



NSML - 맞춤형 스케줄러 개발기
⚠️ 유의사항: 이 글의 독자는 K8s 스케줄러의 기본적인 구조와 기능을 알고 있다고 가정합니다. 자세한 내용은 NSML 시리즈 3편을 참고하시길 바랍니다. 기본 스케줄러에는 없지만 NSML에서 사용하는 코스케줄링(coscheduling) 플러그인에만 등장하는 개념에 대해서는 추가 설명을 주석으로 달아두었습니다.
본문에 등장하는 내용은 K8s 스케줄러 버전 v1.20.10, K8s 스케줄러 플러그인 버전 v0.20.10 기준입니다. 최신 버전에서는 변경이 있을 수 있습니다.
NSML의 복합적인 스케줄링 환경
NSML은 자원의 효율성을 극대화하고 분산 학습 환경을 지원하기 위해 스케줄링 단계에서 여러 전략을 취하고 있습니다. NSML에서 채택한 스케줄링 정책과 전략은 아래와 같이 네 가지로 요약할 수 있습니다.
첫번째, 인프라 구성을 고려한 구역 스케줄링
NSML은 다수의 구역으로 구성되며, 구역 내부에는 InfiniBand 네트워크가 구축돼 있습니다. InfiniBand를 활용한 노드(NSML node) 간 고속 통신을 보장하기 위해 실험(NSML run) 내 노드는 모두 한 구역에 배치합니다.
두번째, 구역 역할 부여
대규모 실험의 대기 시간을 단축하기 위해 구역별로 배치될 수 있는 실험의 규모를 정해뒀습니다.
세번째, 선점 가능(preemptible) 옵션 지원
NSML은 유휴 자원을 활용해 자원의 가동률을 높일 수 있도록 선점 가능 옵션을 도입했습니다. 가용 자원이 부족해 파드(Pod)를 스케줄링할 수 없는 경우, 스케줄러는 우선순위가 낮은 선점 가능한 파드를 축출해서 보류 중인 파드가 자원을 할당받을 수 있도록 합니다.
네번째, 멀티 노드 동시 실행 보장
원활한 분산 학습 환경을 지원하기 위해 멀티 노드의 동시 실행을 보장합니다. 이를 구현하기 위해 Kubernetes(이하 K8s) 스케줄링 프레임워크의 코스케줄링(coscheduling) 플러그인(kubernetes-sigs에 공개된 스케줄링 프레임워크 구현체 중 하나)을 활용해 갱스케줄링을 도입했습니다.
이와 같은 NSML의 특수한 환경 때문에 복합적인 스케줄링 상황이 다양하게 발생합니다. NSML 스케줄러는 이렇게 복잡한 스케줄링 상황에서도 (1) 사용자에게는 자원을 공정하게 배분하고 (2) 시스템 차원에서는 유휴 자원을 최소화하여 GPU 활용률을 극대화할 수 있도록, 정책과 자원 현황을 폭넓게 고려한 판단을 내리는 것이 아주 중요합니다.
NSML 맞춤형 스케줄러 개발의 필요성
그러나 NSML 스케줄러에 도입한 K8s 스케줄링 프레임워크의 코스케줄링 플러그인으로는 NSML의 특수한 스케줄링 상황을 전부 고려할 수 없었습니다. 따라서 K8s 스케줄러 코드를 깊게 이해하고 검증하는 과정을 반복하며 지금의 NSML 맞춤형 스케줄러를 개발했습니다. 이번 편에서는 NSML을 운영하면서 마주친 몇가지 스케줄링 문제와 함께 NSML 맞춤형 스케줄러를 개선해온 경험들을 소개드리겠습니다.
NSML의 구성 요소와 K8s 리소스
본격적으로 문제를 설명하기에 앞서 NSML의 구성 요소와 이에 매핑되는 K8s의 개념을 짚고 넘어가겠습니다. NSML은 실험(run)과 노드(node)로 구성돼 있으며 하나의 실험은 다수의 노드로 구성할 수 있습니다. 실험은 K8s의 파드그룹(PodGroup)[1] 리소스에 매핑할 수 있습니다. 노드는 K8s의 파드에 1:1로 매핑됩니다. 파드는 파드그룹(즉, 실험)에 속하도록 파드 명세에 파드그룹 레이블을 추가합니다. 코스케줄링 플러그인은 해당 레이블 값으로 파드가 속한 파드그룹을 파악할 수 있습니다.
