나는지, 뉴스 말뭉치를 넣으면 되는 건지 등 발현 지점을 추측할 수밖에 없었습니다. 그런데 학습 데이터는 언어 모델 성능에 가장 큰 영향을 미칠 수 있는 요소이며, 학습 데이터에 대한 연구는 데이터 수집에 드는 비용을 고려해 볼 때 경제성 관점에서 중요한 연구입니다. 이에 우리는 말뭉치 종류별 실험(ablation study)을 수행해 어떠한 말뭉치가 인컨텍스트 러닝에 영향을 미치는지 분석했습니다.
실험에 사용한 말뭉치
우리가 보유한 말뭉치는 크게 7가지로 네이버 블로그(이하 Blog)와 네이버 카페(이하 Cafe), 네이버 뉴스(이하 News), 네이버 댓글(이하 Comments), 네이버 지식인(이하 KiN), 모두의 말뭉치(이하 Modu), 위키피디아(이하 Ency)입니다. Blog와 Cafe, News, KiN은 네이버 서비스로 웹으로 공개된 데이터를 사용했습니다. Comments는 Blog와 Cafe, News의 댓글만 모았습니다. Modu는 국립국어원에서 공개한 말뭉치 중 문어 등 5개 데이터를 모은 것이고, Ency는 공개된 한국어 위키피디아의 데이터를 모은 것입니다.
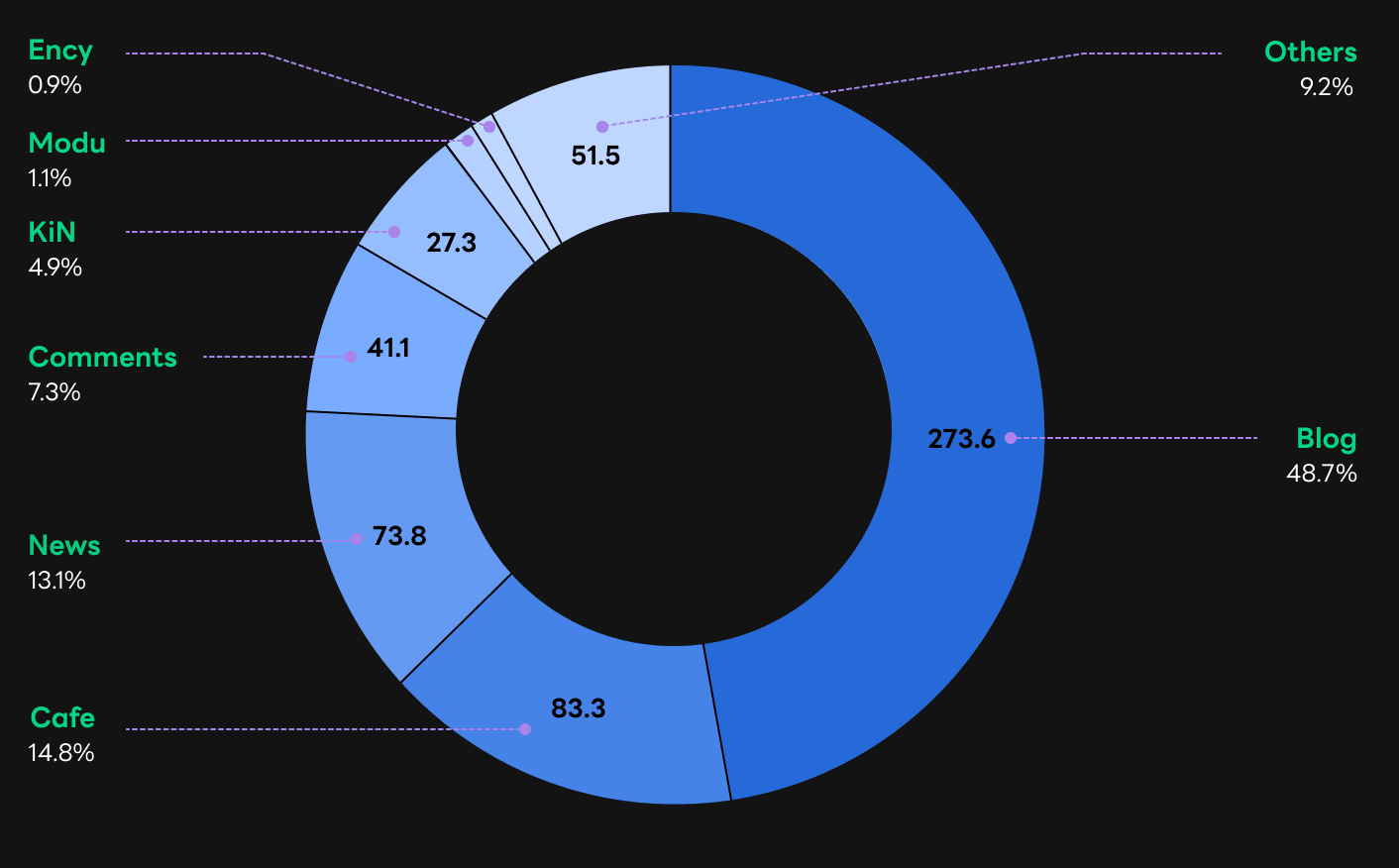
우리는 7가지 각각의 말뭉치를 학습한 모델로 5가지의 한국어 구체적인 과제에 대한 인컨텍스트 러닝 성능을 평가했습니다. 평가 대상 과제는 영화 리뷰 감성 분석(NSMC), 문서 독해(KorQuAD), 한영 번역(AiHub), 영한 번역(AiHub), 뉴스 제목 분류(KLUE-YNAT)입니다.
발견 1: 말뭉치에 따라 성능이 크게 달라지며, PPL이 낮다고 성능이 꼭 좋은 것은 아니다
연구 결과 말뭉치의 종류에 따라 인컨텍스트 제로샷/퓨샷 러닝 성능이 달랐습니다. Blog를 학습한 모델은 인컨텍스트 러닝 성능이 좋아서 7개 전체 말뭉치를 학습한 모델(ALL)의 성능에 근접했지만, Cafe 모델은 상대적으로 