문제점 1. DefaultPreemption 플러그인에 의한 자원 선점 현상
NSML의 자원은 한정돼 있기 때문에 큰 규모의 실험과 작은 규모의 실험이 경합하는 경우, 큰 규모의 실험이 먼저 생성됐더라도 그에 필요한 자원은 부족하고 작은 규모의 실험에는 충분하다면 작은 규모의 실험이 먼저 배치받도록 스케줄링합니다. 하지만 실제로는 큰 규모와 작은 규모의 실험이 모두 배치받지 못하고 자원을 기다리는 상황이 발생했습니다.
이해를 돕기 위해 아래 그림 1과 같은 예제를 준비했습니다.
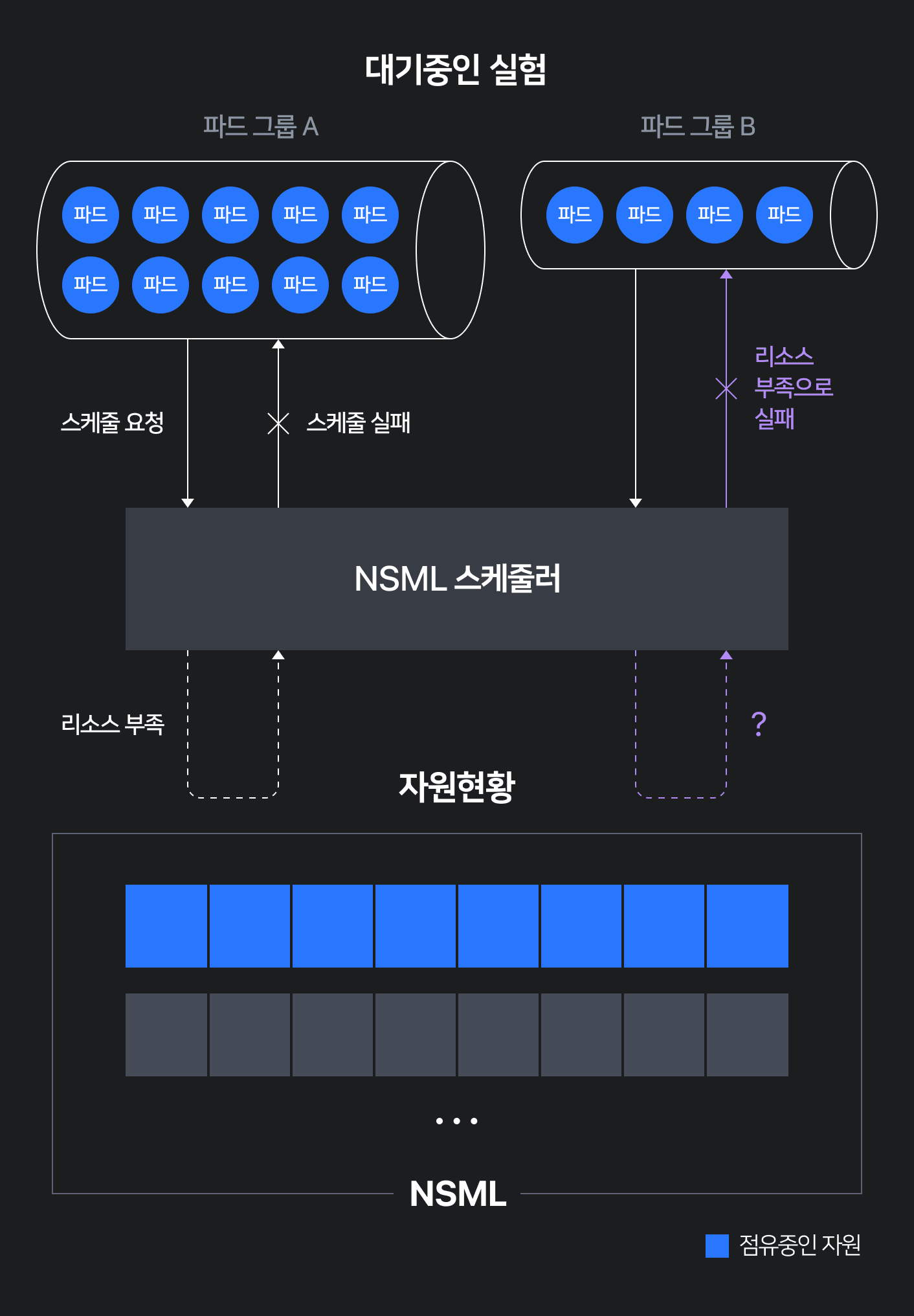
NSML에서 현재 GPU 호스트 1개(GPU 8장)만 가용하고 나머지 GPU는 축출이 불가능한 실험들이 점유 중인 상태라고 가정하겠습니다. 이때 각 GPU 1장을 요구하는 노드 10개로 구성된 실험(파드그룹 A)과 각 GPU 1장을 요구하는 노드 4개로 구성된 실험(파드그룹 B)가 순차적으로 생성되었다고 합시다. K8s 스케줄러는 파드 단위로 스케줄링하기 때문에 노드 1개에 대응하는 파드를 우선순위에 따라 스케줄링합니다. 파드그룹 A의 파드 10개를 동시에 배치할 자원이 부족하므로 코스케줄링 플러그인에서 파드그룹 A 전체가 실패하고, 파드그룹 A 내 파드는 스케줄링 큐에 다시 추가됩니다. 파드그룹 A가 스케줄링 큐에 들어가서 대기하고 있을 때 파드그룹 B 파드들의 스케줄링 차례가 됩니다. 하지만 가용 GPU 7장이 존재함에도 불구하고 스케줄러에서는 이상하게도 자원이 부족하다고 판단하여 파드그룹 B는 자원을 할당받지 못합니다. 결국 GPU 4장 규모의 실험과 10장 규모의 실험 모두 자원을 할당받지 못하는 것입니다.
가용 GPU가 충분함에도 불구하고 자원이 부족하다고 판단하는 것은 의도치 않은 현상입니다. 정상적으로는 10개의 파드를 배치할 자원이 부족하므로 파드그룹 A는 스케줄링이 조기 종료되고 다음 4개짜리 파드그룹 B가 스케줄링돼야 합니다. 원활한 스케줄링을 막는 이 문제는 NSML과 같이 다수의 사용자가 경합하는 상황이 빈번한 시스템에서는 자원이 활용되지 못하는 문제가 더욱 심각해지기 때문에 시급하게 처리해야 했습니다.
Kubernetes 스케줄링 흐름
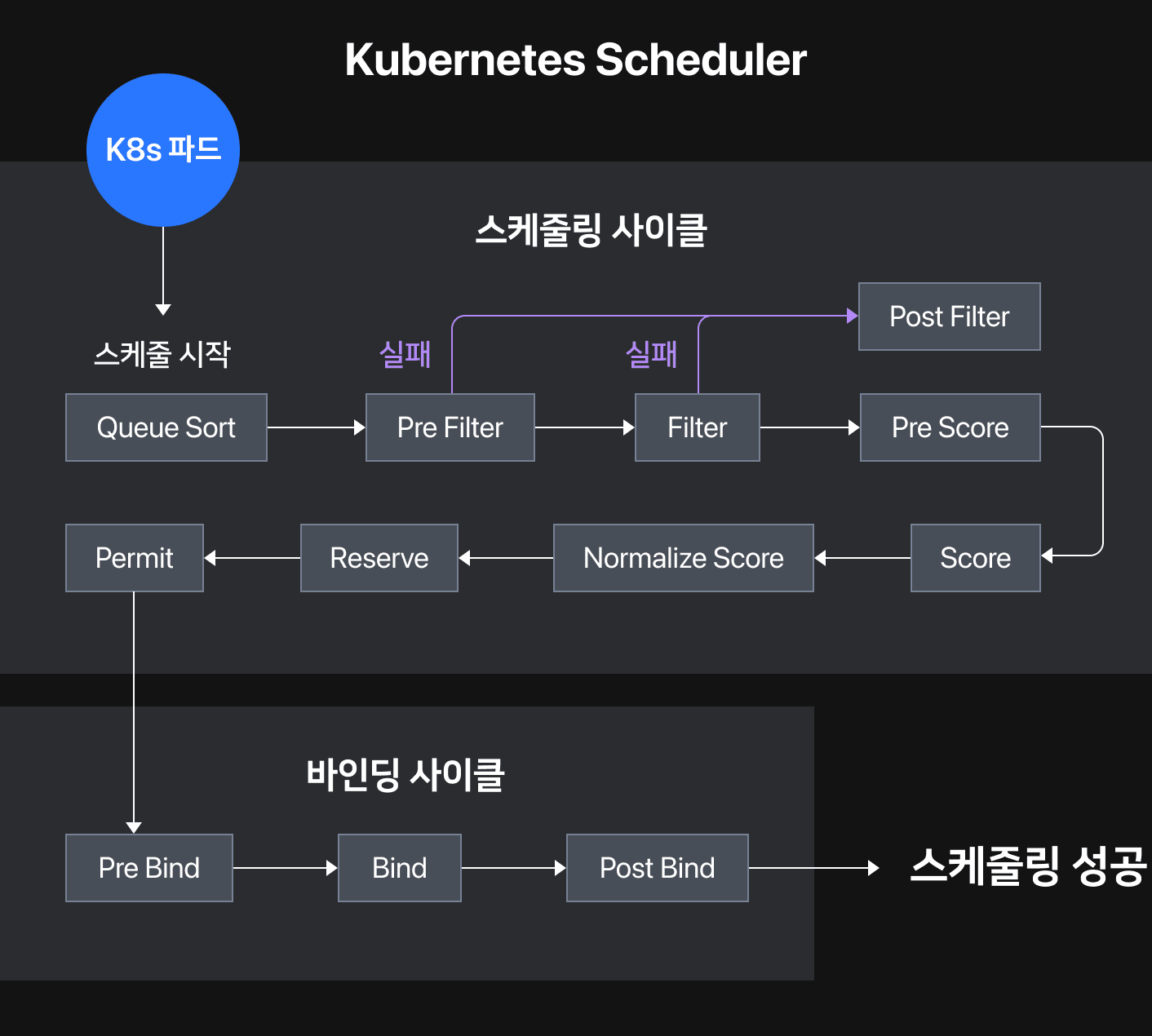
원인을 설명드리기에 앞서 K8s 스케줄러의 동작 방식을 살펴보도록 하겠습니다.