성능이 낮았습니다. Blog는 일기(diary)이고 Cafe는 커뮤니티 글(community)로 서로 다르긴 하지만 둘의 특성이 본질적으로 다르다고 말하기는 어려운데요. 따라서 이 둘을 각각 학습한 언어 모델의 능력이 상이한 것은 신기한 일입니다. 한편 News 모델도 대체로 성능이 낮았습니다.
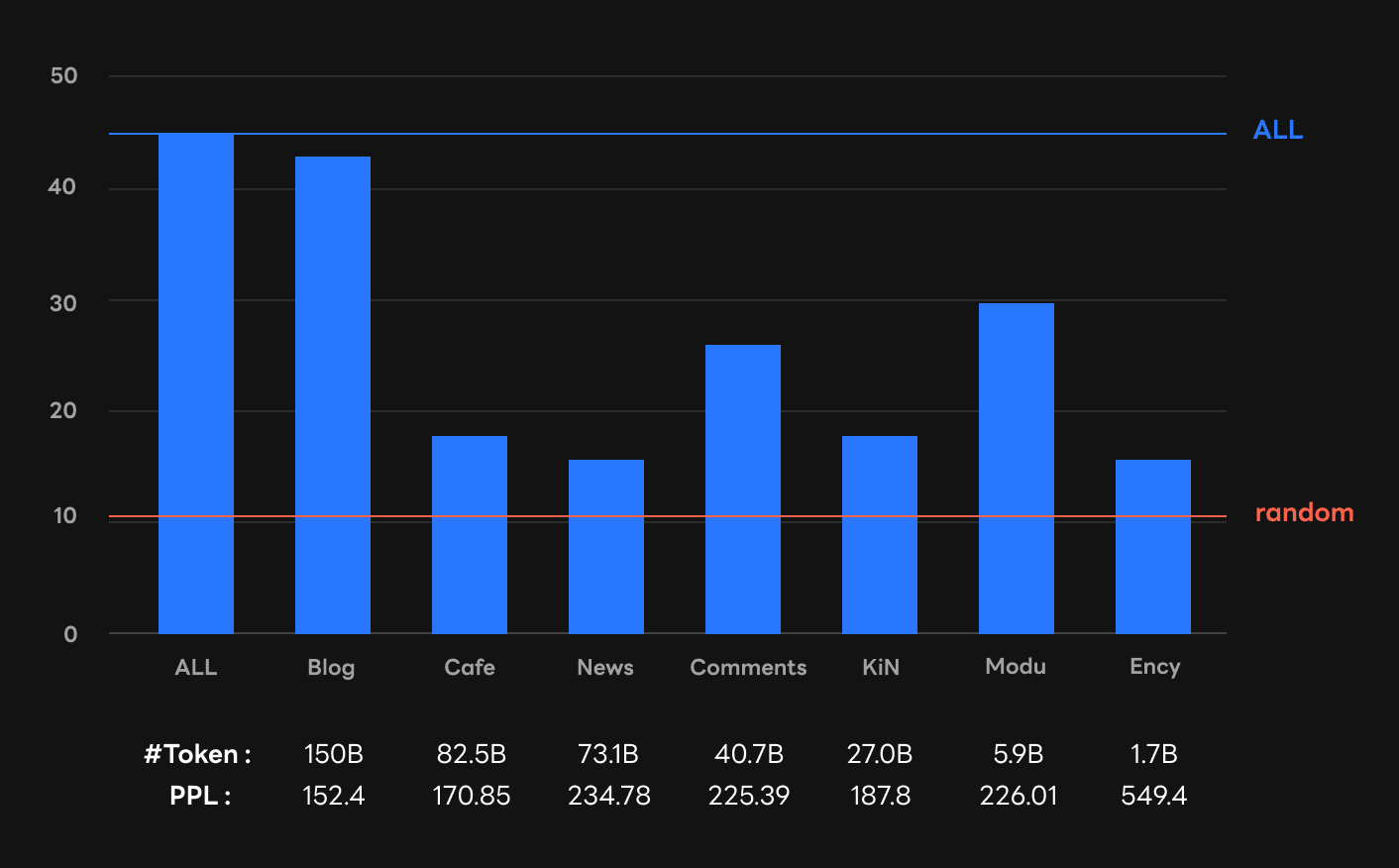
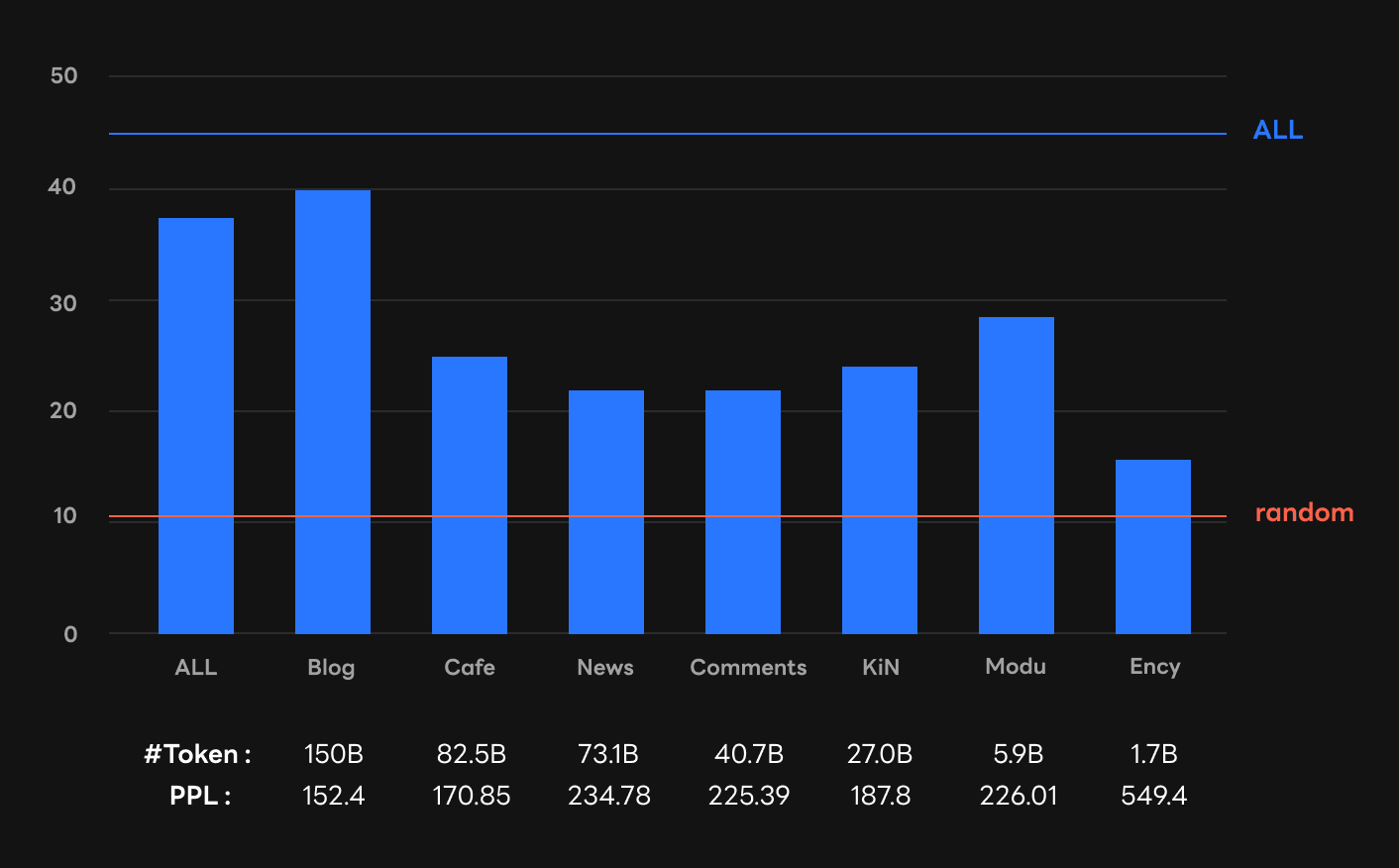
주목할 점은 PPL[2]이 낮다고 인컨텍스트 러닝 성능이 꼭 좋아지는 것은 아니었다는 사실입니다. 위 그림을 보면 Cafe의 평가(validation) 데이터에 대한 PPL(170.85)은 모두 학습한 경우(ALL)를 제외하면 두 번째로 좋은 수준이었습니다. 그러나 인컨텍스트 러닝 성능 순위에서는 제로샷이든 퓨샷이든 그만한 성능을 내지 못했습니다.
이 발견은 기존의 PPL에 대한 관념이 인컨텍스트 러닝에서 항상 들어맞는 것은 아니라는 것을 보여줍니다. 예컨대, Deepmind에서 발표한 하이퍼스케일 언어 모델인 Gopher[Rae et al., arXiv, 2022]의 연구에서는 학습에 쓸 말뭉치의 비율을 정할 때 PPL을 기준으로 삼았습니다. 하지만 이번 연구 결과를 바탕으로 우리는 PPL과 언어 모델의 실제 성능 사이에 괴리가 있다고 주장하려고 합니다. 이를 통해 기존 Gopher 연구와는 다른 방향을 제시하려고 합니다.
발견 2: 말뭉치를 잘 섞으면 없던 능력이 생기기도 한다
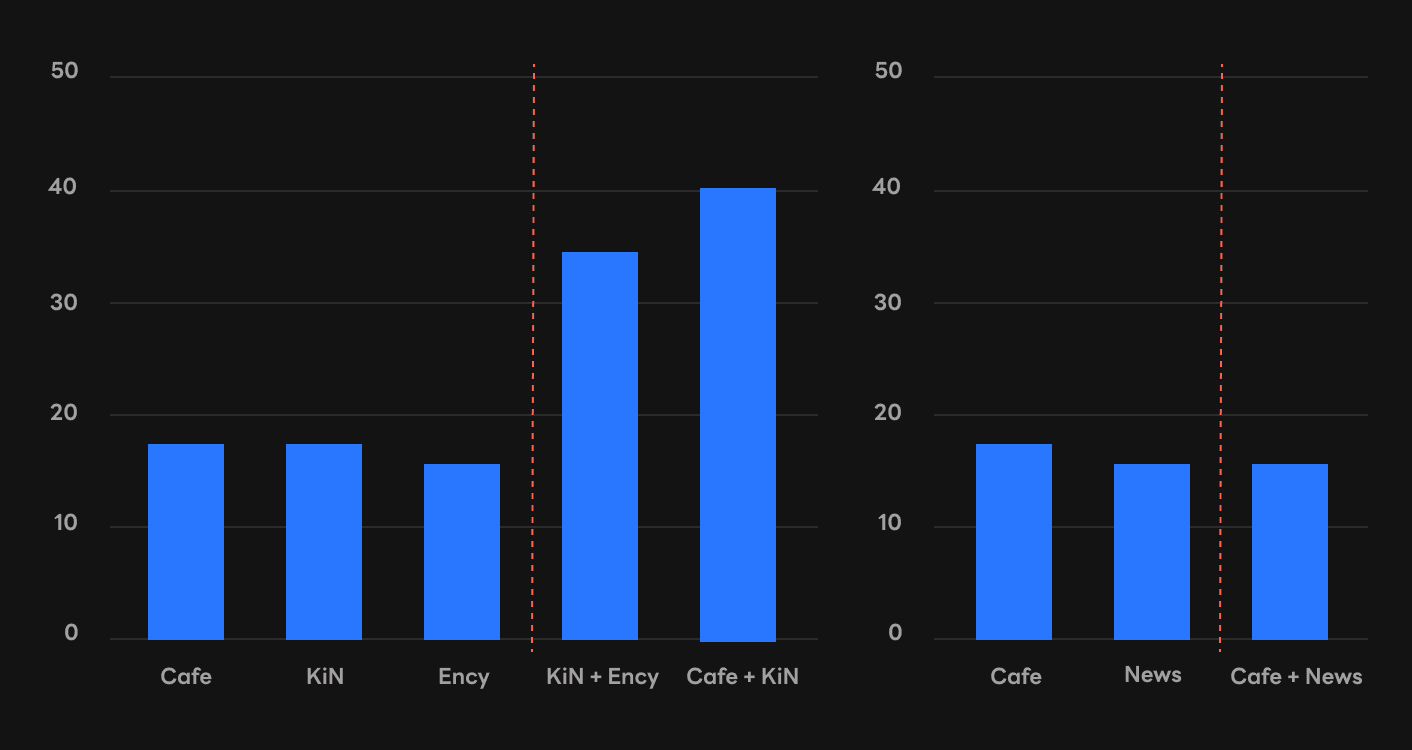
말뭉치를 잘 섞으면 인컨텍스트 러닝 능력이 생기는 경우를 발견했습니다. 예컨대 Cafe와 KiN, Ency를 각각 학습한 경우에는 성능이 잘 나오지 않았지만, KiN+Ency나 Cafe+KiN 모델은 인컨텍스트 러닝 성능이 상대적으로 좋았습니다. 반면 개별 말뭉치는 물론 섞은 말뭉치까지 모두 성능이 안 좋은 사례도 있었습니다. 하단 우측 그래프에서 보시는 바와 같이 Cafe, News, Cafe+News 모델에서는 인컨텍스트 러닝 능력이 창발되지 않았습니다.
발견 3: 과제와 비슷한 말뭉치가 사전 훈련에 포함된다고 해서 높은 성능을 보장하지는 않는다
KLUE-YNAT[3]은 뉴스 제목을 바탕으로 주제를 맞추는 과제입니다. 따라서 뉴스를 많이 배운 모델이 KLUE-YNAT을 잘 할 것이라고 추측해 볼 수 있습니다.
그런데 실험 결과의 양상은 이와는 달랐습니다. 제로샷(하단 우측)에서는 추측했던 대로 News가 포함된 3개 모델의 성능이 전체 말뭉치를 모두 학습한 경우(ALL)보다 좋았지만, 퓨샷(하단 좌측)에서는 News가 포함되면 오히려 모델의 성능이 낮아졌습니다. 심지어 비교적 성능이 좋았던 모델(KiN+Ency)도 News가 포함되면 점수가 떨어지는 경우(KiN+Ency+News)도 나타났습니다.