K8s 스케줄러는 여러가지 기능을 플러그인 형태로 구현할 수 있도록 스케줄링 프레임워크를 제공하며, 각 단계를 익스텐션 포인트(extension point)로 노출합니다. 익스텐션 포인트 별로 제공되는 인터페이스를 구현하여 원하는 기능을 구현할 수 있는데, 실제로 "파드의 우선순위에 기반한 축출 기능" 등 기본적으로 제공되는 여러가지 스케줄러 기능들도 스케줄링 프레임워크를 기반으로 구현되어 있습니다.
아래에서 설명드릴 문제의 원인을 이해하기 위해서는, 그림 2에서 보이는 여러 가지 스케줄러 단계 중 PreFilter, Filter, PostFilter를 이해할 필요가 있습니다.
- PreFilter 단계는 Filter 단계로 통과시키기 이전에 파드 또는 K8s 클러스터가 충족해야 하는 조건을 미리 확인합니다.
- Filter 단계에서는 파드를 배치할 수 없는 호스트를 후보 호스트 목록에서 제거합니다.
- PostFilter 단계는 PreFilter 혹은 Filter 단계를 무사히 통과하지 못한 경우에 실행됩니다.
- PostFilter 단계의 대표적인 플러그인은 DefaultPreemption 플러그인인데요. DefaultPreemption 플러그인은 파드에 할당할 자원이 부족한 경우, 우선순위가 낮은 파드를 축출(Preemption, 선점)하는 로직이 실행됩니다.
문제의 원인
앞서 설명한 자원이 충분한데도 자원 할당에 실패하는 문제의 원인은 PostFilter 단계에 기본적으로 등록돼 있는 DefaultPreemption 플러그인에서 실행되는 축출 로직때문입니다. PostFilter 단계에서 실행되는 DefaultPreemption 플러그인의 축출 로직에선 Filter(또는 PreFilter) 단계에서 실패한 파드가 배정 가능한 호스트를 찾고, 호스트 내 선점할 수 있는 다른 파드가 있다면 축출합니다.
K8s 스케줄러에서는 여러 플러그인을 호출하며 스케줄링 로직을 진행합니다. 이 로직에서는 호스트의 가용 자원 등을 확인하기 위해 호스트 정보를 담아두고 사용하는데요. 이를 편의상 코드에서 사용하는 용어인 NodeInfo라고 부르겠습니다. 파드가 축출 로직을 거치고 나면 파드가 실제로 배정되지 않았더라도 NodeInfo에 파드가 요청한 자원을 기록해 둡니다. 스케줄링 로직에서는 호스트의 가용 자원을 계산할 때 바로 이 NodeInfo에 기록된 요청 자원을 합산합니다. "배정될 수도" 있는 파드가 요구하는 자원을 잠시 맡아두는 개념입니다. 코드에서는 "배정될 수도" 있는 파드를 Nominated Pod 로 부릅니다.
자세하게 살펴보면, Filter 단계가 실행될때 호출되는 PodPassesFiltersOnNode 라는 메서드가 있는데요.[2] 메서드 내에서 호출되는 addNominatedPods 로직 내부에서 어떤 호스트에 "배정될 수도" 있는 파드라고 인지된 Nominated Pod의 자원의 양까지 NodeInfo에 합산됩니다.
// PodPassesFiltersOnNode checks whether a node given by NodeInfo satisfies the
// filter plugins.
// This function is called from two different places: Schedule and Preempt.