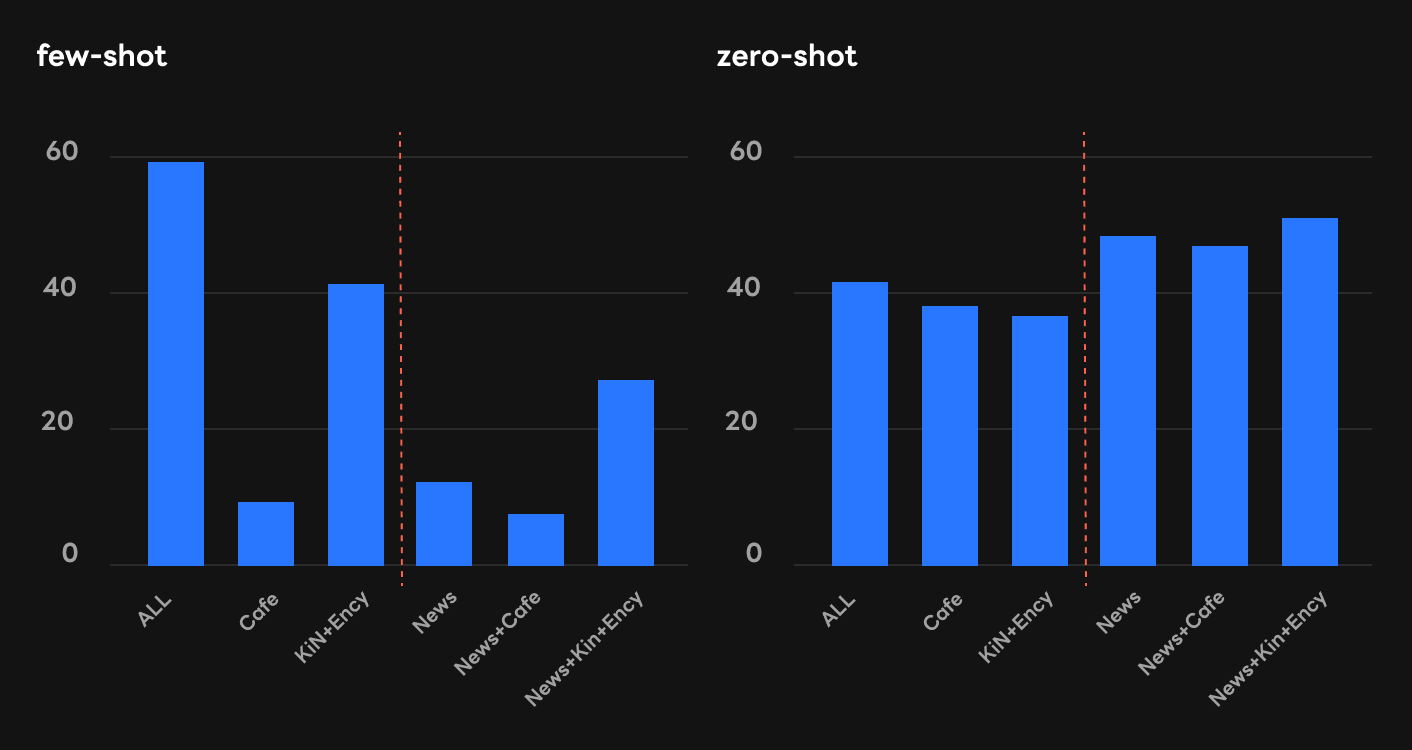
[Gururangan et al., ACL, 2020]과 같은 기존 파인 튜닝 연구들에 따르면 파인 튜닝에서는 사전 훈련 과제(pretraining task)와 구체적인 과제가 비슷할수록 구체적인 과제의 성능이 올라가는 경향이 있었습니다. 하지만 이번 실험 결과를 보면, 인컨텍스트 퓨샷 러닝에서는 구체적인 과제의 성능이 증가하지 않았습니다. 이를 통해 인컨텍스트 퓨샷 러닝과 파인 튜닝은 말뭉치 도메인과 과제의 유사도에 따른 성능 측면에서 서로 다르다는 것을 확인할 수 있었습니다.
결론: 더 깊은 이해를 향한 여정
이번 발견들이 인컨텍스트 러닝의 발현 지점, 더 나아가 하이퍼스케일 언어 모델의 능력을 이해하는 데 마중물이 되기를 바랍니다. 연구 결과는 이번 NAACL22 학회에서 정규(regular) 논문으로 발표할 예정이니 더 자세한 내용은 논문에서 확인해 주시기 바랍니다 [논문 링크].
물론 이번 연구는 한계도 분명합니다. 발견 자체는 의미 있으나 그 원인이 무엇인지에 대한 이해가 부족하며, 실험 또한 한국어 데이터 대상으로만 수행했습니다. 현재 [Min et al., arXiv, 2022]를 비롯한 관련 연구와 함께 제반 이해가 빠르게 깊어지고 있는데요. 후속 연구 결과를 통해 인컨텍스트 러닝을 더 깊이 이해하게 되기를 기대합니다.