// When it is called from Schedule, we want to test whether the pod is
// schedulable on the node with all the existing pods on the node plus higher
// and equal priority pods nominated to run on the node.
// When it is called from Preempt, we should remove the victims of preemption
// and add the nominated pods. Removal of the victims is done by
// SelectVictimsOnNode(). Preempt removes victims from PreFilter state and
// NodeInfo before calling this function.
// TODO: move this out so that plugins don't need to depend on <core> pkg.
func PodPassesFiltersOnNode(
ctx context.Context,
ph framework.PreemptHandle,
state *framework.CycleState,
pod *v1.Pod,
info *framework.NodeInfo,
) (bool, *framework.Status, error) {
var status *framework.Status
// 생략
for i := 0; i < 2; i++ {
stateToUse := state
nodeInfoToUse := info
if i == 0 {
var err error
podsAdded, stateToUse, nodeInfoToUse, err = addNominatedPods(ctx, f, pod, state, info)
if err != nil {
return false, nil, err
}
} else if !podsAdded || !status.IsSuccess() {
break
}
// `NodeInfo`를 갱신한 후에 Filter 플러그인을 실행한다.
statusMap := ph.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
status = statusMap.Merge()
if !status.IsSuccess() && !status.IsUnschedulable() {
return false, status, status.AsError()
}
}
return status.IsSuccess(), status, nil
}8장의 GPU가 있는 상태에서 각 GPU 1장을 요구하는 파드 10개로 이루어진 파드그룹 (총 GPU 10장 사용)을 생성하면, 코스케줄링 플러그인에서는 GPU가 부족하므로 파드를 모두 스케줄링하지 않습니다. 하지만 GPU 8장은 가용한 상태이므로 10개 파드 중 8개의 파드는 축출 로직에 따라서 Nominated Pod, 즉 "배정될 수도" 있는 파드로 인식됩니다. 이후 스케줄링 로직에서는 Nominated Pod로 인식된 8개의 파드의 요청 자원을 NodeInfo 에서는 사용 중인 자원으로 보고 가용 GPU가 없다고 판단합니다. 결국 GPU 4장을 사용하는 파드그룹 B는 실제로는 GPU가 충분함에도 불구하고 자원을 할당받지 못합니다.
해결 방안
축출 로직 때문에 발생하는 이슈이기 때문에 축출이 실행하지 않도록 DefaultPreemption 플러그인을 비활성화하면 문제가 발생하지 않습니다. 하지만 선점 가능(preemptible) 옵션을 제공하기 위해서는 축출 로직이 필요했기 때문에 비활성화하지 않고 스케줄러 코드를 직접 수정하기로 결정했습니다.
PostFilter 단계는 PreFilter 혹은 Filter 단계에서 실패한 경우에만 진입하고 실패된 단계에서 반환한 에러에 따라 다르게 작동합니다. 코스케줄링의 PreFilter에서는 모든 에러 상황에서 Unschedulable 에러를 반환합니다. 하지만 K8s에 정의된 UnschedulableAndUnresolvable 에러를 반환하면 축출 로직이 실행되지 않는다는 것을 발견하였습니다.
// UnschedulableAndUnresolvable is used when a plugin finds a pod unschedulable and
// preemption would not change anything. Plugins should return Unschedulable if it is possible
// that the pod can get scheduled with preemption.
// The accompanying status message should explain why the pod is unschedulable.
UnschedulableAndUnresolvable
스케줄링 사이클의 PreFilter 단계에서는 Filter 단계로 넘어가기 이전 검토 사항을 확인합니다. 예컨데 코스케줄링 플러그인의 Prefilter 단계에선 파드그룹내 파드가 모두 생성된 상태인지, 파드그룹이 요청하는 자원의 합이 실제 K8s 클러스터의 가용 자원보다 작아 배치 가능한 상태인지 등을 검토합니다. 검토 사항을 만족하지 못해 스케줄링에 실패하면, 호스트의 상태를 저장하는 NodeToStatusMap에 K8s 클러스터 전체 호스트를 대상으로 Unschedulable 혹은 UnschedulableAndUnresolvable을 기록해 둡니다.
PreFilter 단계를 통과한 후 Filter 단계에서는 배정 가능한 K8s 호스트 후보를 찾습니다. 이때 어떤 호스트가 배정 가능하지 않아 실패하면, NodeToStatusMap에 각 호스트의 정보를 Unschedulable 혹은 UnschedulableAndUnresolvable을 기록해 둡니다.
// schedule 메인 코드에서 PreFilter 단계
//
// 1. NodeToStatusMap 변수를 정의한다.
filteredNodesStatuses := make(framework.NodeToStatusMap)
// 2. PreFilter Plugin을 실행시킨다.
s := fwk.RunPreFilterPlugins(ctx, state, pod)
if !s.IsSuccess() {
if !s.IsUnschedulable() {
return nil, nil, s.AsError()
}
// All nodes will have the same status. Some non trivial refactoring is
// needed to avoid this copy.
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, nil, err
}
// 3. 모든 호스트에 대해 PreFilter 플러그인이 반환한 에러를 기록한다.
for _, n := range allNodes {
filteredNodesStatuses[n.Node().Name] = s
}
return nil, filteredNodesStatuses, nil
}PostFilter에서 실행되는 DefaultPreemiption 플러그인의 축출 로직에서도 NodeToStatusMap을 참조해 배정 가능한 K8s 호스트 후보를 찾는데요. 이때 UnschedulableAndUnresolvable 상태로 표기된 호스트는 호스트 후보에서 바로 제외합니다.
// nodesWherePreemptionMightHelp returns a list of nodes with failed predicates
// that may be satisfied by removing pods from the node.
func nodesWherePreemptionMightHelp(nodes []*framework.NodeInfo, m framework.NodeToStatusMap) ([]*framework.NodeInfo, framework.NodeToStatusMap) {
var potentialNodes []*framework.NodeInfo
nodeStatuses := make(framework.NodeToStatusMap)
for _, node := range nodes {
name := node.Node().Name
// We rely on the status by each plugin - 'Unschedulable' or 'UnschedulableAndUnresolvable'
// to determine whether preemption may help or not on the node.
if m[name].Code() == framework.UnschedulableAndUnresolvable {
nodeStatuses[node.Node().Name] = framework.NewStatus(framework.UnschedulableAndUnresolvable, "Preemption is not helpful for scheduling")
continue
}
potentialNodes = append(potentialNodes, node)
}
return potentialNodes, nodeStatuses
}코스케줄링 플러그인의 Prefilter에서 UnschedulableAndUnresolvable으로 반환하도록 수정한다면, 모든 호스트가 UnschedulableAndUnresolvable 으로 맵핑되어 DefaultPreemption 플러그인에서 배정 가능한 호스트를 하나도 찾을 수 없습니다. 따라서 코스케줄링 플러그인에 의해 의도적으로 실패한 파드에 대해서는 축출 로직이 작동하지 않습니다.
다행히, 이 변경이 선점 가능 실험을 축출하는 NSML 스케줄러의 동작에는 영향을 주지는 않습니다. 선점 가능 실험이 점유하고 있는 자원은 가용한 상태로 인식하기 때문에 선점 가능 실험을 축출하여 파드그룹이 배치될 수 있는 상황이라면, 자원이 가용하다고 판단하여 PreFilter 단계를 통과합니다. 이후 Filter 단계에서 "자원 부족"으로 실패하여 Unschedulable에러를 반환하고, DefaultPreemption 플러그인의 축출 로직이 정상적으로 실행됩니다.
결론
문제 해결 과정을 요약하자면 아래와 같습니다.
- DefaultPreemption 플러그인으로 인해 스케줄링에 실패한 파드가 의도치 않게 자원을 예약하는 현상이 발생했습니다. 이에 따라 당장 스케줄링 가능한 파드그룹도 자원을 배정받지 못하는 문제가 확인되었습니다.
- 코스케줄링 플러그인의 Prefilter 단계에서는 파드그룹 단위로 자원이 가용한 상태인지 확인합니다. 단, 선점 가능 실험이 점유하고 있는 자원은 가용한 상태로 인식하므로 축출하여 자원 배치가 가능하다면 PreFilter 단계를 통과합니다.
- 이때, 축출하여 자원을 배치할 수 있는 상황이 아니라면
UnschedulableAndUnresolvable을 반환하여 DefaultPreemption 플러그인의 축출 로직이 실행되지 않도록 수정하였습니다. - 파드그룹에서 요구하는 전체 자리가 부족한 경우에도 자리를 예약하는 바람에 발생했던 문제를 해결해서 당장 스케줄링이 가능한 파드그룹은 자원을 기다리지 않고 할당받을 수 있게 되었습니다.
문제점 2. 스케줄링 불가인 호스트를 가용한 자원으로 잘못 인식하여 선점 가능 실험을 축출하는 현상
NSML은 대규모 GPU 클러스터를 운영하고 있기 때문에 일부 GPU 호스트의 펌웨어를 업데이트해야 하거나 점검해야 하는 상황이 종종 발생합니다. 이런 경우에는 노드를 더 이상 해당 호스트에 배치할 수 없도록 코돈 처리를 하는데요. 코돈된 호스트에는 K8s의 Toleration 정보가 설정되어 K8s 파드가 더 이상 해당 호스트에 배정받지 않게 됩니다.
문제를 설명하기 위해 NSML에 총 GPU 64장(GPU 8장 × 8 호스트)을 배치할 수 있는 구역이 있고, 구역 안에 이미 실행 중인 선점 가능(preemptible) 실험과 점검 중인 호스트 1개가 있다고 가정하겠습니다. 64장 규모의 실험(GPU 8장 파드가 배치될 8개 GPU 호스트 필요)을 새로 배치하고 싶을 경우, 가용 자원이 부족합니다. 선점 가능 실험은 가용한 자원으로 인식되므로 점검 중인 호스트를 제외하면 총 GPU 56장이 가용한 상태입니다. 선점 가능 실험을 축출한다고 하더라도 자원이 부족한 것입니다. 배치할 총 자원이 부족하기 때문에 아무 일도 일어나지 않아야 하지만 이때, 실행 중이던 선점 가능 실험이 대기 중인 64장 실험때문에 축출당하는 문제가 발생했습니다.
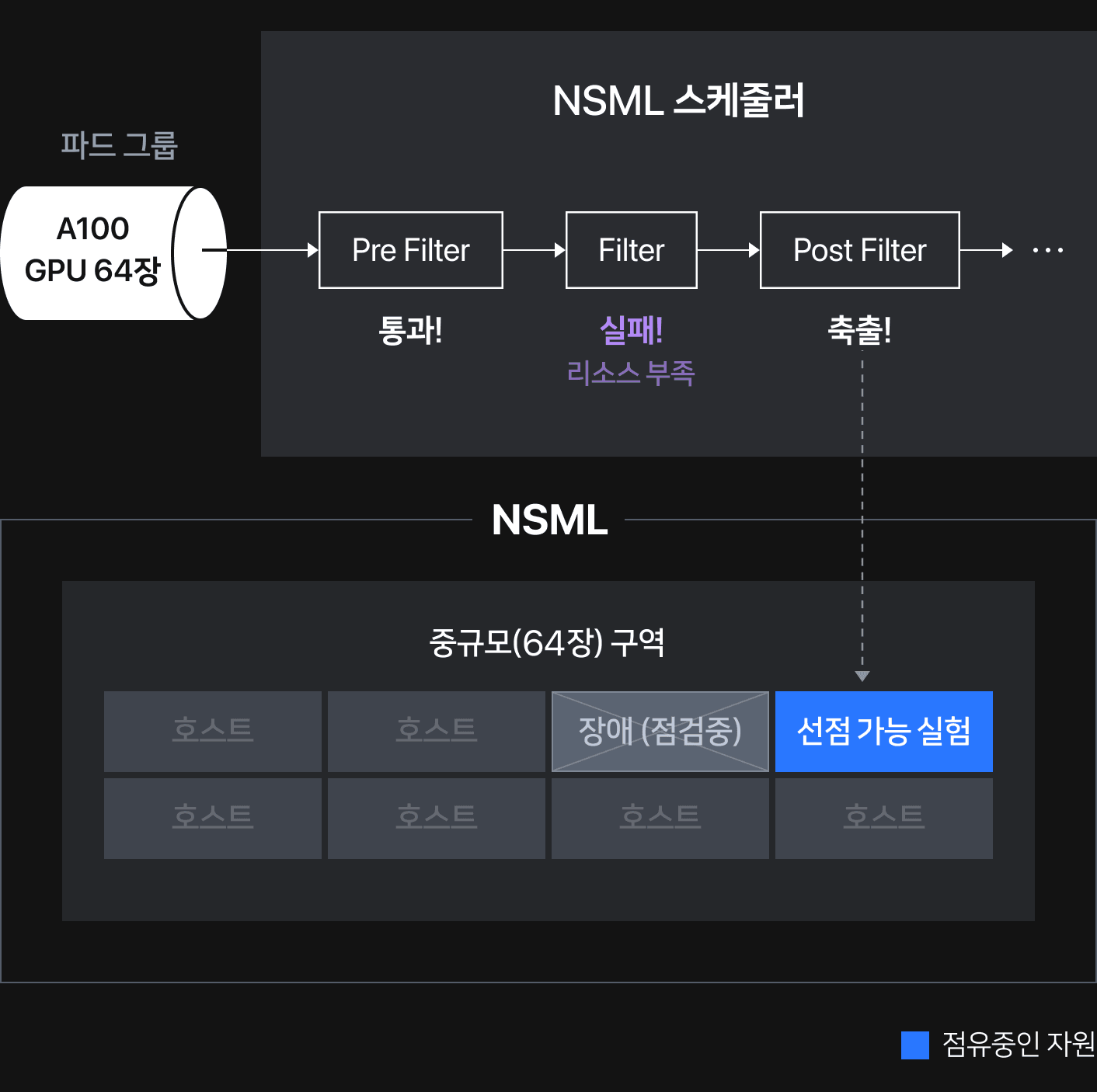
어차피 64장이 배정받을 자원이 부족하기 때문에 선점 가능 실험을 축출시키지 않아야 하는 것이 합리적인 스케줄링 과정일 것입니다. 코드를 살펴보며 이런 상황이 발생할 수 있는 이유를 역으로 추적했습니다. PreFilter단계의 코스케줄링 플러그인에서 64장 파드그룹은 "전체 자원 부족"으로 UnschedulableAndUnresolvable 에러를 반환해 실패했어야 합니다. 앞서 [문제점 1]에서 설명한 것처럼 이 에러 덕분에 축출 로직을 실행하지 않아야 하지만, 축출이 발생했다는 결과를 통해 PreFilter 단계를 통과해 Filter 단계에서 실패했음을 짐작할 수 있었습니다. Filter의 경우 K8s의 기본 스케줄러 로직을 타기 때문에 파드 그룹 단위로 자원 가용 여부를 판단하지 않고, 파드 단위로 이루어집니다. 선점 가능 실험이 점유된 자원 포함, 코돈된 호스트 자원을 제외하면 가용 자원은 GPU 56장이므로 파드그룹 전체에 대한 자원은 부족하나 GPU 8장을 요구하는 파드에는 자원이 충분하다고 판단하여 가용한 호스트에 대해 Unschedulable 에러를 반환하고 그 결과 애꿎은 선점 가능 실험이 축출당하는 것입니다.
그렇다면 어떻게 PreFilter 단계를 통과했을까요? 답은 코스케줄링 플러그인에서 가용 자원을 계산하는 CheckClusterResource 메서드 내부에 있었습니다. 이 메서드는 K8s의 호스트 리스트를 인자로 받아, 해당 호스트에 적힌 자원와 파드그룹에서 요구하는 자원 양의 차이를 구합니다. 차이가 0보다 크면 PreFilter를 통과시키고, 차이가 0 이하이면 자원이 부족하다는 의미로 에러를 반환합니다. 결국 이 문제가 발생한 근본적인 원인은 코돈된 호스트는 현재 가용할 수 없는 자원임에도 전체 자원 양에 포함시켰기 때문입니다. 이는 명백한 스케줄러의 오판입니다.
NSML에서는 합리적인 스케줄링을 할 수 있도록 코돈된 호스트의 자원은 가용 자원으로 판단하지 않게 아래와 같이 코드를 수정했습니다.
// CheckClusterResource checks if resource capacity of the cluster can satisfy <resourceRequest>.
// It returns an error detailing the resource gap if not satisfied; otherwise returns nil.
func CheckClusterResource(nodeList []*framework.NodeInfo, resourceRequest corev1.ResourceList, desiredPodGroupName, topologyKey string) error {
resourceRequestByTopologyKey := make(map[string]corev1.ResourceList)
for _, info := range nodeList {
if info == nil || info.Node() == nil || (topologyKey != "" && info.Node().Labels[topologyKey] == "") {
continue
}
// 해당 호스트(K8s Node)가 코돈되어 있다면 Unschedulable=true로 설정됩니다. 이 경우, 호스트의 자원은 가용한 자원 목록에 포함하지 않도록 스킵합니다.
+ if info.Node().Spec.Unschedulable {
+ klog.V(4).Infof("Node %v is unschedulable since cordoned", info.Node().Name)
+ continue
+ }
// 생략위와 같이 수정해서 자리가 부족한데도 선점 가능 실험을 축출하는 문제를 막을 수 있었고, 운영 측면에서도 안심하고 호스트를 코돈해 점검 의뢰할 수 있게 되었습니다.
마무리
NSML은 K8s의 스케줄러에서 발생하는 치명적인 문제들을 극복하기 위해 "NSML 맞춤형 스케줄러"를 개발해서 운영하고 있습니다. 이를 통해 선점 가능 실험이 의도치 않게 축출당하거나 자원이 있는데도 실험이 계속 배치받지 못하는 상황이 발생하는 것을 막고, NSML에서 발생하는 복합적인 스케줄링 상황 속에서도 합리적인 판단으로 자원을 배분하고 있습니다.



